
The Complete Data Product Lifecycle at a Glance | Issue #35
Purpose of Every Stage, End Products, Associated Stakeholders, and Likeness to an Approach over Technology


This is a follow-up piece which addresses the feedback we received on how we can enhance the end-to-end Data Product Guide.
Part 1 addressed
“An easy way to convey the value of the lifecycle to stakeholders who aren't invested in detailed materials or don't have enough time for the same.”
If you haven’t come across it yet, find it here:

This is Part 2, which addresses the following feedback:
Need for a condensed view to revise the stages at a glance
Stakeholder involvement across the different stages.
Let’s dive in🤿
We’ll arm you with a compact illustration that highlights the features and end products of every stage and also share a brief textual overview of all four stages along with references to involved stakeholders.
Let’s look at the lifecycle at a glance first and then dive into the details.
Summary of every stage and involved stakeholders:
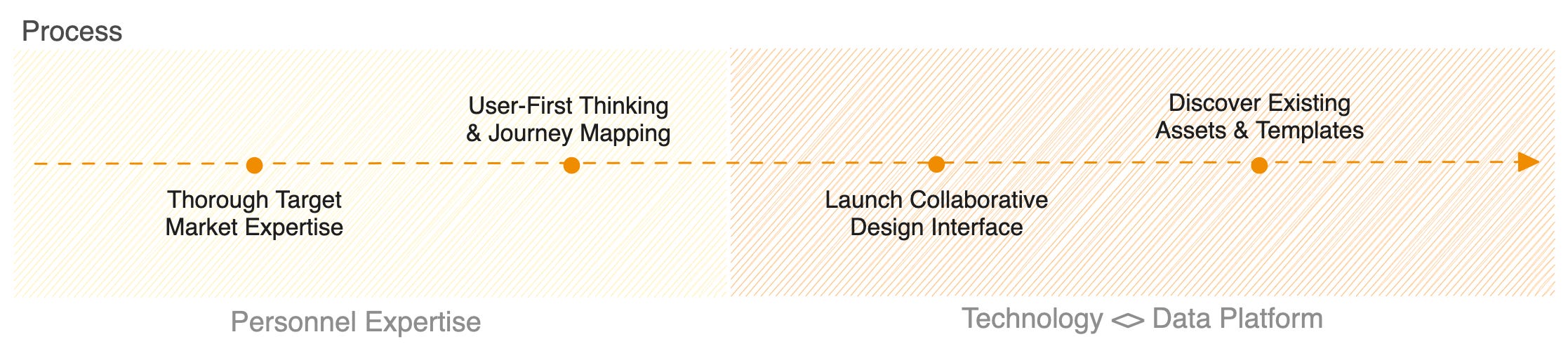
🎨 Design
Purpose
The design stage is the heart of the product approach. This is where thorough user analysis is conducted to track the most critical user problems and design solutions accordingly. The Design Stage answers questions such as:
Where is the data needed, and what purpose will it serve?
What consumption points (a.k.a. output ports) should the Data Product serve? E.g.: An API for sharing data with an app
What are the requirements of every output port?
How should the data be shaped to serve the ports and the purpose?
What data and where should it come from?
📑 End Products of the Design Stage
The outcome of Design Stage is a collection of PRDs (product requirements doc) or data contracts, one for each output port. They outline the shape of data, semantics around it, quality conditions that must be fulfilled, and the necessary policy constraints applicable to that data.
It follows that the design stage requires the active involvement of Domain Experts who understand the business and can lay down a strategic plan for the data that serves their domain’s customers. The Data Product Manager becomes the conductor, strategically integrating inputs and launching the design plan on a collaborative interface to record inputs from different stakeholders.
Note that the title ‘Data Product Manager’ is quite novel, and it has been observed how folks with different or more traditional titles deliver the same jobs. For example, a product manager who owns an AI add-on or a senior data analyst overseeing a particular analytics solution.
Once the design is validated and locked for the first cycle, the same interface is accessible by data developers to activate the design with underground mappings.
The contracts formulate a robust view of the product or a semantic data model that enlists all entities involved, such as customers and orders, relationships between them, and most importantly, metrics.

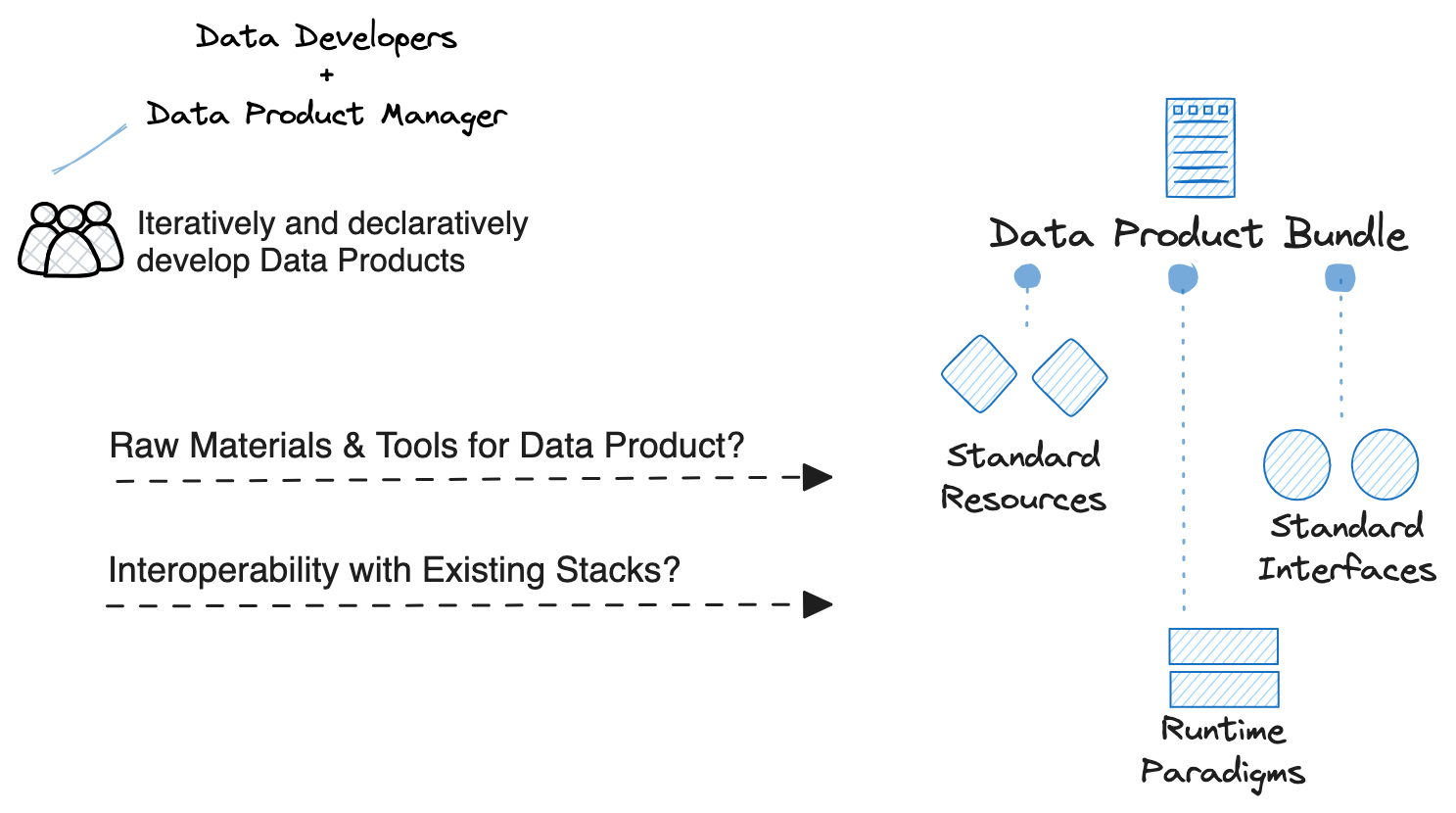
🏗️ Develop
Purpose
This is where the nuts and bolts behind the data product are put together. Given data products cut across infrastructure, code, data, and metadata, ready-to-use resources such as compute, policy, contract, storage, workflow, and service become fundamental to a seamless development experience.
The design and develop stages do not necessarily need to be consecutive. A new change request can be added to the collaborative interface based on customer requirements, and the mapping in the development would change accordingly and rather quickly due to declarative development.
💡 Note the likeness to agile, where you don’t need to wait for different steps to end before pushing changes. It supports simultaneous as well as consecutive.
💠 End Products of the Develop Stage
The end state of Develop is a Bundle. Data Products are developed as a package or Bundle, which is a collection of all resources and assets that help the data product run smoothly. The raw materials that go into a bundle include:
Resources: Dividing large data projects into smaller and fundamental capabilities catalyses development. These fundamental capabilities could either be developed or come in ready-to-use states such as Platform Resources. E.g. a platform-native workflow primitive or a DBT pipeline sourced as a workflow.
Standard Interfaces: To talk to entities that are running outside the platform, e.g., a Databricks job.
Runtime paradigms: Programming patterns that can be run from within the platform.
🚀 Deploy
Purpose
The aim is to release frequently and release strong. This entails continuous integration and continuous deployment (CI/CD), where each merge goes through cycles of automated tests and releases to maintain an optimum state of data product experience. The purpose is also to push better experiences or states in a non-disruptive way that doesn’t impact the end user negatively.

📦 End Products of Deploy Stage
Executing this stage results in an activated data product, which is instantly populated in the data catalog and starts serving all applications plugged into the output ports. These applications may vary from a query interface, a CRM, an AI app, or even a dashboard.

The true power of this stage is, in fact, in the Data Platform that enables it. Optimal change management and release are the first and only priorities of the deployment stage, which makes this phase the critical pivot of the data product lifecycle. Every other stage fosters static assets, and this stage is where the changes are activated and pushed into the data product.
🌱 Evolve
Purpose
The significance of the evolve stage is that it is the change inducer for optimising resources, SLOs, and integrations based on both machine and consumer feedback. Right after a data product is live after deployment, all data around its operations and consumption patterns are recorded and analysed to send back meaningful insights.
💡 Like Agile, feedback can stream into any stage in the lifecycle instead of just the initial design stage.
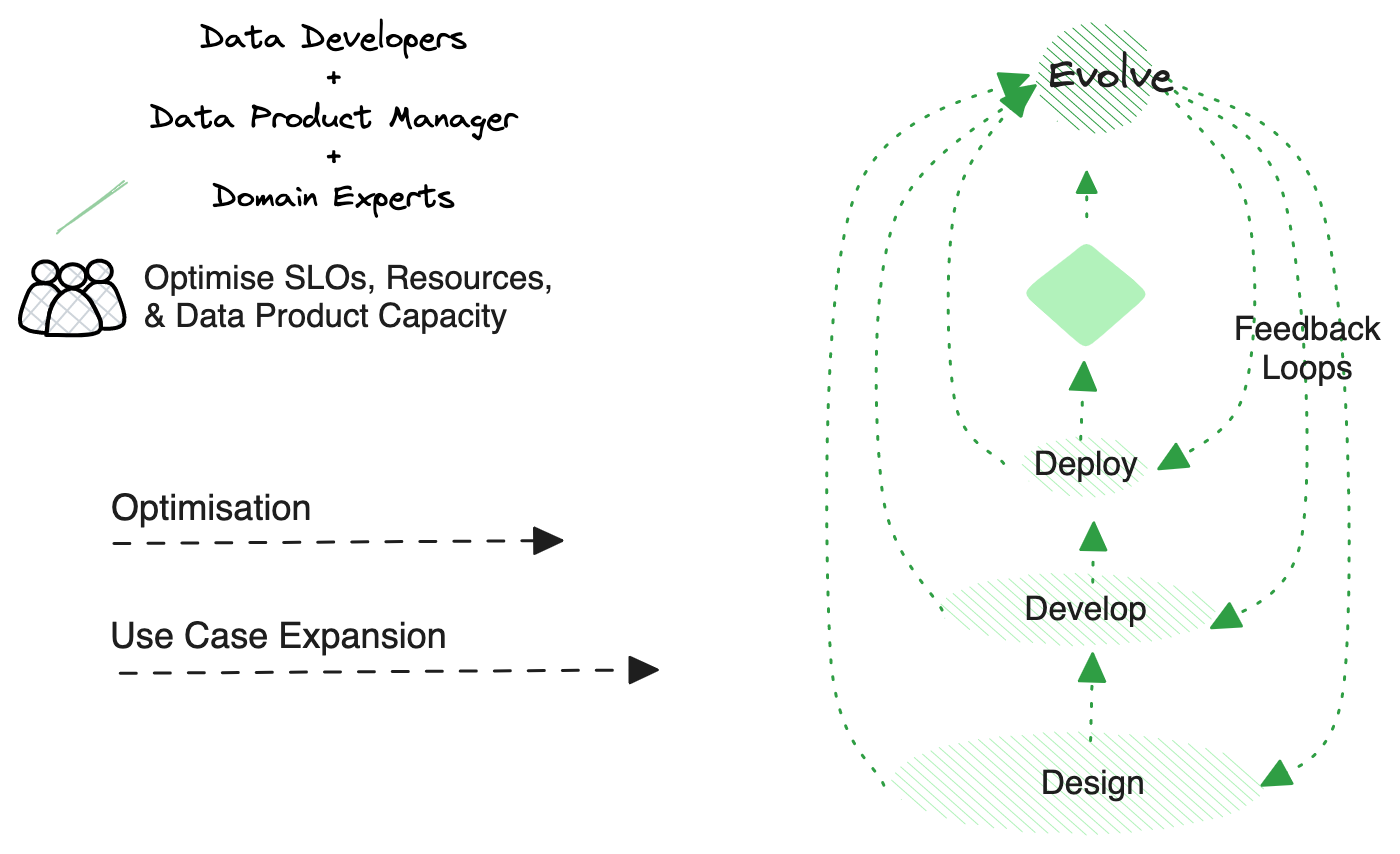
This phase in the lifecycle also furnishes maintenance toolkits for developers to react efficiently to monitoring incidents and enhance key product fitness metrics such as time to recovery and uptime. The evolve stage completes the feedback loop. Having a sense of key metrics and objectives across different functions also helps resolve conflicts early on without disrupting ongoing builds and deployments and restarting from scratch.
♻️ End Products of the Evolve Stage
This stage sends back Feedback or meaningful insights on metrics, applications, code, and infrastructure to influence the lifecycle phases and the domain experts in the next iteration of the lifecycle. This demands continuous monitoring and stakeholder involvement for meaningful analysis of observed metadata.
The feedback can be used to empower four top objectives:
SLO Evolution: Insights to generate better SLOs or metrics that serve and measure the business better. This is achievable by discovering better connectivity and detecting points of potential.
Use Case Expansion: The more use cases a Data Product can serve, higher is its value. Post-deployment analysis of the data product’s active state and consumption patterns brings to light new opportunities for leveraging the data product for more diverse and effective use cases.
Resource Optimisation: Insights generated from the activated data product are used to gradually understand how resources are being consumed and, thereafter, create a better bundle with a more efficient chain of resource dependencies.
Issue Resolution: Insights from the evolve stage are vital to understanding why and how bugs or harmful incidents occurred, narrowing down the scope of analysis to target geography in a wide data product.

🎯 Final Thoughts
It’s important to understand Data Products is more an approach than technology, much like Agile for Software. Agile went through its share of pushback from sticky processes and emerged as a must-have. Post-adoption, Agile became a game changer for software teams and products.
But an approach for software cannot necessarily be duplicated for data. We have seen that over most part of the last decade. Interestingly, the Data Product approach has changed that. It works for the core indefinite element of any data stack that is absent in the software stack: Data. And it needs to be actively enforced through a Data Product Platform that integrates with existing data stacks.
More about it soon!
🪶 Co-Author Connect

 | A guest post by
|