
dbt for Data Products: Cost Savings, Experience, & Monetisation | Part 3
Part 3 of the Series on Leveraging Your Existing Stacks/Tools to Build Data Products


Before you dive in, in the interest of saving your time, we want to call out that this piece is a little longer than usual since it focuses on some features, limitations, and solutions of the tool at hand. You can view the points we’ve covered at a glance in the TOC below.
This read is ideally suited for data leaders or data engineering leads who are focusing on optimising their dbt investments and want to enhance either of:
Cost savings
Data monetisation efforts
Overall experience of users and data consumers
If you’re new here, feel free to refer to the previous parts in this series on Leveraging Existing Stacks/Tools for Data Product Builds:
Part 1: Cost-optimisation with Data Products on Snowflake
Part 2: Snowflake for Data Products: Data Monetisation & Experience
Table of Contents (TOC)
Introduction & Context
The Need to Shift Conversations from ETL to Data Products + Gaps in dbt
Data Products: One of many outcomes of Self-Service Platforms, but an Important One
How to Leverage Your Existing Stack (with dbt) to Build Data Products
Cost Savings
Large dbt Models May Lead to High Compute Costs
Infrastructure Costs
Maintenance, Support, & Operational Costs
Increasing Appetite for Revenue
Scale & Performance
How transformations/ETL gains a new stage and is ready for scale
Enhancing Experience for All (customers & business operatives)
Jumping In ⬇️
Undeniably, dbt is a data developer’s best friend. A product is known for how easily it changes the lives of its users, and dbt has done it without fail. There was a time when transformations used to be a big task and bottleneck for centralised data engineering teams. dbt stepped up and ensured that there was a much easier way to do things.
Instead of complex Spark functions, developers could suddenly construct transformations with simple SQL statements and experiment with multiple logic threads in parallel with continued testing. dbt has repeatedly come through for data analysts/developers by enabling:
Ease of custom reusable logic with a modular approach (which we love)
Automated testing
Ease of transformation deployments
Transformation documentation
and honestly, so much more, including version control, incremental views, and CI/CD for transformation logic.
Over the better half of the last decade, we had the opportunity to communicate with large-scale enterprises, which surfaced that there are pockets of dbt popularity. While there are some teams and initiatives which adopted the data build tool for batch transformations, there may be other ad-hoc systems or tool stacks running for other tracks, say for streaming data, or for more legacy transformation stacks that are common in enterprises.
dbt is a personal favourite, and we want to take this opportunity to talk about how we were able to enhance its powers with our implementation of Data Developer Platforms as an underlying unification layer.
Gaps in How Users Leverage dbt: Conversations Need to Shift from ETL to Data Products
Before, diving in, we want to highlight some recurrent user pain points of dbt that we’ve come across. dbt is a transformation tool and shouldn’t be held responsible for resurrecting the entire data stack or data operations.
While its offerings are quite user-friendly when it comes to batch transformations, we want to respectfully highlight some gaps that a tool, despite its advanced offerings, can face when integrated with a mostly chaotic organizational stack.
Moreover, as someone also pointed out in a data engineering forum, it’s often not the shortcomings of the tool itself but the stack it is a part of. Even with the purest intentions of tool builders, the issues stem when the independent tool interacts with the broader data world, especially when the world is more or less broken.
It’s important to note that a tool is an independent entity in a data stack and, therefore, has its limitations when interacting with other independent entities or the overall data ecosystem.
For context, here are a few threads we’ve come across from the data engineering community at large:



A very brief overview of some of these gaps when ETL becomes part of the big picture or the end-to-end journey of data:

By combining dbt with a Data Developer Platform, organizations can leverage the strengths of dbt in data transformations while benefiting from DDP's self-serve infrastructure design (fit for paradigms like Data Products), comprehensive orchestration, real-time processing, collaboration, and governance features, creating a more robust and efficient data ecosystem.
But First, What is a Data Developer Platform?
CONTEXT
DDPs are a modern way to run data engineering teams, strongly inspired after the thriving Internal Developer Platforms standard and customized specifically for the dynamic and evolving component of transient data.
Data teams are drained from continuously plumbing integrations and fragile pipelines, which leaves little to no time to focus on the real deal—data and data applications. Businesses that have a good grasp of data realise that today, data makes the difference between winning and losing the competitive edge. Many data-first organizations understood this long ago and dedicated major projects to becoming data-first.
The likes of Uber, Google, and Airbnb have shown an inspiring discipline around data. However, replicating data-first organisations that took years to develop their platforms customised to their own data stacks is NOT the solution since their stacks were and are catered to their specific internal architectures. Instead, the solution is to build in accordance with your existing internal infrastructure.
WHAT
A Data Developer Platform (DDP) is a unified infrastructure specification to abstract complex and distributed subsystems and offer a consistent outcome-first experience to non-expert end users. In short, it’s the standard for self-service data infrastructure.
A DDP can be thought of as an internal developer platform (IDP) for data engineers and data scientists. Just as an IDP provides a set of tools and services to help developers build and deploy applications more easily, DDP provides a set of tools and services to help data professionals manage and analyze data more effectively.
The primary value-add of a DDP lies in its unification ability—instead of having to manage multiple integrations and their overlapping features, a data engineer can breathe easy with a clean and single point of management.
In analogy to IDP, DDP is designed to provide data professionals with a set of ready-to-use building blocks that they can employ to build data products, services, and data applications more quickly and efficiently.

Data Products: One of Many Outcomes of a DDP, but an Important One
A data developer platform is a flexible base and allows users to materialise desired solutions or a plethora of data design patterns on top of it (by virtue of its building blocks). One of these design patterns, and of course, the one we highly advocate, is Data Products.
There are multiple ways to arrive at a data product depending on the organisation’s philosophy. One might choose to implement a data mesh pattern, while another might go for a data fabric. Some might discard either of the above to build a minimum viable pattern that works for their use cases. A DDP inherently comes with a minimum viable pattern to enable the Data Product construct.
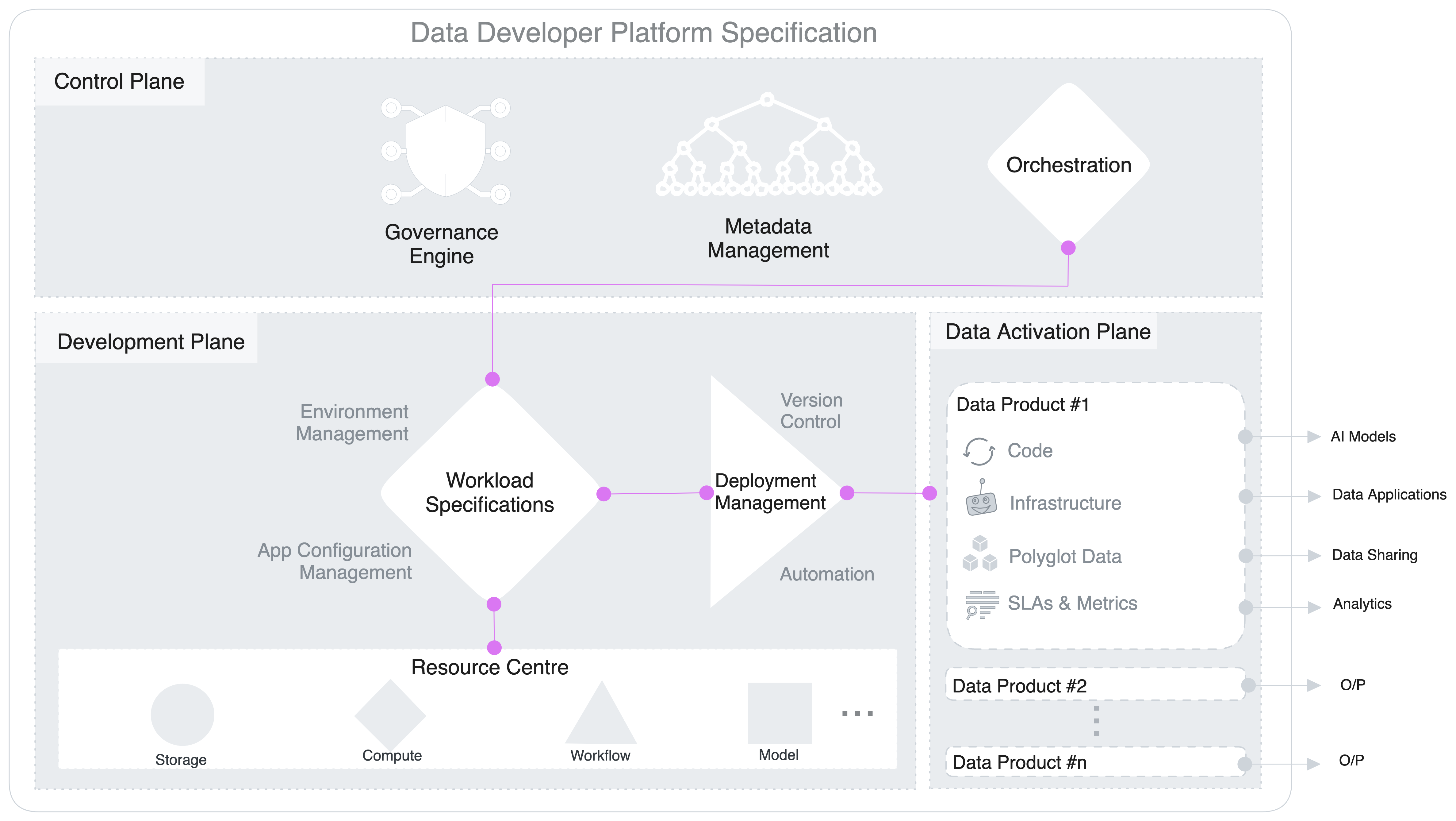
Let's look at the definition of a data product. It is an architectural quantum with three components: The data & metadata, the code handling the data, and the infrastructure powering both components. A bare minimum DDP is the infrastructure component, while a higher-order DDP comes with minimalistic templates for the code (Data Products in our case).
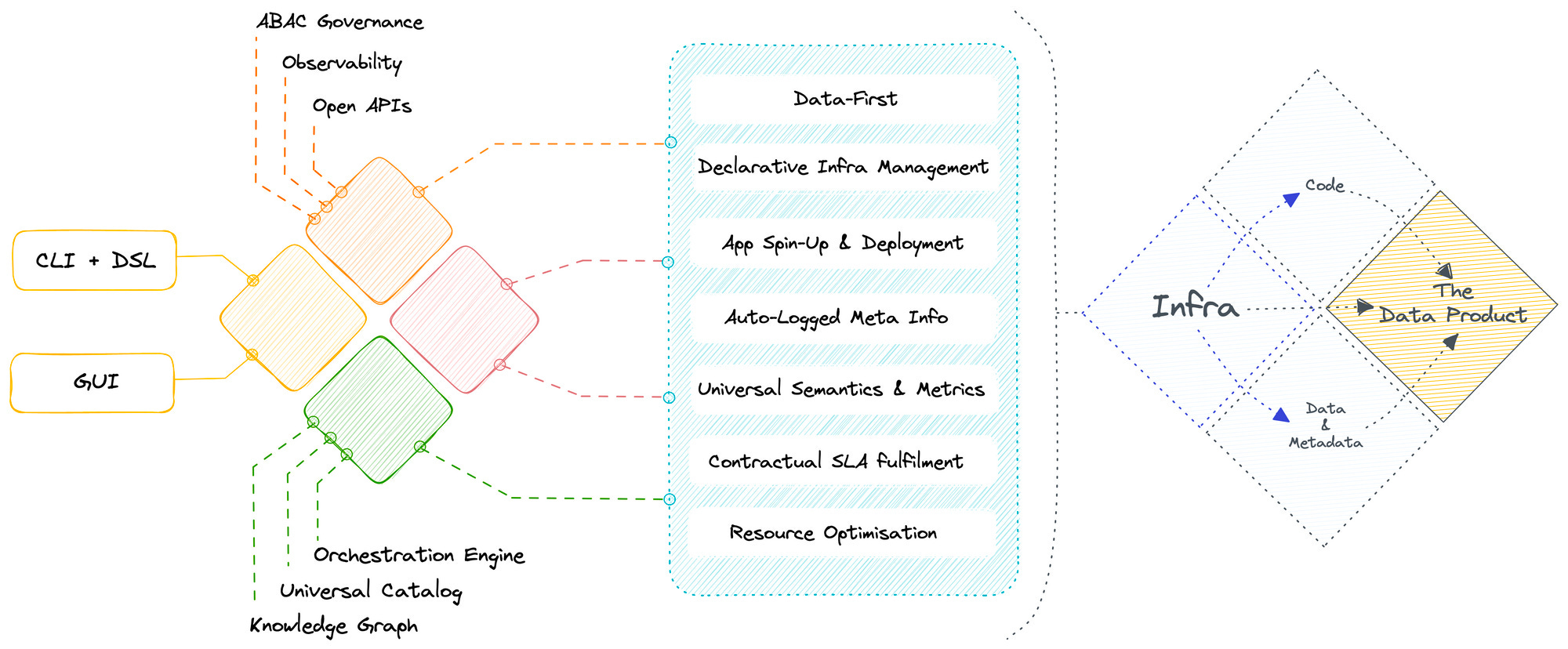
How to Leverage Your Existing Stack (with dbt) to Build Data Products
Let’s look at this from the perspective of the three major business-favoured forks 🔱:
Cost Savings
Increasing Revenue Appetite
Enhancing experience for all (customers and business operatives)
Cost Savings 💰
The cost of running dbt in large organizations like retail (e.g., GAP, Walmart), finance (e.g., Goldman, JP), or healthcare enterprises (e.g., UnitedHealth, CVS) varies significantly based on several factors, including the size of the data, the number of users, and the complexity of the transformations.
There are often pockets of dbt popularity. While there are some teams and initiatives which adopted the data build tool for batch transformations, there may be other ad-hoc systems or tool stacks running for other tracks, let’s say for streaming data or legacy transformation stacks that are common in enterprises.
dbt does not provide features for automation and resource/cost management across your data stack, which is where a DDP layer comes in. Here are some key considerations and typical costs where a DDP (self-serve infra) + Data Product duo helps with cost optimisation.
Large dbt Models May Lead to High Compute Costs
Many large enterprises use Snowflake as their data warehouse. The cost here depends on the amount of compute used. For example, running large dbt models can lead to high compute costs. Snowflake charges based on the compute usage per second, and heavy usage can lead to significant costs, sometimes running into hundreds of thousands of dollars annually.
Especially with the rise of GenAI and AI demand from customers, the experimental appetite of orgs is bound to increase, leading to multiple experimental transformations, and given the usual high volume of data for AI training, these are indefinitely going to be heavy transforms.
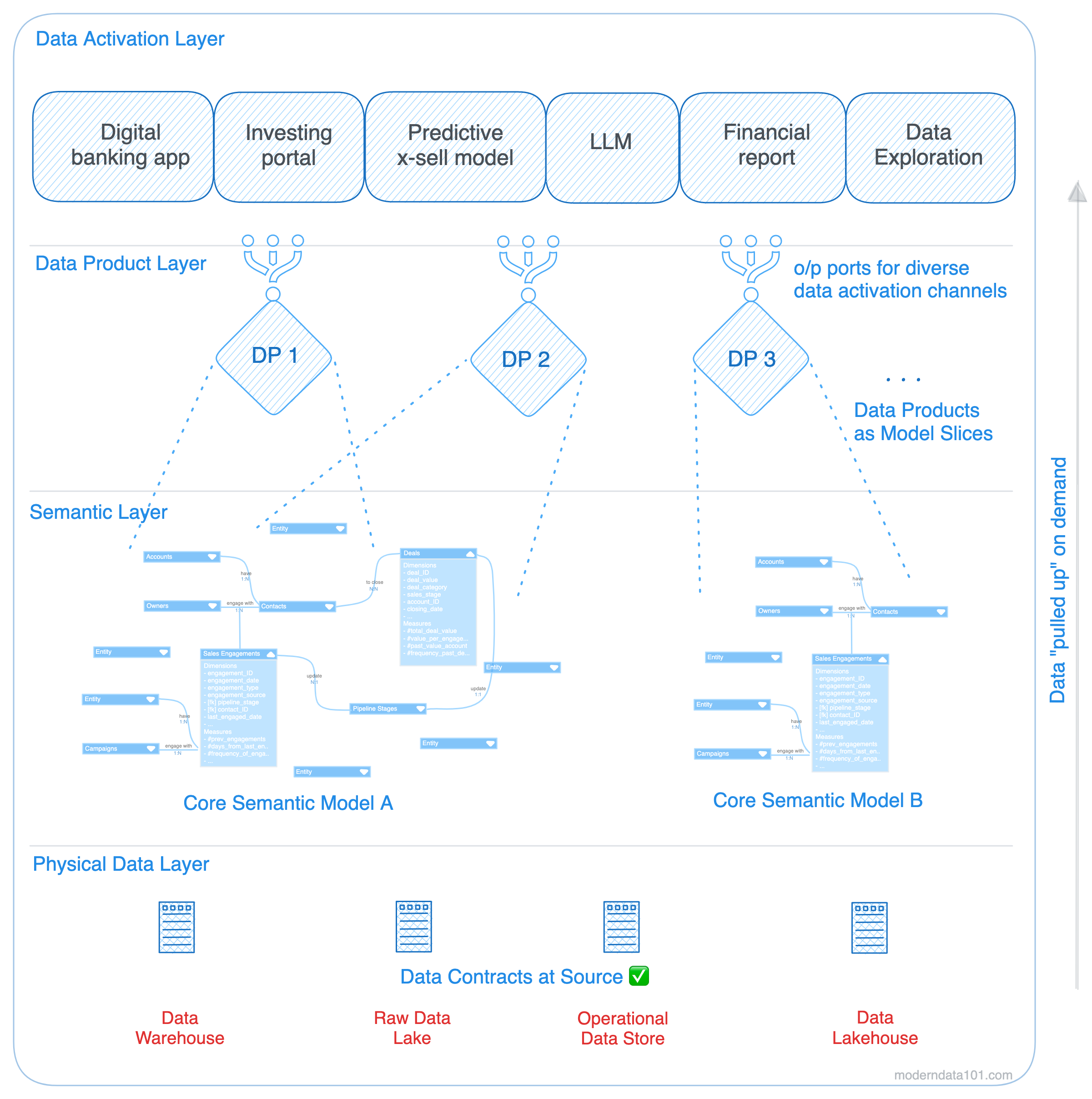
DDP successfully decouples the physical data layer and the data activation layer by introducing data products as the glueing agent. Two pieces of bread will fall apart, just as we’ve witnessed the chemistry between data activation and physical data fall apart for years—unless it’s a PB&J!
Model-First Data Products (MDPs) enable the organisation to identify and surface up model slices (including transformations, quality checks, and SLOs) that would help create a direct impact on target metrics. Additionally, MDPs also facilitate a pull mechanism where only the necessary data is processed or transformed. In summation, it:
reduces the number of transformations through business-driven prioritisation
enables on-demand transformation when an app or user in the data activation layer calls for it (pull mechanism)
enables partial runs on very niche goal-driven slices of the data model instead of running large models every time for a few or novel business queries
deprecates views and branches of heavy models which are no longer in use
📝 Related Reads
Learn how MDPs help in cost optimisation with Snowflake
Infrastructure Costs
Running dbt often requires robust infrastructure to support the ETL processes. This includes costs related to cloud infrastructure (e.g., AWS, Azure, GCP) where the data is stored and processed. These costs can include storage, networking, and additional services required to maintain the data pipeline.
By facilitating metric/purpose-aligned data products or Model-First data products, organisations:
Save storage costs by moving data only when specifically called upon by the activation layer
Save compute costs by only running case-specific transformations (slices of core semantic models as data products)
Auto scale DDP and cloud resources for automated as well as customisable resource optimisation
Maintenance, Support & Operational Costs
In large organizations, maintaining a complex dbt setup might require a dedicated team to manage complex pipeline dependencies, integrations with other tools and entities, and time-taxing iterations with different teams for context, which can add to the overall costs.
Other operational costs include monitoring, logging, and incident management tools that integrate with dbt to ensure smooth operation. These tools might include platforms like Datadog, New Relic, or custom monitoring solutions, which add to the operational expenses.
DDP as a platform layer removes such operational, maintenance, and integration overheads. It acts as a standard interface where you integrate dbt once to make it interoperable with any and all entities in a data stack. Integrate once to integrate with all. Given DDP forms the self-service infrastructure component of Data Products, it acts as an interoperable interface facilitating all components participating in the Data Product, including transformation code written in dbt or any other transformation stack.
Increasing Appetite for Revenue 📈
Scale & Performance
DDP optimizes resource allocation and performance across the data stack, ensuring scalability. DDP, as a self-service layer, orchestrates the entire data product lifecycle (from source to data activation) through a series of progressive layers. This enables data to gain a purpose-aligned structure, while not losing access and operational flexibility along the way.
This progressive build-up of data, directed towards a specific business purpose, enables organisations
to adopt data product ecosystems non-disruptively in a gradual manner
create kickstarter MVPs of data products through templates (just like, say, kanban template in JIRA)
evolve Data Products over time when usage patterns, associations with metrics, and more advanced metrics pop up
launch multiple data products within turnaround time as short as a few weeks (comparatively, launching designs like data products with more traditional stacks like MDS or on-prems could take over 6 months)
We recently came across a very interesting comparison of Data Product Ecosystems to the Medallion Architecture brought forth by Francesco de Cassai. This is a golden concept/approach which we found extremely apt to explain the non-disruptive nature of these systems - where it doesn’t tamper with data flexibility, all while enabling incremental alignment and transparency of data efforts with direct business impact.
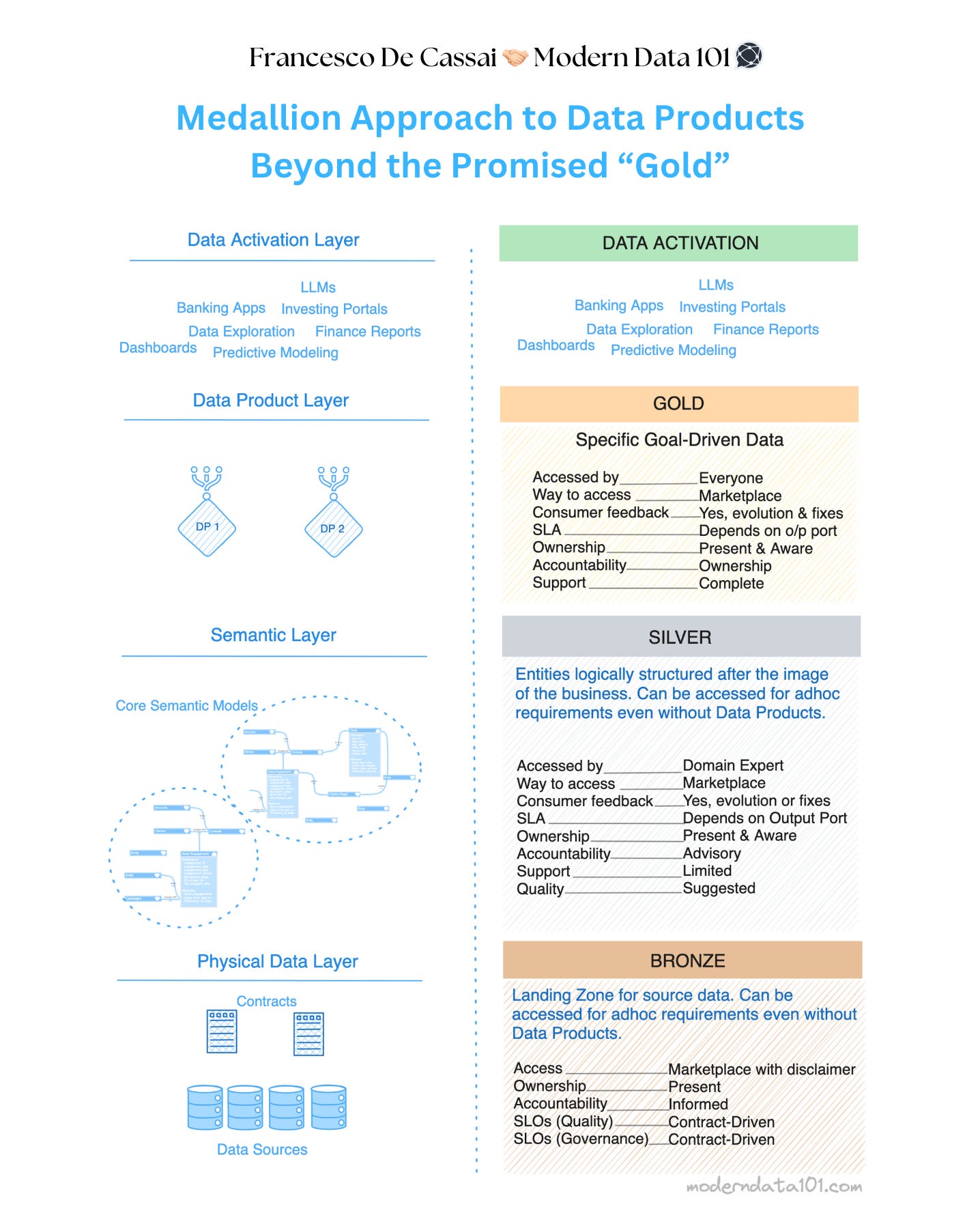
BRONZE🥉
Landing Zone for source data and contractual entry-point to the product. Data in this layer can be accessed for ad-hoc requirements even without building goal-driven Data Products, thus, preserving the flexibility of data.
SILVER🥈
Entities logically structured after the image of the business. These logical models be accessed & leveraged independently for ad-hoc requirements even without building goal-driven Data Products. This ensures flexibility for data consumers along with context from the logical model.
GOLD🥇
This band is for specific goal-driven initiatives where data products shine. This layer serves the high-weighted business goals by channelling data processed & validated as decreed by the governing business metrics. For instance, a data product for specifically identifying gaps in a sales cycle or cutting down duration of the sales funnel. (e.g. of driving metrics: avg_deal_value, #deals, and #revenue_generated)
How Transformations/ETL Gains a New Stage and is Ready for Scale
DDP enables you to comfortably continue transformation exercises and scripts in dbt. The magic or the secret behind scaling fast with data products is in the unified/interoperable interface, which lets your transformation stack interoperate and talk to multiple native entities in DDP, as well as external tools/entities/pipelines plugged into this platform layer.
A more complete metadata model
Your transformation stack is now visible and part of the centralised metadata model. We can write a whole series on how surfacing up in the metadata model changes the impact of data, but that’s for another time.
Unified orchestration & governance
You can monitor, log, govern, version control, and orchestrate dbt pipelines along with all stages of the data pipeline from a centralised plane, along with pipelines and tools from other segments of the data stack.
All data product code under one hood
Essentially, it gives you control of a clean vertical slice in the data stack, where all resources, tools, and pipelines are serving the data product’s objectives and can be controlled, viewed, and accessed from one interface.
Unrestricted Transformations
While dbt is apt for batch processing, it is unsuitable for streaming data. DDP can handle real-time data ingestion and processing, complementing dbt's batch processing strengths. All while streamlining data under one hood instead of having to manage multiple tools or transformation stacks.
Complete Data Product Lifecycle Management
While dbt only allows automation and management of transformations, DDP helps go a step further to aid and automate the entire data product lifecycle, which may or may not include transformation code running in dbt. Here’s a view of the entire data product lifecycle at a glance. Or you could refer to our more popular detailed reads on each of the stages of the lifecycle: Design, Develop, Deploy, Evolve.

Enhancing Experience for All (customers and business operatives)
Most of the aspects of user experience and consumer experience have been discussed directly or indirectly in the above segments, but we’ll highlight a few here which specifically pertain to the experience angle.

End of Part 3 - Stay Tuned for Upcoming Segments!
Within the scope of this piece, we have covered the monetisation and experience angle. If you’re new here, feel free to refer to the previous parts here:
Part 1: Cost-optimisation with Data Products on Snowflake
Part 2: Snowflake for Data Products: Data Monetisation & Experience
Stay tuned and revisit this space for upcoming pieces where we cover how to build data products by leveraging common workplace tools such as Databricks, ADF, or Tableau!
 | A guest post by
|