
Rise of The Context Architecture: Where Meta is More Vital Than Information
Creating Agency for Non-Human AI Agents Requires Data on Data: How to Extract, Build, and Deploy this Context. Trinity of Deduction, Productisation, and Activation.

TOC
The Collapse of Context in Today’s Data Platforms
The Rise of the Context Architecture
First Piece of Your Context Architecture: Three-Layer Deduction Model
How Deduction Enables Indexing: Reasoning Systems at the Centre, Catalogs at the Periphery
Sidecar of the Deduction Stack: Intelligence as an Interface
Second Piece of Your Context Architecture: Productise Stack
Side Note: This Conjunction Also Demonstrates The Right-to-Left Application or “Shift Left”
A More Technical View of the Productise Stack
Third Piece of Your Context Architecture: The Activation Stack
Catalogs Won’t Disappear
The Trinity of Deduction, Productisation, and Activation
The Collapse of Context in Today’s Data Platforms
Context is the hyperfuel in the AI uprising. It is data on data: the meta layer that transforms dump characters into meaning. Ironically, one of the world’s leading AI companies understood this long before and literally rebranded itself as Meta. Irrespective of good or bad decisions the company takes here on, we as data practitioners cannot deny the genius of the naming and the semantic significance of it. The goldmine was always data, but the concentrates are the relationships, the meanings, the feedback loops.
Data tells us what happened, but context tells us why, and in a world where every model, agent, and algorithm depends on understanding rather than access, it’s the context layer that becomes the source of power. In this new distribution system, metadata is no longer the by-product; it’s THE product.
Current-day data platforms (an almost limping evolution on top of legacy systems) are built to store, process, and distribute data, but not to understand it. This has created a significant gap for AI adoption by enterprises, and while many pilots are undertaken, only 5% are apparently taking off. This is a huge write-off and loss of ROI for data and AI champions, who want to bring change but are unable to.
The absence of context boundaries means that every table, dashboard, and metric floats in isolation. They are fragments of truth without a shared narrative.
Catalogs were introduced to solve this fragmentation. They were meant to give the system a sense of consolidation, but instead became search indexes for unknowns. They could tell you what exists, but not why it matters. They describe, index, and label, instead of deducing, interpreting, or learning. Catalogs are extremely useful, if only there is a solid context architecture behind them that is architecturally consolidating the data ecosystem. And this is genuinely not the job of catalog companies or siloed catalog tools. The change needs architectural intervention from within your organisation.
Reasoning (the ability to connect meaning, purpose, and dependency) is exactly what the next generation of data systems must learn to do, instead of slapping on dumb search at the far end of the data stack.
The Rise of the Context Architecture
The Context Architecture marks a structural shift, from managing data to understanding it. For years, organisations have collected data without context, optimised pipelines without meaning, and catalogued metadata without comprehension. A well-engineered context architecture changes that by reconstructing context across disconnected layers: not through documentation, but through deduction.
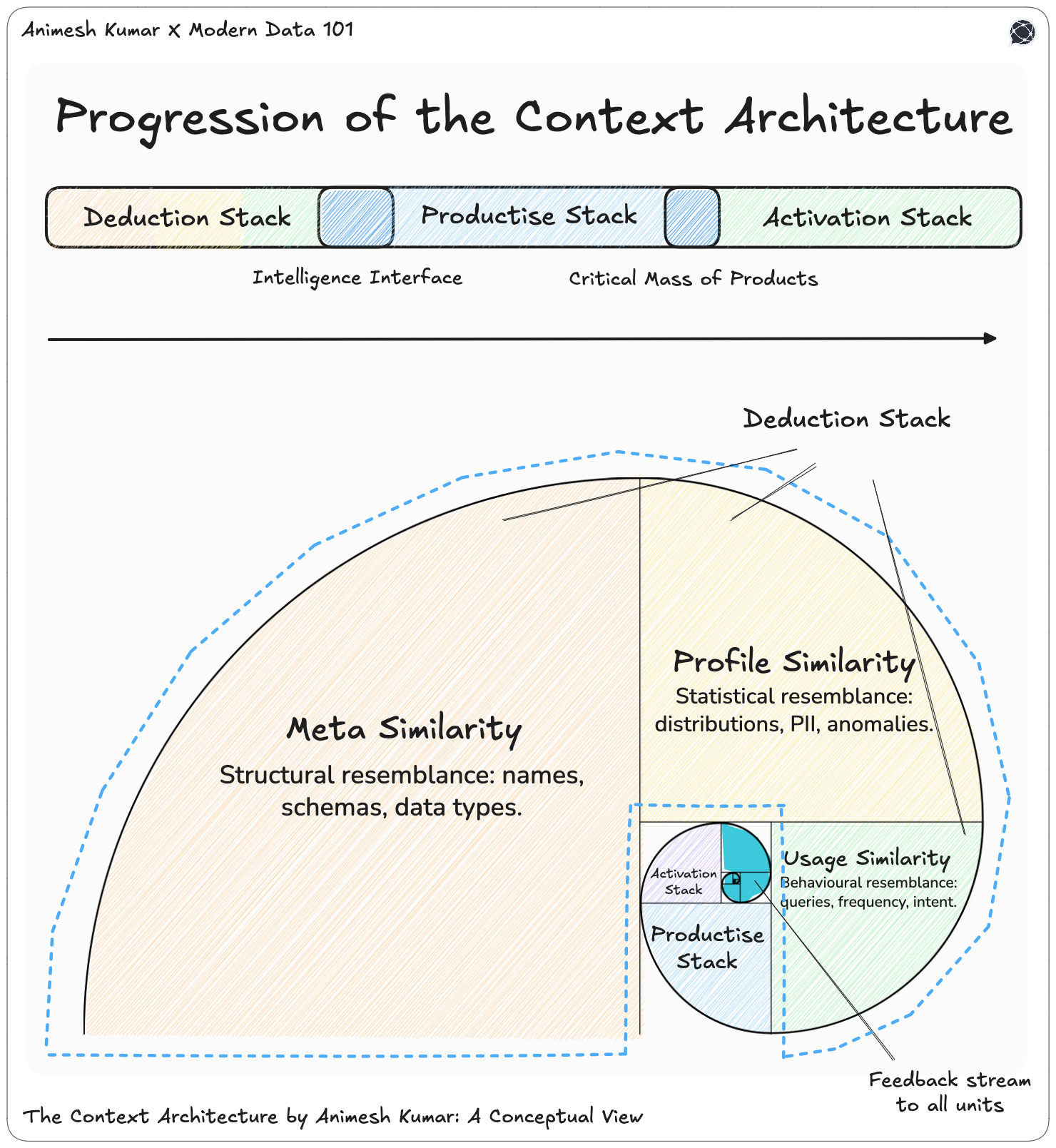
It begins, deceptively, with something simple: a source address. A single connection. But that one address is enough to spark a chain of understanding.
First, it connects. It dives into the data source: Snowflake, BigQuery, Redshift, doesn’t matter and retrieves everything it can know about the landscape: schemas, tables, columns, relationships, stored procedures, functions. This is where the map is drawn.
Next, it profiles. It goes beyond structure into behaviour: the distributions, the sizes, the anomalies. It detects PII, sensitive data, and what we call toxic pairs: combinations of data points that should never coexist. This is where the terrain becomes visible.
Finally, it analyses usage. It learns who runs which queries, on what tables, how often, and for how long. It observes cost signals, cluster patterns, and access paths. This is where movement comes into play: the living pulse of your data ecosystem.
These three layers: Meta, Profile, and Usage, form the base intelligence of the Context Architecture for AI and actionable Data Operations. Together, they allow the system to reason: to see which tables are written often but rarely read, to detect redundancies across pipelines, to identify convergence: where columns and tables begin to resemble each other across systems.
First Piece of Your Context Architecture: Three-Layer Deduction Model
Let’s call this the Deduction Stack: a three-layer deduction model, where similarity isn’t reduced to vectors but reconstructed through reasoning.
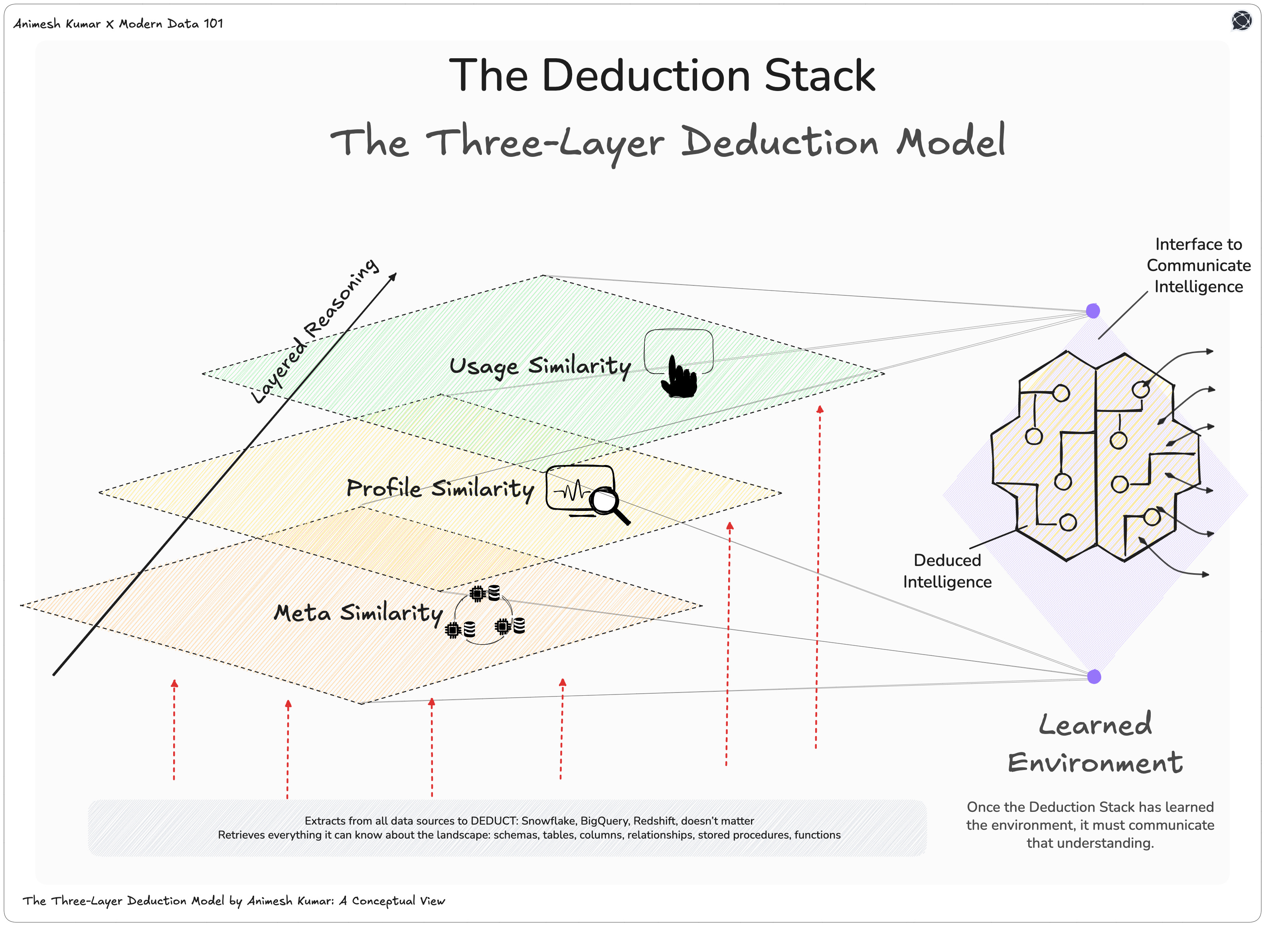
The first layer is Meta Similarity
The structural resemblance between entities. It observes names, schema design, column count, and data types. This is the skeleton that hints at how systems are organised.The second is Profile Similarity
The statistical fingerprint of data. It studies distributions, regex patterns, PII markers, and anomalies to infer what kind of information the data carries. This layer moves from what it’s called to what it contains.The third is Usage Similarity
The behavioural resemblance that reveals intent. It traces who queries a table, how often, and for what purpose. This is the layer where meaning emerges from motion. Access patterns become indicators of value.
Unlike vector embeddings, which capture textual likeness, this model captures relational logic. Vectors work well for language, but data systems aren’t sentences; they are ecosystems of relationships. Similarity here isn’t measured with cosine distance but conceptual closeness across structure, semantics, and behaviour.
For instance, even if one table labels a field as “eml” and another is labelled “email,” the system deduces their equivalence by profiling their patterns and usage instead of by the name/title solely. Layered reasoning: it doesn’t search for matches; it constructs understanding just like we do.
How Deduction Enables Indexing: Reasoning Systems at the Centre, Catalogs at the Periphery
The difference between a catalog and an understanding system is the difference between storage and reasoning. A catalog is an index that inventories assets, lists what exists, and maintains order. Useful, yes, but passive. It doesn’t know how data behaves, what it influences, or why it matters.
The Context Architecture and especially the Deduction Model, in contrast, make a reasoning engine. It doesn’t stop at description and enters deduction mode. It observes patterns, infers relationships, and derives meaning from motion.
In the new data architecture, this distinction becomes foundational. Catalogs doesn’t sit at the center and have become part of the edge of the data stack. Reasoning systems are the new intelligence core, continuously learning from the touchpoints it connects to.
Once repositioned, catalogs can regain their value: Instead of static inventories of metadata, they become dynamic indexes of deductions and insights generated by the Context Architecture. In other words, catalogs will finally catalog understanding.
Sidecar of the Deduction Stack: Intelligence as an Interface
Once the Deduction Stack has learned the environment, it must communicate that understanding. This is where the Intelligence Interface comes in: the bridge between cognition and action.
It exposes APIs, GUIs, and an MCP Server, giving users multiple ways to interface programmatically or interactively. But the interaction isn’t generic; it’s contextual.
Every role sees a different face of the same intelligence.
A Snowflake admin receives cost and duplication insights. A data engineer sees schema drift and query pattern analysis. A product owner views data readiness and quality reports.
AI-native ability of the data platform that is enabling your context architecture makes this interface personal. It learns from how users explore, what they search, and which anomalies they care about. Over time, it builds intent models that customise both insights and explanations/reasoning to each persona. Reports become dynamic surfaces of understanding instead of static PDFs or dashboards frozen in time. They are responsive and aware of who’s asking the question and why.
Just like your chatbots respond to you based on the memory you’ve created for them. Hyper personalised at scale.
Second Piece of Your Context Architecture: Productise Stack
The Deduction Stack was born out of the most relatable data consumer experience: catalogs became indexers that failed the data product era. They could tell us what existed, but not how it behaved, evolved, or interacted. And in the world of data products, to build something valuable, you must first understand its underlying logic: how data flows, transforms, and relates.
This is where the Deduction Stack finds its true purpose: it doesn’t end with understanding; it feeds it forward. The deductions, mappings, and behavioural insights it constructs become the raw material for the next piece: the Productise Stack.
In this continuum, the output of one becomes the input of the other. The Deduction Stack builds the semantic spine; the Productise Stack gives it form and function. Together, they close the loop: from knowing your data to engineering it into products that think, adapt, and deliver value on their own.
The Deduction + Productise ecosystem represents this full spectrum from latent potential to realised value.
The Deduction Stack governs the physical layer: it knows what exists, how it behaves, and where inefficiencies or opportunities lie.
The Productise Stack, on the other hand, governs the product layer: it knows what’s been built, how it’s consumed, and what new constructs can emerge from the existing understanding. It maps your realised intelligence: the data products, services, and models that embody business outcomes.
Together, they form a closed intelligence loop. The Deduction Stack reveals your current potential, while the Productise Stack manifests it into living products.
Their union is the 100% spectrum of enterprise data capability.
📝 Related Read(s)

Side Note: This Conjunction Also Demonstrates The Right-to-Left Application or “Shift Left”
In traditional data workflows, teams move left to right: from ingestion to modelling to consumption, assuming the path from raw data to product is linear. The right-to-left model flips that logic. It begins with understanding what already exists (the Deduction Stack) and moves toward what can be built (the Productise Stack). Productisation no longer starts with requirements in isolation but with grounded awareness of the available landscape.
Take a “Customer 360” data product. The product manager defines desired attributes (reachability, interactions, transactions) and the Productise Stack queries the Deduction Stack to discover which sources, joins, and relationships already exist. From there, it defines validations (every customer must have at least one verified channel) and automatically generates the contracts, schemas, and quality checks needed to bring it to life. This isn’t ETL. It’s context-aware transformation, where every product is born from understanding real on-ground requirements.
A More Technical View of the Productise Stack
Productise Stack = Physical Model + Semantic Model + SLA + Validation
The Productise Stack is the unit that builds, defines, and deploys data products with precision and intent. It is the manufacturing system of the modern data enterprise, translating the contextual intelligence of the Deduction Stack into tangible, consumable assets.
From a single product definition, it automatically generates everything required for lifecycle integrity:
Data contracts
Lineage
Quality checks
Schemas
Consumption APIs
Graph APIs
and ODPS specifications.
When your data product is deployed, you don’t need multiple the above off the shelf, so the stack is built to generate them.
Each element is derived and built on the logic of what the system already knows.
Once deployed, business users no longer interact with tables or queries; they interface directly with data products: coherent, validated, and ready for use.
📝 Related Read (s)


Over time, the ecosystem reaches critical mass, where each new data product compounds the value of the last. The enterprise evolves into a self-reinforcing network of reusable data products.
Third Piece of Your Context Architecture: The Activation Stack
The Activation Stack begins after the critical mass of data products. Where understanding and insight transform to scale, and the critical mass of data products transforms from isolated constructs into an ecosystem of intelligence. This is the moment you digitally transform from data management cycles to a data-to-action workflow.
In this stack, data products are business assets: operational, queryable, and ready to be activated by real operational systems. Teams or machines can interact directly with these products, asking questions, triggering automations, or making real-time decisions without ever touching a raw table.
For example, a Mac user doesn’t care which factory built the display, they care about the experience it delivers. Similarly, end users don’t care about lineage or joins but are more interested in precision, timeliness, and trust. The Activation Stack abstracts complexity, allowing domain-specific apps, be it in marketing, supply chain, or finance, to plug directly into the intelligence network of data products and act on them instantly. This is where data finally behaves like software with composable and responsive features.
The Activation Stack connects every data product into a shared fabric through comprehension of each other (data products, entities, tables). Each data product exposes an MCP interface that declares three simple truths:
what it knows,
how it can be queried,
and what it can provide.
These self-descriptions become the language of understanding across the system.
On top of this, agentic frameworks operate like cognitive overlays. They reason across data products, infer relationships, such as deducing that customer.id in one product aligns with order.customer_id in another, and dynamically assemble knowledge without predefined joins. The system begins to reason contextually, pulling distributed intelligence together only when and where it’s needed.
Over time, this reasoning deepens. As data products communicate and infer from one another, the ecosystem itself becomes smarter, evolving from a network of assets into a collective intelligence system.
This is the path to AI maturity. When the data platform is not “building” intelligence, but the architecture enables intelligence to “evolve.”
📝 Related Read(s)


Catalogs Won’t Disappear
But their position in the architecture will shift to the end of the pipeline, as search interfaces over context and reasoning systems.
In this new order, the catalog evolves from a static inventory of assets to a context engine: a surface through which humans can query not raw metadata, but deduced knowledge. You won’t search for a table; you’ll search for a truth the system has already reasoned.
The Trinity of Deduction, Productisation, and Activation
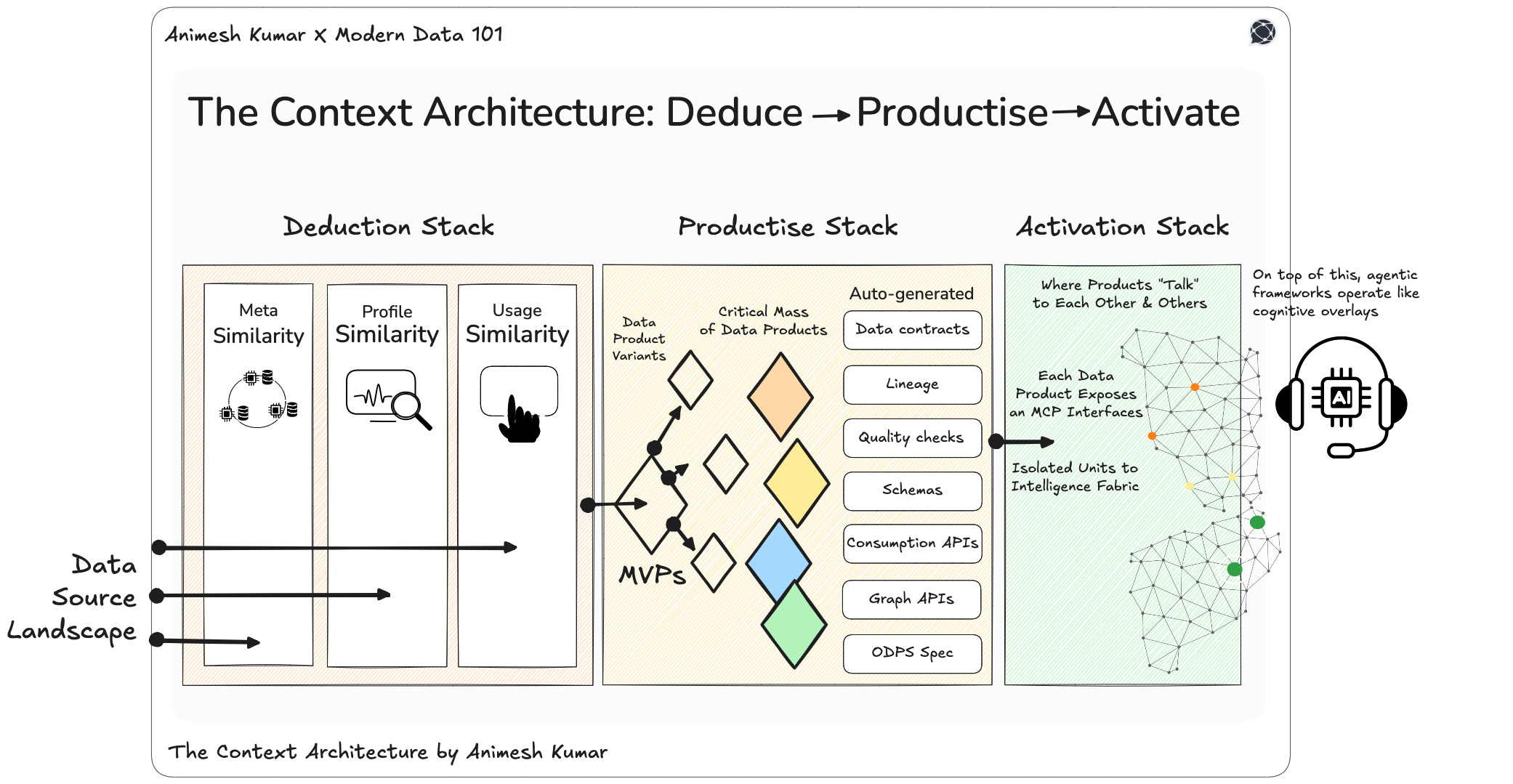
Deduction Stack: Understanding (Understand Value)
Productise Stack: Productisation (Make Useful)
Activation Stack: Movement and Activation (Bring to Users & Enable Use)
Together, these three form the Context Architecture: a closed-loop system where organisations can see what they have, build what they need, and activate what they build.
Author Connect

Learn More About Animesh On MD101 Experts’ Directory

what tool do you use to for diagrams?