
The Vision of Vibe Data Modeling: Are Organisations Ready
Vibe Coding landed in our lives to give superpowers to people without technical skills, is this the case for data people working on data modeling?

This piece is a community contribution from Alejandro Aboy, a data engineer with nearly a decade of experience across analytics, engineering, and digital tracking. Currently at Workpath, he is the main data platform stack owner, building scalable pipelines, automating workflows, and prototyping AI-powered SaaS analytics using tools like Airflow, dbt, Aurora, and Metabase. With prior roles at AILY Labs and Ironhack, Alejandro has built a strong foundation in web and marketing analytics, shifting into modern data stack tools to deliver robust ELT workflows, visualisations, and governance systems. He also writes The Pipe & The Line, where he reflects on modern data engineering and the evolving stack. We’re thrilled to feature their unique insights on Modern Data 101!
We actively collaborate with data experts to bring the best resources to a 10,000+ strong community of data leaders and practitioners. If you have something to share, reach out!
🫴🏻 Share your ideas and work: community@moderndata101.com
*Note: Opinions expressed in contributions are not our own and are only curated by us for broader access and discussion. All submissions are vetted for quality & relevance. We keep it information-first and do not support any promotions, paid or otherwise!
TOC
Data Modeling and AI: Is it Possible at all?
Current Use Cases of Data Modeling
Constructive Data Modeling
Destructive Data Modeling
What Challenges Await Agent-Driven Data Modeling
How Can We Get Ready For Vibe Data Modeling
The Vision of Vibe Data Modeling
Level 1: Extend Your AI IDE
Level 2: Add MCP Power
Level 3: More Tools
Final note
Over the last few years, we’ve been reading authors such as Inmon and Kimball to understand how to prepare data in ways that could help our future selves maintain data warehouses in the most optimal way.
Inspired by these, we applied techniques such as Star Schema, OBT, Data Vault, and different levels of normalization to keep our data assets clearly defined.
Then, we started having cooler toys; the Modern Data Stack brought tools such as:
dbt or SQLMesh for data transformation, so we could run away from SQL Stored Procedures
Snowflake or BigQuery for powerful data warehousing, so scaling compute and storage started happening without pain
Airbyte or Fivetran for no-code ETL to quickly bring data from point A to B without all the hassle and custom scripting
Combined together, we end up with powerful setups to maintain data infrastructures to keep our company’s data going.
But there’s a problem:
We started focusing on tools and tech more than on the fundamentals, and many companies now have the greatest stack ever but discovering a new planet seems easier than adding a column to one of their data models.
And AI won’t fix that situation.
With the current pace of AI’s evolution, we are landing in a context where productivity can skyrocket if you incorporate LLMs the right way.
But, just as many other times in the past, companies might not be ready because they are already carrying a lot of technical debt, outdated documentation, and persistent data quality issues.
So, if you don’t solve all those problems first, you shouldn’t jump into adding AI to your architecture. *Surprise: we jump anyway.

Data Modeling and AI: Is It Possible At All?
In so many ways, Data Modeling is the backbone of a company's analytics-related systems:
Data engineers consider it when moving data sources and getting them analytics-ready for further complex processing.
Analytics Engineers have it as the primary tool to transform raw data and business logic into ready-to-consume analytics artifacts.
Data Analysts keep in mind what the best inputs are to answer business questions and how to put ideas together.
Data Modeling is optimal not only because we can anticipate data evolution issues and tackle them before they become a problem, but also because every new team member gets an amazing onboarding experience if it is in the right place.
Combined with a decent data governance and semantic layer setup, you are in a good spot.
However, like any good foundation, this takes time, requires consistency, and considering how fast-paced environments behave nowadays, it's likely impossible.
Current Use Cases Of Data Modeling
I like to simplify my mental model into two angles: Constructive modeling and Destructive data modeling.
Constructive Data Modeling
A new feature is added to the product, a new tool is added to the stack, and a new marketing channel needs some tables.
All these scenarios imply, as a baseline:
Scanning dependencies with downstream and upstream models.
Draw a diagram to propose relationships.
Plan how data will grow to consider compressing the table rows or using a cumulative table design to grow datasets incrementally.
Defining proper data materializations on each layer for better performance.
Adding documentation and metrics definition for these new assets.
They are usually easier to tackle since they are new artifacts to implement, but sometimes they are extensions of what’s currently there, and you need extra thinking on how to connect the dots.
For example, if backend team adds 3 new columns to a raw tables that’s used by 20 models, you will need to do an extensive scanning to get all the downstream dependencies and don’t miss any of them.
Destructive Data Modeling
Seems easier, but most of the time it’s not. Deprecating features, removing models, and everything related to deletions.
You would follow the same approach as constructive, but you can skip some parts since these models will be gone.
The big challenge is when we need to change how a model behaves after removing upstream dependencies, since that’s:
…a great opportunity to mess up a whole chain of relationships if we don’t reverse engineer it correctly.
What Challenges Await Agent-Driven Data Modeling
If it’s so complex for us to maintain a basic Data Modeling mindset, what can we expect from Agents when we try to put them down to do some data modeling for us?
The previous example on Constructive Data Modeling might get problematic when trying to achieve that with an AI IDE like Cursor, since it will skip some models out of its context eventually, unless your scope is really well defined and targeted.
Let’s ask ourselves some questions on how Agents will behave:
Will they succeed and add all new dependencies to downstream models when adding or extending model capabilities?
Will they document everything properly so data governance initiatives are up to date?
Will they succeed in removing all the dependencies and cleaning out the documentation when approaching destructive data modeling?
How do you know what to feed into these Agents?
We can’t attach our company data catalog to a context window, nor can we just input all companies’ documentation or dbt project docs to an LLM and hope for the best.
In a world of “quick requests,” we are throwing our Data Modeling design into the trash every time we proceed blindly with those quick requests, so feeding this operational inefficiency into Agents will just speed up technical debt instead of enhancing it.
We need solid foundations, a system that already works for us, and a system to put everything together that can help speed up our data modeling processes.
How Can We Get Ready For Vibe Data Modeling
As mentioned before, what works for us will scale amazingly for Agents if we find ways of putting it together. Just to recap on the most common Data Modeling Approaches, we have:
Normalized Modeling (Inmon): Source-centric with minimal redundancy and high reliance on joins.
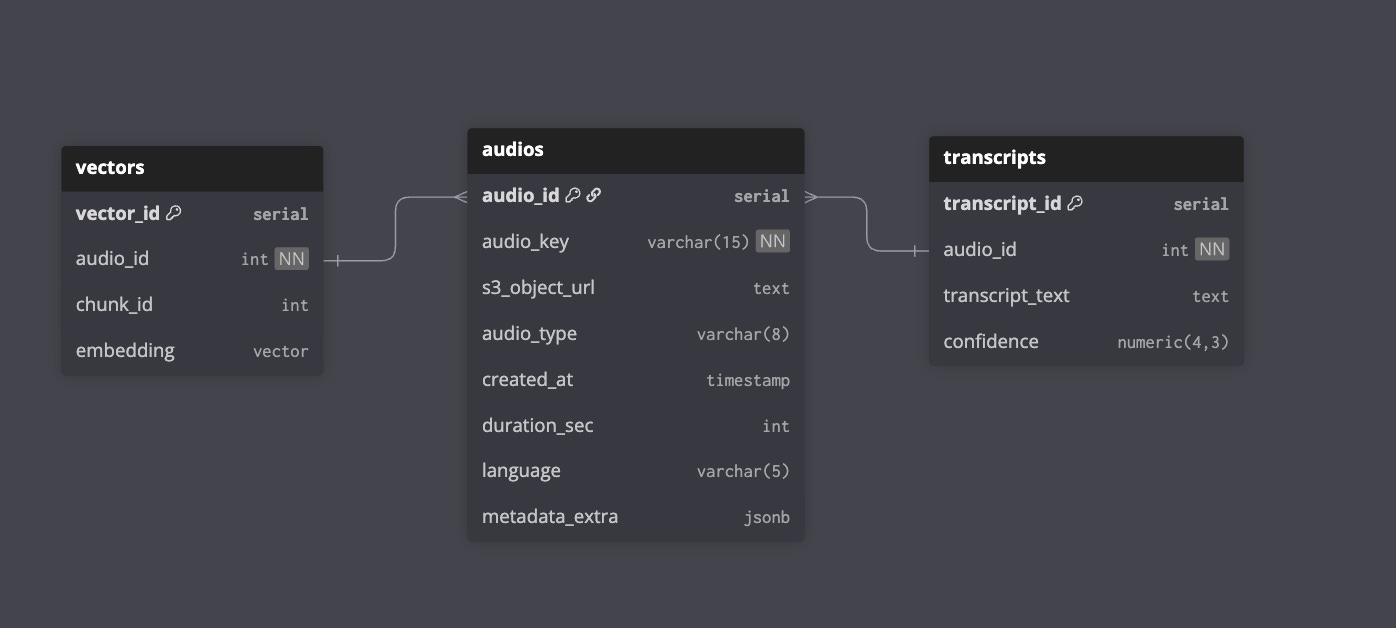
Denormalized or Dimensional Modeling (Kimball): Star schema, business function-based, less joins, more redundancy.
One Big Table (OBT): Wide, flattened tables; quick setup, but risks high computational cost and redundancy.
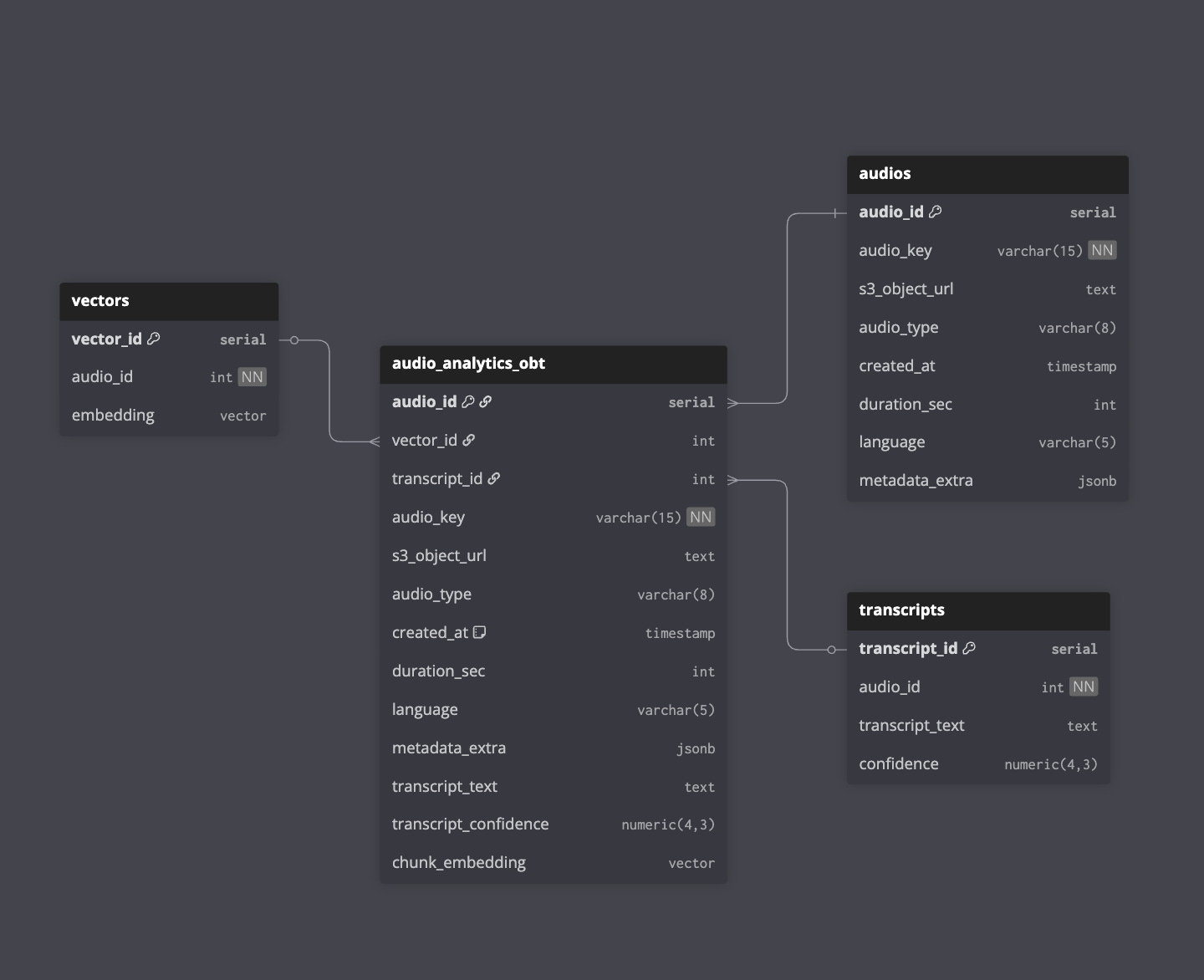
We spent a lot of time trying to decide between performance and cost optimisation (Normalization) or simplicity in spite of higher costs (Star Schema & OBT). I think the latter is ideal because:
You can remove the cognitive overhead of resolving
JOINs, which normally ends up with LLMs confusing foreign keys and over-engineering queries.You reduce the ambiguity of multiple column lineages showing in different models by pointing only to the OBT ones.
You can safely include Text2QL tools into your Agentic setup or MCP.
If you can handle OBT or Star Schema computational costs, go ahead and design good ERDs using Database Markup Language to feed data into context.
On the other hand, I’ve never seen solid implementations of highly normalized tables on companies with OLAP systems.
However if you have good documentation for LLMs to know how to use JOINs without ambiguity, go ahead. Your warehouse bills will appreciate the savings.
The Vision of Vibe Data Modeling
Let’s daydream a little.
Since it’s the most common Data Transformation tool out there, the example will be approached with dbt, but you can adapt it to your use cases.
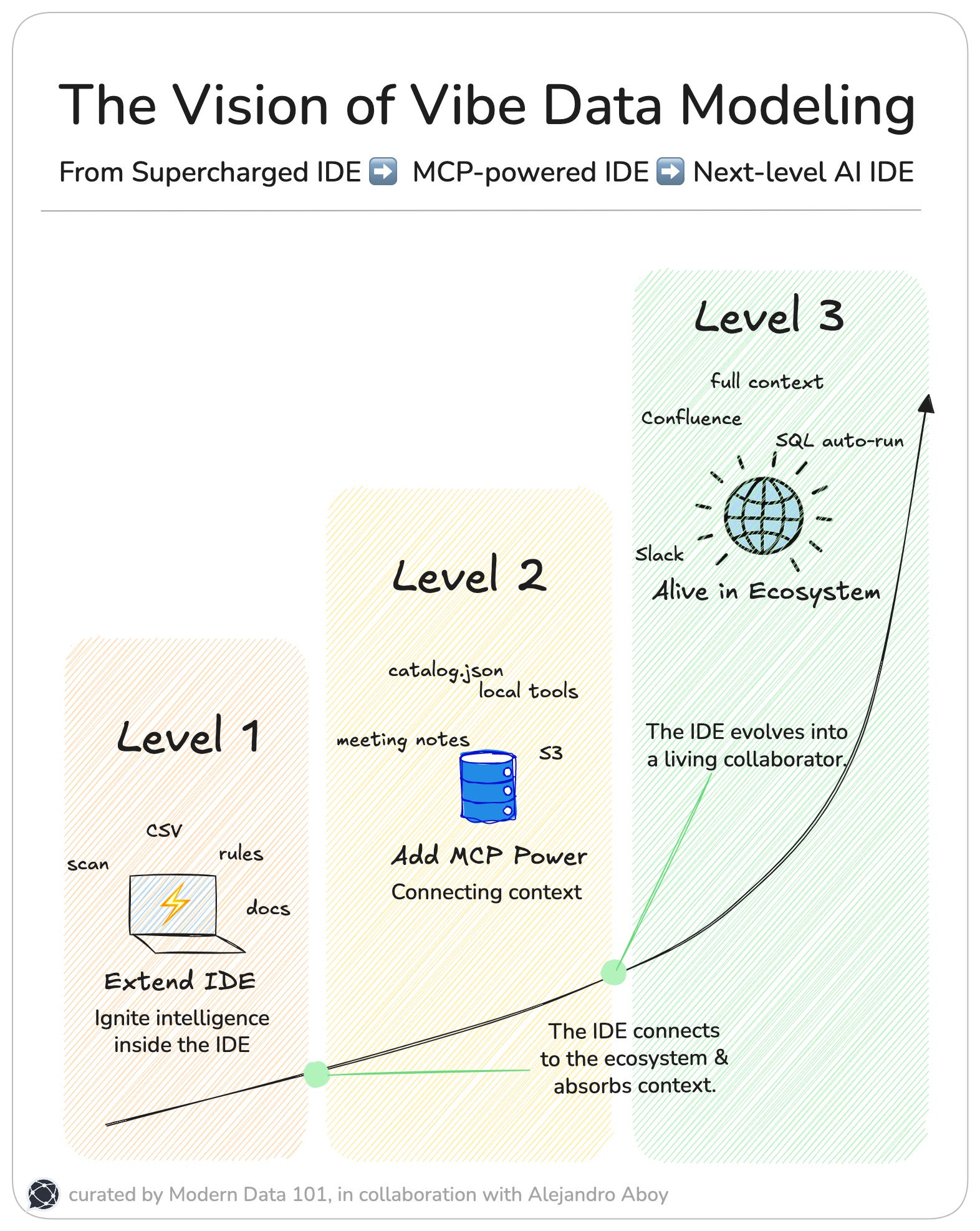
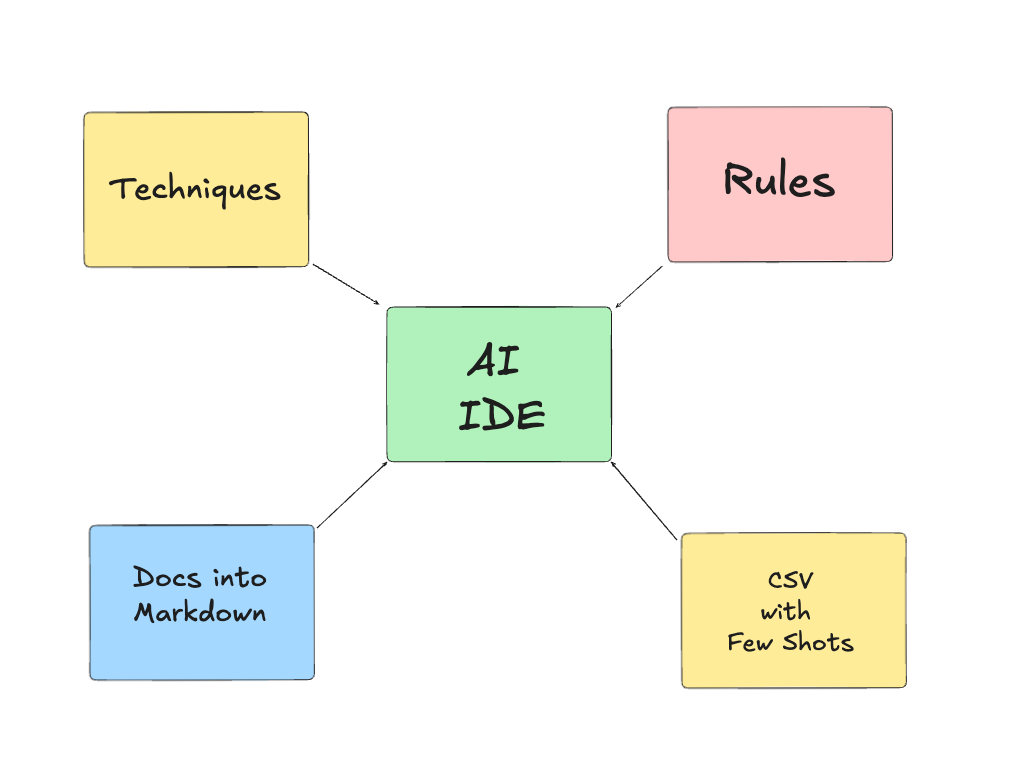
Level 1: Extend Your AI IDE
Extend Cursor or Claude Code rules to teach the LLMs how to follow your data modeling approach, scan your project to find dependencies, relationships, create-update documentation.
The workflow would be:
Add docs about the data modeling technique(s) your team uses, so the model can interpret them accordingly.
Adding the affected models to the context.
Ask for a full scan of model dependencies and documentation before asking for anything else, so you keep enriching the context.
Explain the business requirements using prompting techniques, such as Few Shot, or provide an output CSV from running manual queries, so the model can understand desired outputs.
On Cursor (Example):
Find a good website talking about Kimball Modeling and add it as an indexable doc that can be attached to the context.
Go to your dbt projects and ask Cursor to scan dependencies of a model you want to remove, ask for Mermaid diagrams to show the full scan. When you get to a good point, ask it to create a rule based on this.
Attach your documents with business requirements to ChatGPT and ask it to convert them to a detailed plan in Markdown that you can attach to the context, but don’t commit to your dbt project.
Bonus: on the same ChatGPT conversation, add some small CSV outputs of your desired outcomes and ask it to include those in the Markdown docs as few shot examples, so you can set a success criteria for the AI
Level 2: Add MCP Power
With the Level 1 approach, I might still be missing relevant business requirements details that would change the output quality. The absence of the data catalog can also lead the IDE to some mistakes due to missing some of the nuances. Lastly, to provide output examples on SQL queries, I need to run them manually and paste the output, so the UX is not perfect.
Imagine:
You use Google Meet with Meeting Notes enabled to gather business requirements from stakeholders and conduct team meetings to scope your data modeling approach.
Have a script in place that saves your dbt
catalog.jsonandmanifest.jsonon an AWS S3 bucket, so it can be easily retrieved.
These are all tools for an MCP server:
Expose Tools to retrieve and summarize Meeting notes of certain documents to have that in context.
Expose Tools to retrieve S3 files.
Expose Resources with the latest catalog.json version so they can be read by the MCP server.
So now, while you are on Cursor in your dbt repo, you can ask for meetings summaries to plan for a Data Modeling implementation and check the dbt catalog before going ahead with any change.
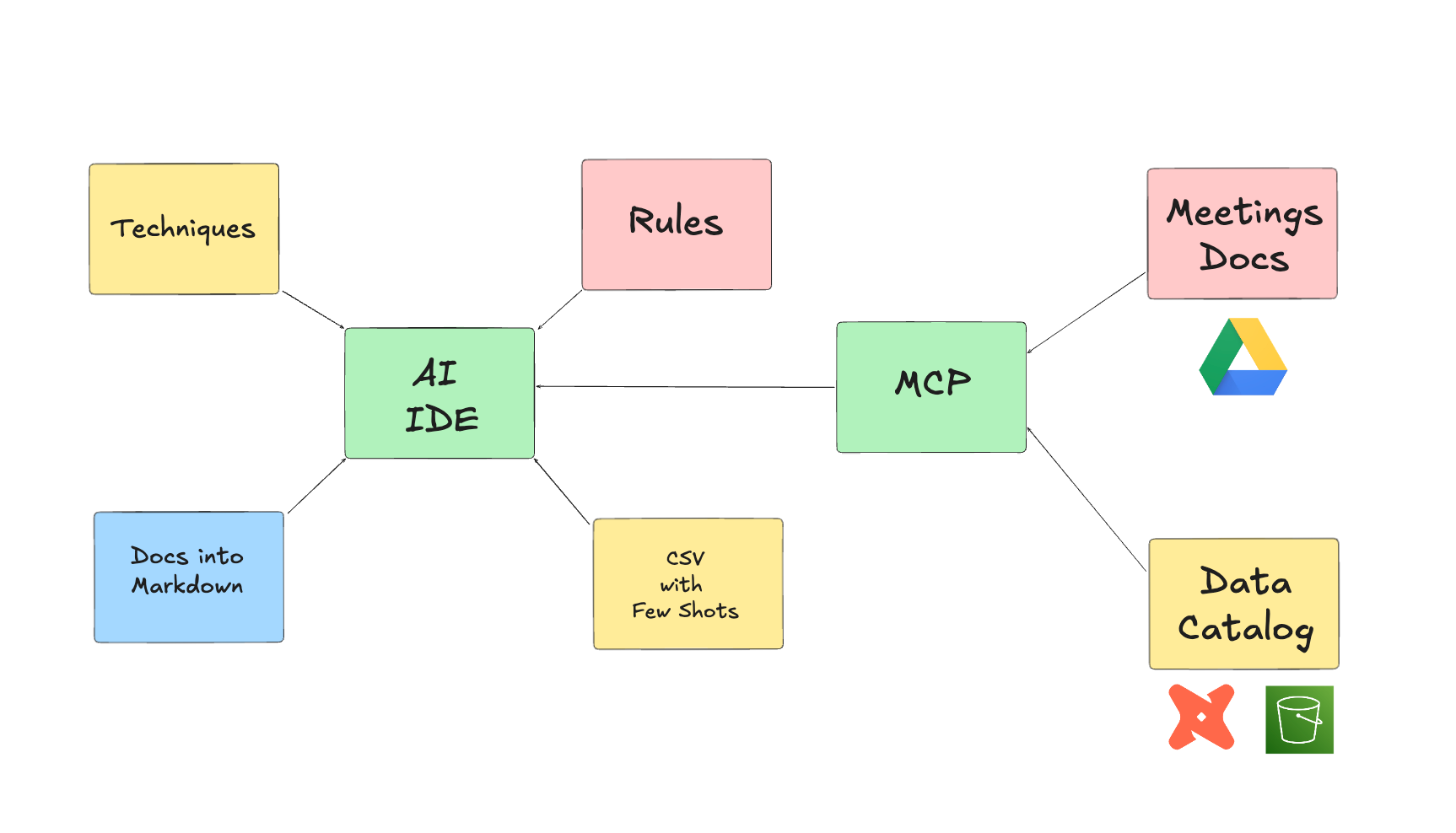
If context gets too much, you can temporarily save the outputs on markdown files so they can be fetched on demand and not handled through conversation context.
The good thing is, you don’t have to deploy this on production; you can just keep it for local usage.
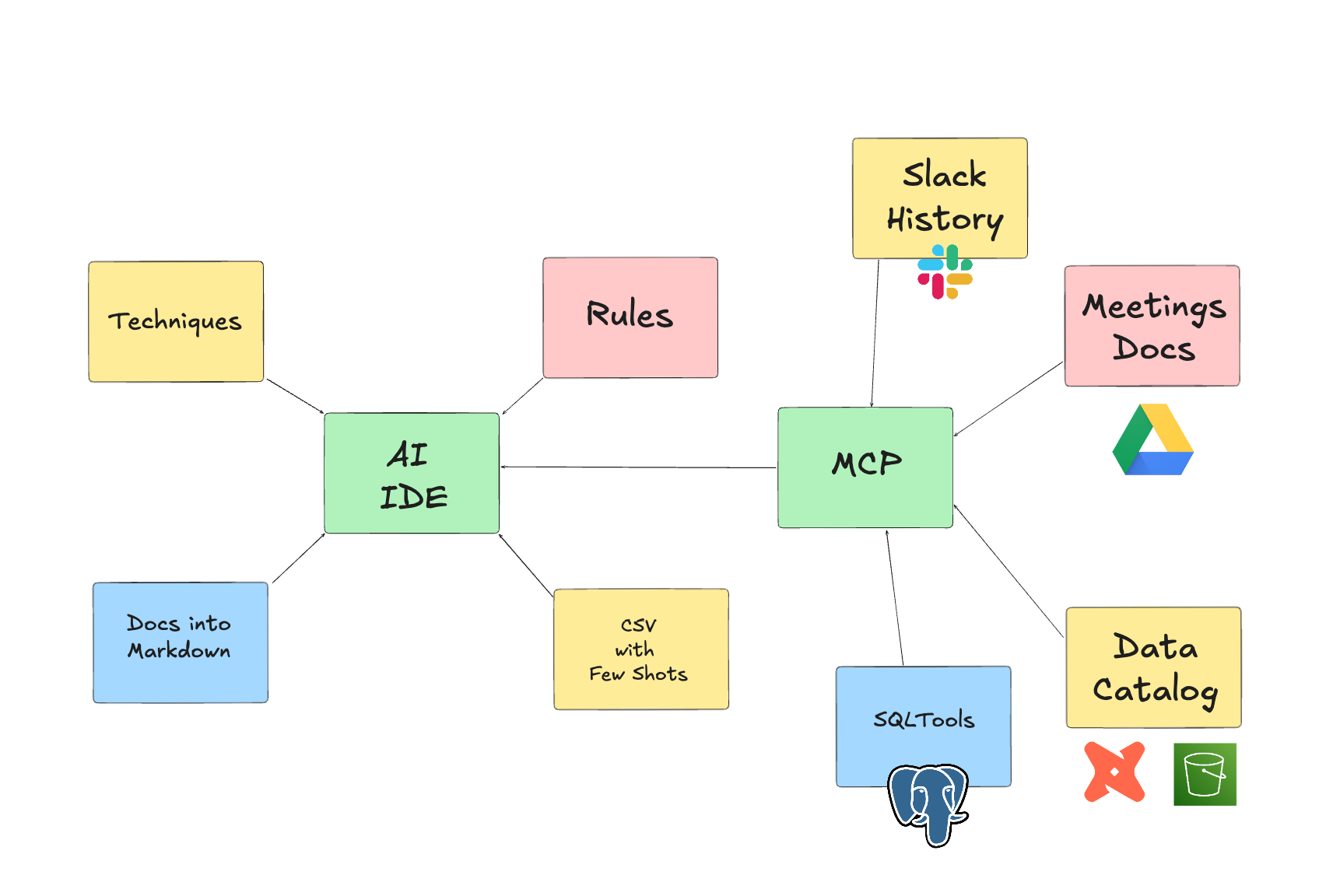
Level 3: More Tools
On Levels 1 and 2, your AI IDE can pick up your meeting documents from a Drive folder, expose your data catalog to the server to check any nuances, and start modeling by scanning all dependencies perfectly.
But it doesn’t end here; it can go beyond:
Tools to scan Slack channel history to find potential bugs or mentions about the topic.
Tools to scan Confluence pages on past Data Modeling implementations to find out about any other caveats on the topic.
Tools to run SQL queries to understand how the output looks, so you don’t have to input examples manually.
Final Note
This is not about AI replacing us, but using it in our favour to make us better. These examples are realistic approaches that I have been experimenting with, but they can be more or less useful depending on your company’s context.
Small startups with small data infrastructures can quickly benefit from this since context management is not a handicap, but big data companies need to work on more isolated tasks or consider more extended versions of these approaches.
At the end of the day, there will be things that models won’t catch or understand, even if we plug in context. There are lots of things we know without realizing that we aren’t yet ready to feed into LLMs, so these kinds of projects need tons of iterations before reaching autonomous scenarios.

Author Connect

Find me on LinkedIn 🙌🏻
Learn more from Alejandro Aboy on his stack: The Pipe & The Line 🧡

Top Artefacts From MD101 🧡
Thank you for sticking with us to the end!
The Modern Data Survey Report: By the Community, for the Community
230+ Industry voices with 15+ years of experience on average and from across 48 Countries came together to participate in the first edition of the Modern Data Survey
Locating specific time sinkholes
Uncovering recurrent and unnecessary tooling gaps
Projecting the Desired Data Stack in Demand
And much more!

🧡 The Data Product Playbook
Here’s your own copy of the Actionable Data Product Playbook. With 3000+ downloads so far and quality feedback, we are thrilled with the response to this 6-week guide we’ve built with industry experts and practitioners. Stay tuned to moderndata101.com for more actionable resources from us!

The State of Data Products, Q2 2025
Last quarter had so much piled up in the world of Data Products! The challenges of GenAI implementations, what VCs and Founders are saying, deriving the role of data solutions for GenAI, the vision of Data Platforms and Design Principles, “Operating Systems ” for GenAI, and so much more!

 | A guest post by
|
Dimensional design not denormalized. Facts are 3NF, dimensions are 2NF.