
New Data Roles to Prep for in an AI-Transitioned World
We're all deeply integrated in the AI-world now and have most definitely felt the need for some new special skills. This one's all about that.

Overview
The Wrong Conversation: “Will AI Replace Data Teams?”
What a Data Role Is in Today’s Context
What Changed: The Arrival of the AI Consumer
The New Map: Roles the Agentic Era Is Creating
The Roles Being
EliminatedRedefined
The Wrong Conversation
Every few years, the data industry manufactures a crisis about its own workforce. In the 2010s, it was the rise of self-serve BI: “If business users can build their own dashboards, what happens to the analyst?”
In the early 2020s, it was the Modern Data Stack: “If anyone can spin up a pipeline with three clicks, what happens to the data engineer?”
Both conversations produced more noise than resolution, because the underlying question was framed incorrectly. The question was never will these roles survive? The question was always what will these roles become?
The AI conversation is following the same pattern, with higher stakes and louder volume. LinkedIn is full of confident predictions: data engineers will be obsolete within three years, AI will write all the SQL, or a single prompt engineer will do the work of an entire analytics team.
On the other side, equally confident reassurances: data people are safe because AI cannot understand business context, the fundamentals don’t change, or learn dbt and you will be fine.
Both camps are looking at the wrong starting point. The question is not whether data roles survive. The question is what problem those roles will be solving and for whom. The answer to that question is the answer to what the data team actually looks like in an organisation that is serious about AI.
The answer is not fewer or more data roles, but rather different ones. Designed around a fundamentally different consumer of data.
To see why, we need to go back to basics.
What a Data Role Is in Today’s Context
Forget the job titles. Analyst, engineer, scientist, architect, and so on. And ask what every data role has in common.
Every data role exists to solve a version of the same problem:
…getting the right information, in the right form, to the right consumer, at the right time, in a way the consumer can trust and act on.
That sentence contains four variables: information, form, consumer, trust. A data role is defined by which of these variables it primarily owns, and for which consumer.
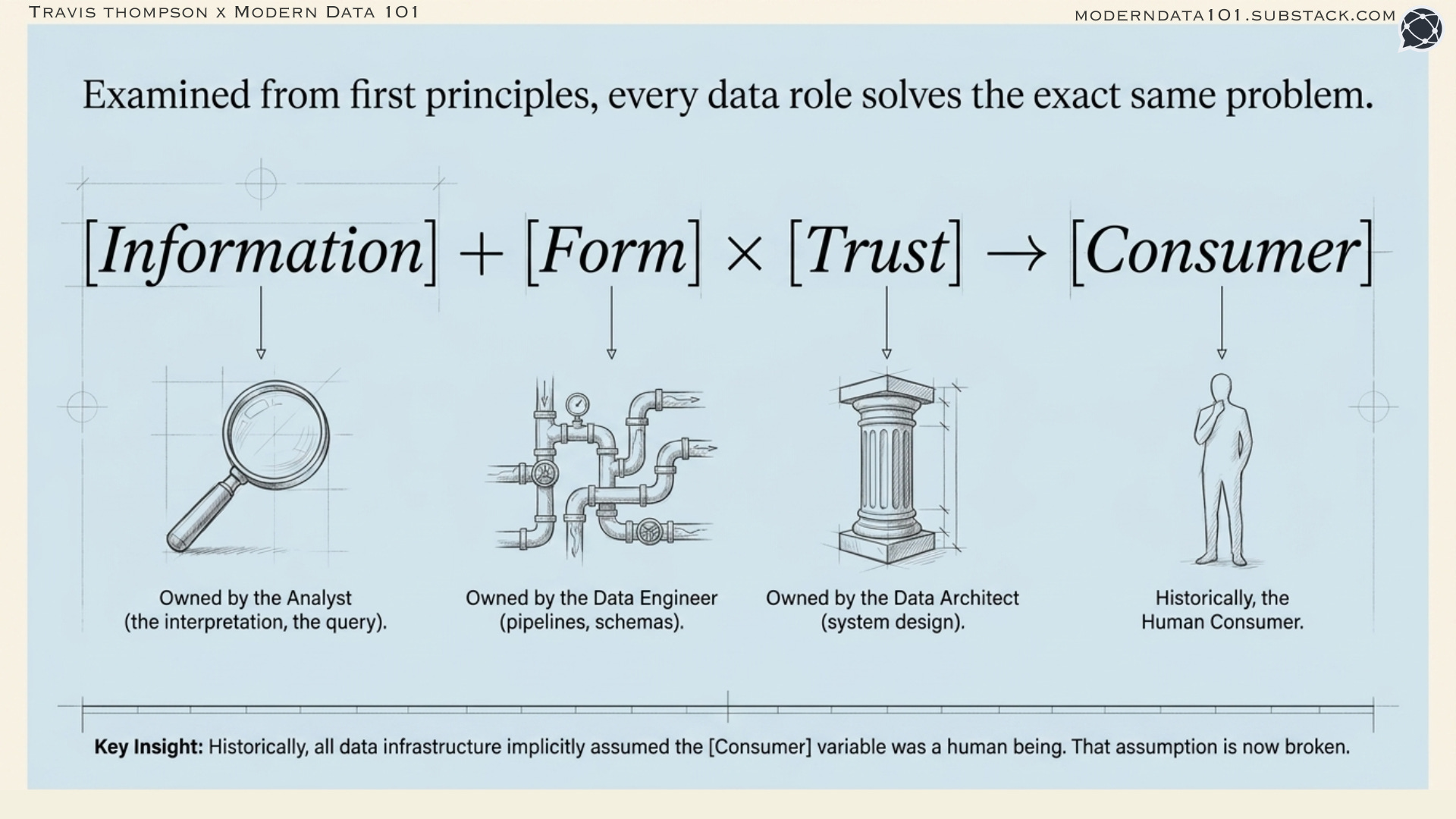
The data engineer owns form: pipelines, schemas, transformation, the infrastructure that makes data accessible and reliable.
The analyst owns information: the interpretation, the query, the question being asked.
The data scientist owns inference: drawing signal from noise, building models that predict what raw data cannot directly reveal.
The data architect owns structure: the design of systems that make all the other roles possible.
What all of these roles historically assumed, without articulating it, is that the consumer is a human being. A human who can tolerate ambiguity, ask follow-up questions, apply institutional knowledge, and use judgment to fill the gaps in what the data explicitly says.
This assumption is now wrong. Or rather, it is incomplete.
What Changed: The Arrival of the AI Consumer
AI agents are not AI assistants that sit passively waiting for a question, but autonomous systems that take actions, invoke tools, query data, and make decisions. These are the entities that are becoming active consumers of enterprise data.
This is not a future state. It is the present state, and it is accelerating.
An agent tasked with monitoring inventory will query stock levels autonomously. An agent managing customer communications will pull CRM data without human instruction. An agent generating financial summaries will invoke the data warehouse directly, interpret what it finds, and act on that interpretation.
These agents do not browse a dashboard and apply judgment. They issue queries, receive results, and proceed at machine speed, at scale, without the interpretive buffer a human analyst provides.
This creates a problem with no precedent in the history of the data profession.
A human analyst who encounters a column called
flag_Acan ask what it means. An AI agent encounteringflag_Awill infer what it means and proceed confidently, correctly or not.
The tolerance for ambiguity that humans bring to data, the ability to pause, question, and verify, does not exist in autonomous systems. An agent does not slow down because the data is confusing. It continues, using whatever context it has available, producing outputs that look authoritative regardless of whether the inputs were coherent.
This changes what data infrastructure must provide. And it changes what data roles must do. The data stack was built to serve human consumers.
The data team must now rebuild it, or at least extend it, to serve AI consumers. Those two consumers have almost nothing in common.
The New Map: Roles the Agentic Era Is Creating
What follows is not a list of job titles that will appear on LinkedIn. Some of these already exist in advanced data organisations. Some are being created under different names.
What they share is a common origin: they exist because AI consumers of data have requirements that human consumers never imposed.
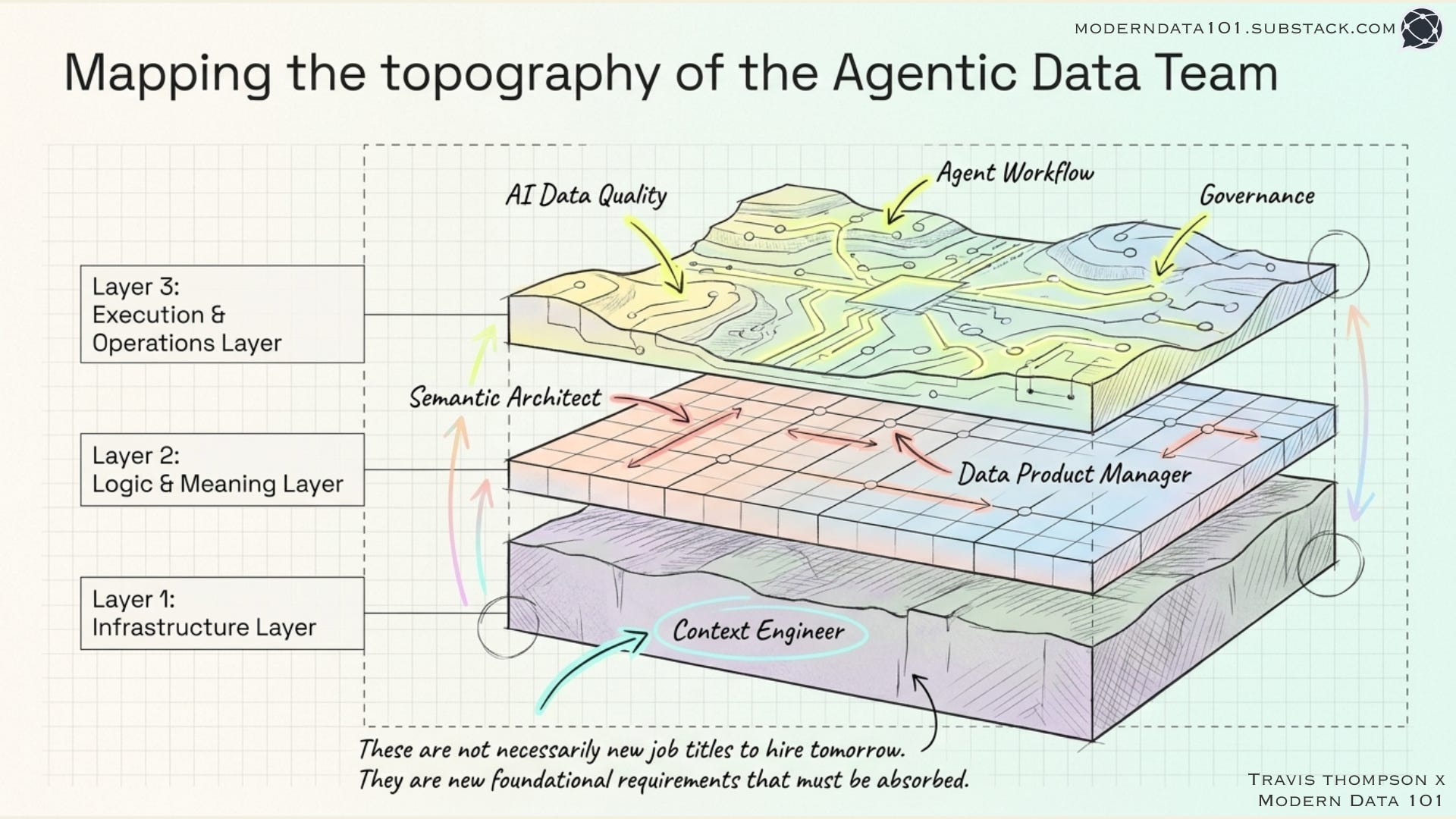
1. The Context Engineer
This is the most important new role in the data profession, and it barely existed a year ago in the broader market.
A Context Engineer’s job is to design and build the systems that give AI agents the information they need to operate correctly: not just the data itself, but the meaning wrapped around it.
What does this column represent?
What are the known exceptions?
What is the business definition of “customer” in this domain, as opposed to “prospect”?
What should an agent infer from a null value here versus a null value there?
Documentation is written for humans who can read, interpret, and apply judgment. While context engineering embeds machine-readable meaning into the data infrastructure itself (in contracts, in metadata, in ontologies, in the semantic layer), so that an agent consuming the data gets the interpretive scaffold it needs to use that data correctly.
The skills required are unusual: deep knowledge of how AI systems process information, combined with a rigorous understanding of the business domain, combined with the ability to model meaning formally.
It sits at the intersection of data architecture, knowledge engineering, and cognitive science.
2. The Data Product Manager
This role exists at the boundary of the data stack and the business, and it is becoming structurally more important as organisations move from raw datasets to managed data products.
A data product is not a dataset with a dashboard attached. It is a discrete, managed unit of data infrastructure with
explicit contracts (what it promises to deliver),
quality guarantees (what standards it maintains),
semantic definitions (what its fields mean, formally and consistently),
defined consumers (who it serves and for what decisions),
and ownership (who is accountable for it).
Managing this is a product management problem. The Data Product Manager owns the lifecycle of a data product: understanding consumer needs (human and agent), defining what the product promises, working with engineers to build and maintain it, ensuring the contracts are honoured, and retiring the product when it no longer serves its purpose.
The discipline is borrowed from software product management, but the domain is entirely different. Software products serve user experiences. Data products serve decisions, which means the quality standards, the contract design, and the failures are all different.
As AI agents increasingly select and consume data products autonomously: discovering them through catalogs, evaluating their contracts, deciding whether to trust them, the product thinking that goes into a data product becomes directly load-bearing for whether AI-driven workflows succeed or fail.
3. The Semantic Architect
The semantic layer debate (where does business logic exist in the stack) has been running for a decade. The agentic era has resolved it, or at least made the stakes clear enough that organisations can no longer defer the answer.
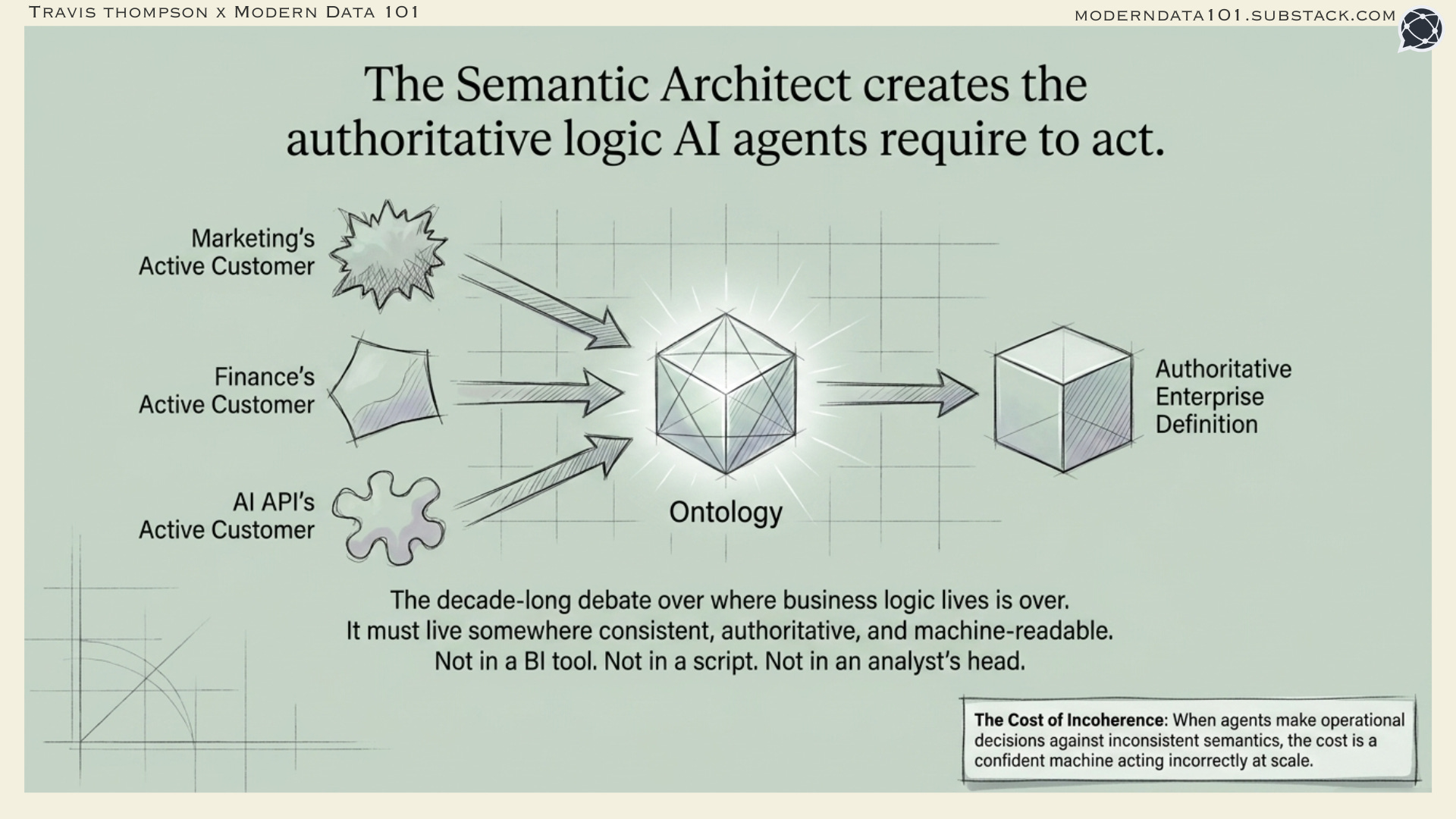
Business logic must live somewhere authoritative, consistent, and machine-readable. Not in a BI tool that only a BI developer can access. Not in a transformation script that encodes one team’s interpretation of “revenue.” Not in an analyst’s head. Somewhere that an AI agent can reach, query, and trust.
The Semantic Architect designs and maintains this layer. They are responsible for the consistency of business definitions across all systems and all consumers. They decide that “active customer” means the same thing in the marketing data product, the finance data product, and the agent-facing API.
They design the ontology, or the formal structure of entities and relationships, that gives the data semantic coherence. They resolve conflicts when two domains define the same concept differently, which they always do.
This role is not new in concept. Knowledge engineers and ontologists have existed in academic and specialised enterprise contexts for decades. What is new is the enterprise urgency.
🔖 Something interesting for this role:

4. The AI Data Quality Engineer
Data quality engineering has always existed. What is new is the nature of the failure modes that matter.
When humans consume data, quality problems are often visible. An analyst who sees a metric jump 400% overnight asks whether something went wrong. A business user who encounters a report that contradicts last week’s numbers asks for an investigation. Human consumers provide a layer of sanity checking that is invisible precisely because it works.
AI agents do not provide this. Yet. An agent that receives a data quality failure, like a schema change, a null where a value was expected, or a duplicated row that inflates a metric, will proceed with whatever it received, potentially cascading that failure through an entire automated workflow before any human notices.
The AI Data Quality Engineer designs for this. Their work is not just validating that data conforms to expected ranges and schemas (that is table stakes). Their work is designing quality frameworks specifically for machine consumers: automated detection of the failures that agents cannot self-correct for, quality contracts that make promises machine-readable, and observability systems that catch degradation before it propagates through agentic workflows.
5. The Agent Workflow Architect
As organisations deploy AI agents to perform data-intensive tasks, someone needs to design the workflows those agents operate within. This is not a data engineering role in the traditional sense. It is closer to a systems design role for autonomous processes.
The Agent Workflow Architect answers questions like:
Which decisions in this workflow should an agent make autonomously, and which require human review?
What happens when an agent encounters data it cannot interpret?
How are agent actions logged, audited, and reversible?
How do multiple agents operating on the same data coordinate to avoid conflict?
What is the fallback when an agent fails mid-workflow?
These are not questions most existing roles are designed to answer. The data engineer is focused on the pipeline. The ML engineer is focused on the model. The data architect is focused on the system design. The Agent Workflow Architect owns the space between these houses (the operational logic of autonomous data processes), which is a genuinely new design problem.
🔖 Related read

6. The AI Governance Specialist
Governance is not new. What is new is what governance must govern.
Traditional data governance was primarily about access: who can see what, under what conditions, with what audit trail. This remains important. But agentic AI introduces a layer of governance that access controls alone cannot address: the governance of automated decisions made against data.
When an AI agent acts on data (classifying a customer, flagging a transaction, generating a recommendation), that action is a decision. In many industries and jurisdictions, decisions have accountability requirements: who made this decision, on what basis, using what data, subject to what review? An automated agent that cannot answer these questions is a governance liability.
The AI Governance Specialist in the agentic era is responsible for ensuring that decisions made by AI systems using enterprise data are auditable, explainable, and compliant. They work at the intersection of legal and regulatory requirements, data architecture, and AI system design. The role requires a combination of technical literacy (enough to understand how the agent consumed the data) and policy literacy (enough to know what the regulation actually requires).
This is not a soft role. As AI regulation matures, and it is maturing (unevenly but consistently across jurisdictions), organisations that cannot demonstrate governance of their AI-driven data processes face real legal and reputational exposure.
The Roles Being Eliminated Redefined
Not every role in the data profession is being replaced. Most are being elevated, if the people in them are willing to move.
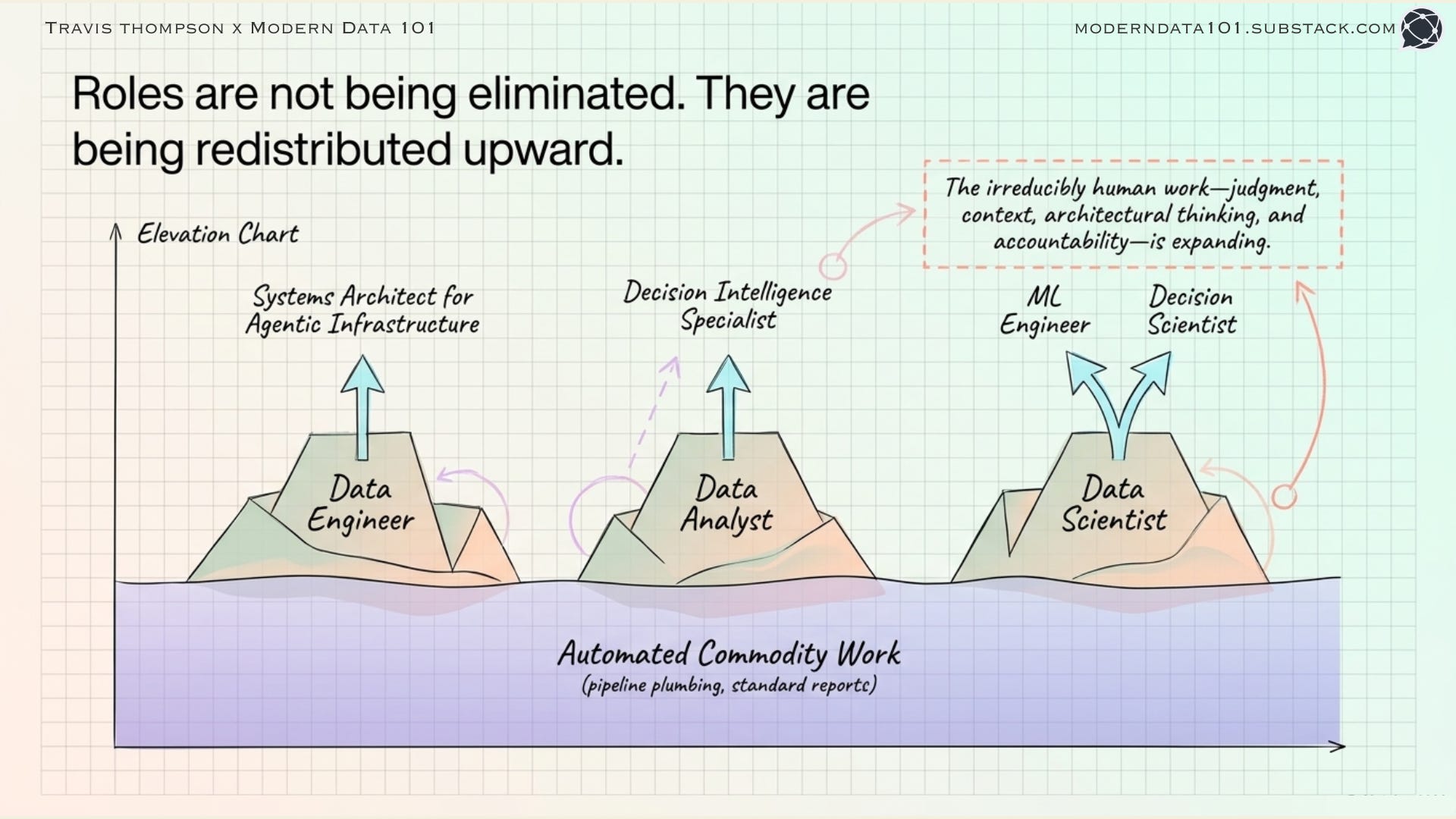
The Data Engineer is becoming a systems architect for agentic data infrastructure. Pipeline plumbing, the task of moving data from A to B reliably, is increasingly automated. What remains, and grows in value, is the architecture: designing systems that serve AI consumers, building the metadata and contract infrastructure that makes agent-consumable data products possible, and managing the complexity of a stack that now serves both human and machine consumers simultaneously.
The Data Analyst is becoming a decision intelligence specialist. The commodity work of pulling data and building standard reports is being automated. What remains is the highest-value part of the analyst’s original job: understanding what decisions actually need to be made, designing the frameworks for making them well, evaluating whether AI-generated analyses are correct and appropriately contextualised, and translating between business questions and data systems.
The Data Scientist is bifurcating. One branch moves toward ML Engineering: the operationalisation and maintenance of models in production, which is growing in complexity as AI systems proliferate. The other branch moves toward what might be called decision science: the application of statistical and causal thinking to evaluate whether AI-driven decisions are actually achieving the outcomes they were designed for.
The common thread: the commodity work within each role is being automated. The irreducibly human work (judgment, context, architectural thinking, accountability) is expanding. The roles are not being eliminated, but being redistributed upward.
Practical Implications of the New Data Roles
The practical implication of this map is not that organisations need to hire six new job titles immediately. Most of these functions will initially be absorbed by existing team members with the range and intellectual curiosity to expand into them.
What the map implies for organisational design:
Think in terms of consumers.
The traditional data team was organised around what it produced: pipelines, reports, models. The data team that serves an agentic organisation needs to be organised around who consumes its outputs, and to recognise that AI agents are now first-class consumers with requirements as real and demanding as any business user.
Invest in the semantic layer before the AI layer.
Every new AI consumer added to a semantically incoherent data environment multiplies the cost of that incoherence. The organisations that are getting the most value from AI-driven data workflows are the ones that did the foundational work first: consistent business definitions, managed data products, contracts that travel with the data. The AI layer compounds whatever is underneath it, which arguably should be the most convincing argument for fixing what is underneath before adding more on top.
Create explicit ownership for data products.
In most data organisations, datasets have owners. Data products with defined contracts, quality guarantees, semantic definitions, and consumer relationships do not. The Data Product Manager role exists to fill this gap. Without it, the discipline of maintaining data products over time defaults to no one, and data products decay into datasets.
Build governance for decisions.
The governance frameworks most organisations have in place were designed to control who sees data. They were not designed to audit what decisions were made with data, or to ensure those decisions are explainable and compliant. This is a structural gap that the agentic era will expose, and the cost of exposure will be proportional to how much of the organisation’s operations are running on AI-driven data decisions.
The New Org Chart
The modern data team was built to serve the analyst and the business user. In that world, the ceiling was a well-governed, accessible, high-quality data environment. Good data in, good insights out.
The agentic data team is built to serve humans and machines simultaneously. In that world, the ceiling is a data environment where meaning is managed, contracts are honoured, decisions are auditable, and AI agents can operate with the same degree of trust that the best human analysts have earned over the years.
That is a substantially higher bar. The roles that meet it are being created now, sometimes under new titles, more often as invisible expansions of existing ones, almost always underinvested relative to their importance.
MD101 Connect ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 💬

Connect with Travis on LinkedIn 💬
From MD101 team 🧡
🌎 State of Data Products, Q1 2026
Don’t place your 2026 data bets in the dark. Discover how the best minds are leaning toward architectural resilience and trust: Read the Q1 Edition of the State of Data Products, The Catalyst.

Really like your thought process here - separating the roles. Developers can't recognize their conflict of interest. Perhaps call your "product manager" the "business architect" instead. Remove all technical responsibilities other than testing from the role. Let them think entirely in the business modeling world. Great read.
ZH