
Which Output Data Ports Should You Consider?
"It depends"—but not entirely. Create smart output data ports for seamless data flow.

🍪 Before diving in, we have a fresh treat for You!
The latest State of Data Products is now LIVE!
The State of Data Products is a quarterly release covering the evolving journey of data products in the industry, reporting and documenting milestone events, discussions, and significant trends (like, say, mass adoption).
Now, with the Special Edition: 2024 Roundup, we’re taking it further, diving deep into what shaped the data product landscape in the milestone year of 2024. This edition delivers the inside scoop on Data Products and covers the entire evolution journey across the four quarters! A true yearly roundup. Fresh insights from industry leaders who are redefining what’s possible with data.

Now, back to this week’s prime story!
This piece is a community contribution from Francesco de Cassai, an expert craftsman of efficient Data Architectures using various patterns. He embraces new patterns, such as Data Products, Data Mesh, and Fabric, to capitalise on data value more effectively. We highly appreciate his contribution and readiness to share his knowledge with MD101.
We actively collaborate with data experts to bring the best resources to a 9000+ strong community of data practitioners. If you have something to say on Modern Data practices & innovations, feel free to reach out!
🫴🏻 Share your ideas and work: community@moderndata101.com
*Note: Opinions expressed in contributions are not our own and are only curated by us for broader access and discussion. All submissions are vetted for quality & relevance. We keep it information-first and do not support any promotions, paid or otherwise!
TOC
Introduction
Understanding the Role of Output Ports
Identifying the data flows
Mapping to Technological Patterns
Practical Implementation
Key Considerations & Takeaways
Within the paradigm of data as a product, the concept of ports is one of the most defining aspects. Among these, data plane ports (input and output ports) are usually the first to be addressed due to their immediate comprehensibility.
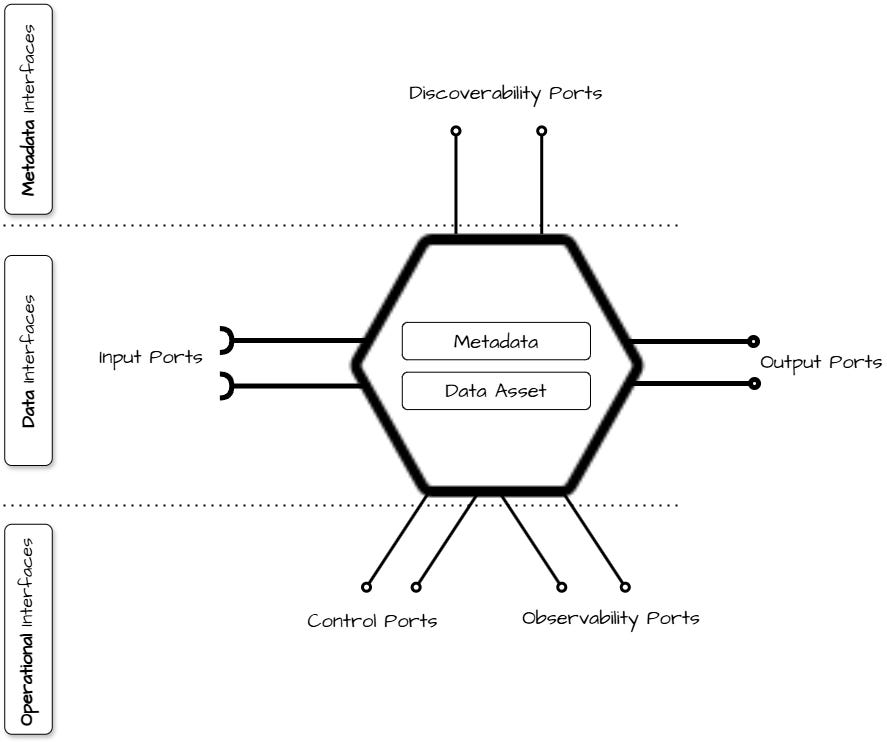
The common question arises: which output data ports should we consider for each data product?
While the golden answer "it depends" always holds true, this article outlines some distinctive factors and rules that should be considered during the design process to maximize connectivity and interoperability, which are fundamental characteristics of a well-designed data mesh.
Understanding the Role of Output Ports
To understand the types of output ports, it is first essential to grasp their practical role. Output ports can be thought of as the "nozzles" or gateways through which the informational content of a data product is accessed. They serve as the designed and controlled mechanisms provided by the data product owner to enable consumption of the product’s value.
Much like a child’s toy that features specific openings to interact with its internal functions, output ports are intentional designs that allow users to engage with the data product in a structured and meaningful way.

This analogy helps highlight a fundamental principle: the importance of rationalizing and simplifying the interaction methods with the data product. By providing a small number of clear and distinguishable functionalities, output ports ensure that data consumption is intuitive, efficient, and purpose-driven.
It is, therefore, crucial that the design of the output ports becomes a cherry-picking activity by the Data Product Owner (DPO). Otherwise, excessive workload is assigned to the various teams, resulting in reduced semantic and logical interoperability.
📝 Further Reference(s)

Identify the Data Flows
To simplify DPO’s efforts and minimize the number of output ports, the first step is to design the data flows of our architecture. A useful reference here is the TOGAF framework (see example here), which provides a systematic way to map data flows before delving into the technological plane.

A preliminary macro-analysis of factors impacting the technological architecture should consider the following core axes of discretionally:
User Type
Humans: Users interact through dashboards, analytical tools, or custom queries.
Machines: Systems consuming data via APIs, streaming interfaces, or batch processing.
Access Type
View: Data can be viewed but not exported.
Read-Only: Data that can be viewed or queried without modification.
Read and Write: Scenarios where consumers might update or modify data.
Layering: Determining which layer (bronze, silver, gold) is accessible. This choice typically impacts the technological architecture.
Refinement Level: The pervasiveness of data quality mechanisms applied to the data. This could include:
Absent: Data is provided in its raw format (bronze) without any validation.
Pre-computed: Data is preprocessed with applied validations.
Ad Hoc: Custom preprocessing and data quality checks requested by the consumer.
Performance: Key performance metrics to consider such as:
Number of requests: The volume of data requests the system can handle.
Access time: The speed at which data is retrieved and delivered.
Historical Depth: The extent of historical data offered:
Full: The entire history is available.
Delta: Only changes since the last extraction.
Historical: Specific time periods or snapshots.
These axes allow us to define the informational perimeter needed to support the data flows while minimizing unnecessary variability or complexity. This set can be expanded to include, for example, synthetic data, real-time capabilities, or the exposure of functions (e.g., data quality services)...
📝 Further Reference(s)


Mapping to Technological Patterns
For each combination of these factors, there should be a technological pattern (delivery mode) that enables consistency and alignment with both operational ports (data delivery mechanisms) and metadata ports (data discovery and governance interfaces). An initial rationalization of behaviors into technological patterns could look as follows, which could be considered a bare minimum. It is important to note that the technical blueprint comes after the identified behaviors (or requirements).
Let us now provide an example of how such a matrix can be applied to a data product.
Example: Practical Implementation
Imagine designing output ports for a sales data product that is fed by two other data products, as shown in the following image. In this case, we are tasked with implementing the "regional sales" data product and defining its output ports:
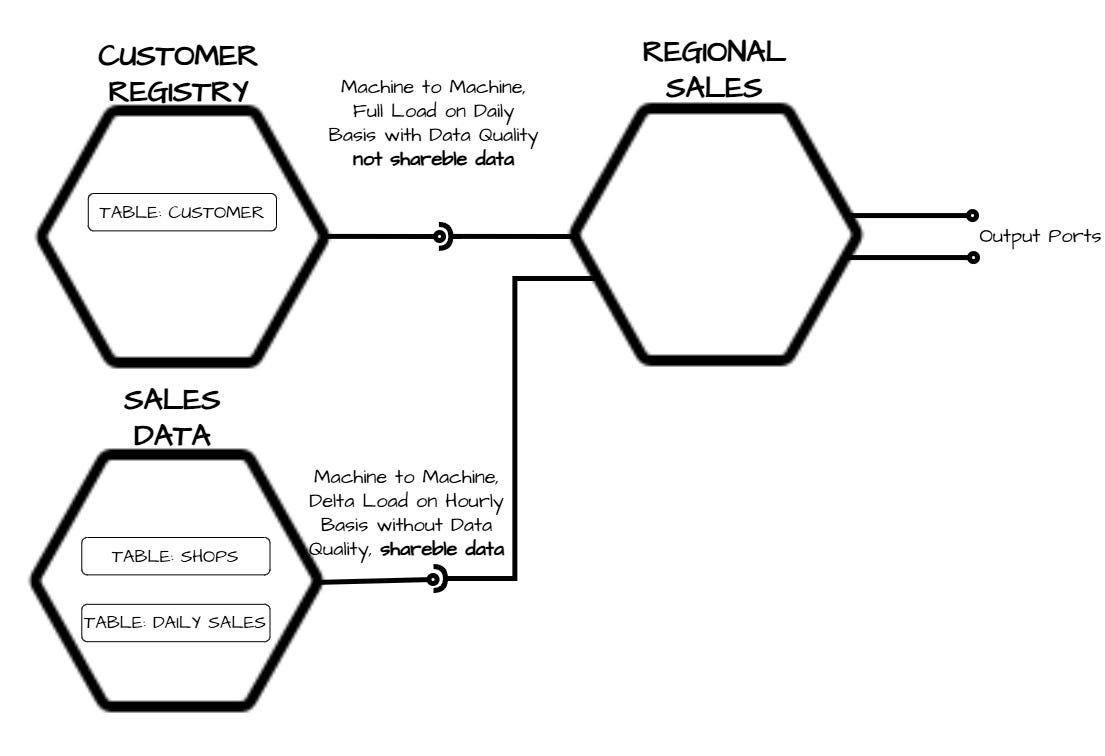
This must be combined with a logical design of the internal flow within the Data Product (which remains a black box from the outside) that should ensure that all transformations, validations, and orchestrations are aligned with the data product's defined purpose and requirements.

The implementation of all ports would result in a design like this:

This is because, while some output ports are typically implemented natively through application profiling, this is not always the case, and certain objects may require a sometimes significant effort.
It is also important to note that this data product does not expose the internal tables of the bronze layer due to constraints imposed by the data contract.
Considerations & Key Takeaways
The topic is undoubtedly broader and more multifaceted than can be covered in a single article. However, some thumb rules could include:
Ensure at least one read-only output for the gold layer, which can then be expanded to include the silver and bronze layers as needed.
Design outputs to account for the input contracts required to provide the necessary data, ensuring clarity and alignment.
Recognize that some outputs may require specific technologies and/or modules that should be developed beforehand by the platform team to avoid delays or misalignment.
Establish and maintain shared blueprints among teams, ensuring consistency, interoperability, and alignment with the overall architectural vision.
By adhering to these guidelines, teams can build scalable and efficient data products while maintaining governance and minimizing redundancy.
📝 Further Reference(s)

MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 🖋️

Find me on LinkedIn 🤝🏻
From The MD101 Team 🧡
Bonus for Sticking With Us to the End!
The quarterly edition of The State of Data Products captures the evolving state of data products in the industry. The last release received a great response from the community and sparked some thoughtful conversations.
Now, with the Special Edition: 2024 Roundup, we’re taking it further, diving deep into what shaped the data product landscape in the milestone year of 2024. This edition delivers the inside scoop on Data Products and covers the entire evolution journey across the four quarters! A true yearly roundup. Fresh insights from industry leaders who are redefining what’s possible with data.

🤫 Insider Info from a Data Technical Manager
Sheila Torrico is a noted advocate of GenAI and Data Products. With expertise in AI/ML initiatives across diverse industries, Sheila excels in leading global teams, fostering cross-functional collaboration, and delivering innovative solutions.
UX, Governance, & the Semantic Vantage of Data Products with Sheila Torrico | S1:S6

We added a summarised version below for those who prefer the written word, made easy for you to skim and record top insights! 📝