
Build Data Products With Snowflake | Part 1: Leveraging Existing Stacks
Optimising Snowflake Cost, Integrating Snowflake Sources, and Driving Faster Business Results!



Before diving in, we want to share a small achievement with you all 🗞️
We’re thrilled to see more of you and have heard you loud and clear!
Check out the milestone post on LinkedIn!
With this new milestone, we are kickstarting a new series that will explore the practical implementation of data products with your existing toolset! We cannot thank you enough for helping us build this amazing community on product thinking and practices for data, and we hope to have your continued support!
Now, let’s roll up our sleeves! 🤺
Building Data Products isn’t rocket science. While many conversations, articles, podcasts, and strategies distributed all over the data space might make you think otherwise, it’s mostly the result of information overwhelm, clashing viewpoints and approaches, and complexity that most technologists aren’t able to convey well.
In this series, we want to highlight the ease of leveraging your existing stack to get going with Data Products. This piece is ideally for data leaders who want to adopt the data product approach while staying rooted in big investments like Snowflake, Dbt, Databricks, or Tableau.
We’ll kick this off with a favourite: Snowflake!
What’s the Motivation for Data Products?
Every organisation and business function is driven through three fundamental motivations:
Saving Costs
Increasing Revenue & ROI
Enhancing experience for all (customers and business operatives)
How does a data product approach play out to boost the above?
Within the scope of this piece, we’ll primarily cover:
✅ the cost optimisation angle
✅ kickstarter: Integrating Snowflake and using it to activate data products
✅ and sprinkle a little of the rest
📝 Note: In the upcoming pieces, we’ll cover the revenue and experience angle in greater detail. Keep an eye out for the next week’s edition!
To understand that, first, here’s a glimpse of what a data product strategy constitutes:
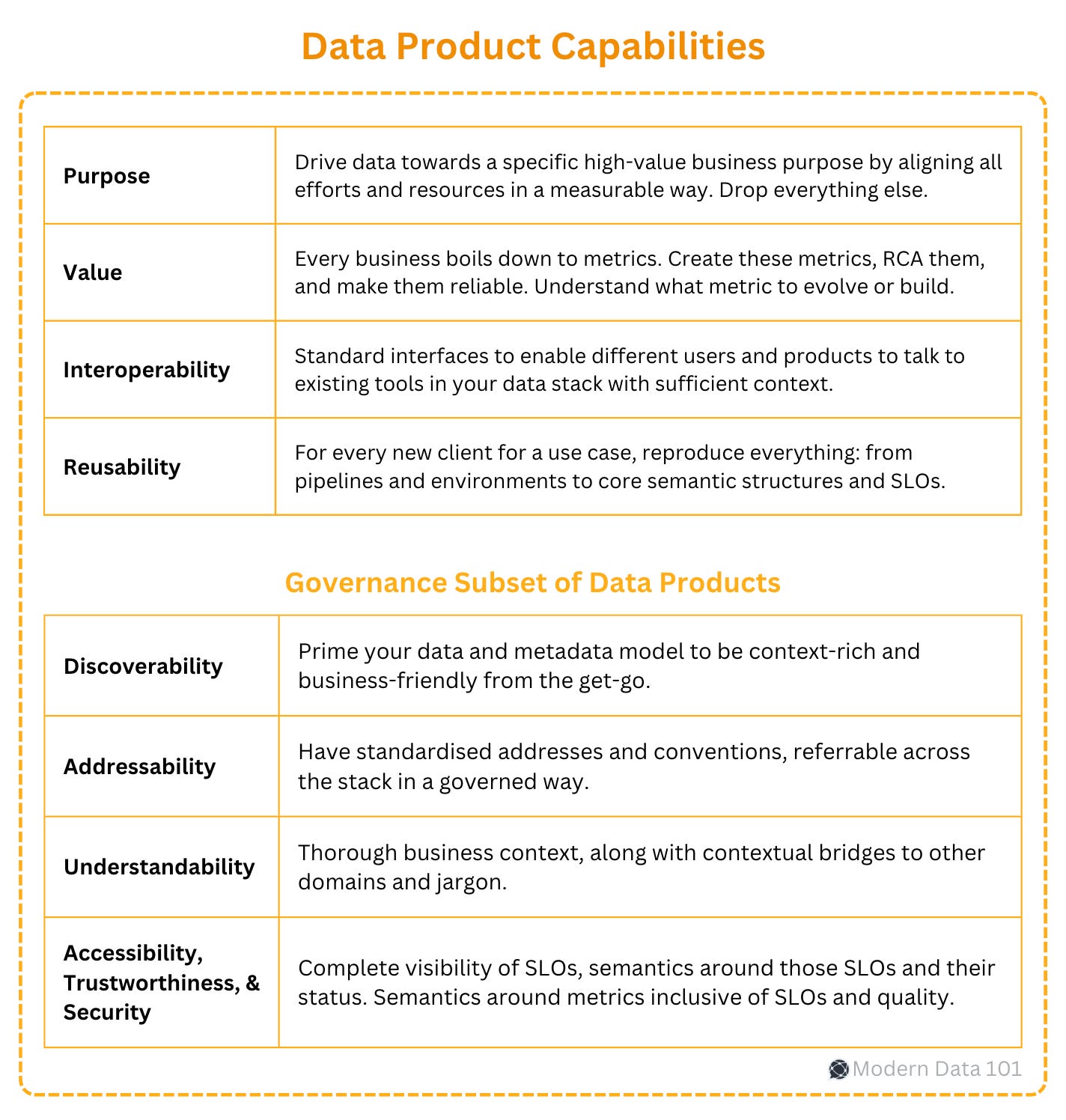
Now, let’s see how this strategy plays out for the three forks of business, specifically with respect to our chosen toolset within the scope of this piece: Snowflake
Saving Costs: The Problem ⚠️
Snowflake is a data warehousing solution with access to external market data that you can purchase on the marketplace. As Snowflake puts it, costs are incurred based on usage of data transfer, storage, and computation.

The more storage, compute, and transforms you use, the higher the cost.
While Snowflake offers state-of-the-art storage, it doesn’t offer any approach to optimise the use of these three resource buckets. In a way, as most enterprises face and would relate, their usage-based model is naturally primed to profit from higher usage, and the billing is often overwhelming.
This is why a data strategy is required to optimise how your team and organisation use such tools. To be fair, this data strategy is not the responsibility of your storage vendor, whose North Star goal is to find more users and push more resources.
Ergo, without an implemented strategy, Snowflake’s compute costs can shoot up as the data scales up. This implies restricting your data by aggregating it, which brings back the original issue of losing the pace of real-time business.
The Solution: Work Only With Purpose-Aligned Data 🎯
Data Products start with the design phase, where they define the desired business outcomes and then identify the data requirements necessary to achieve those outcomes. This enables better alignment with business goals, quicker iterations, and improved communication between stakeholders.
This means that the usage of resources for transfer, compute, and organised storage are cut down from huge unnecessary data to very specific data assets that are completely aligned with the business purpose.
How is this achieved?
We call it Model-First Data Products.
This essentially means modelling the outcome first (prototyping) and then putting the parts together to bring the product vision to life.
1️⃣ Model your key metrics - North Star Goals of the Business & how are they associated with each other and other functional/granular metrics.
2️⃣ Prototype the data product - A niche Semantic Model that powers the metric dependency tree for a specific business purpose. Example: Sales Funnel Acceleration
3️⃣ Validate the prototype with simulated data - This smart simulation cuts down the cost of extensive transfers and storage across multiple iterations with real data.
4️⃣ Materialise Product from Prototype - The prototype becomes your guiding star. Move, transform, and process data only where required.
📒 Learn more here:

Implementing the Solution: Self-Serve Layer 🎮
A self-serve layer on top of your existing tool stack is essential to data products, which is why it is also ingrained as one of the four pillars of the data mesh paradigm.
The self-service layer helps to minimise the number of data products you create by optimising the prototype deployment for data products. This means costs saved in terms of resources, time, and effort →
➡️ Fewer resources used
➡️ Minimal time invested in deploying data products
What to Self-Serve?
The self-serve layer enables you through steps 1 to 4:
1️⃣ & 2️⃣: Metric Tree & Data Product Prototype → Self-service for Business Users (Analysts), Domain Experts, and Data Product Managers
3️⃣: Prototype Validation → Self-Service for Analytics Engineers and Data Product Managers
4️⃣: Prototype Build & Deployment → Self-Service for Analytics Engineers, Data Engineers, Governance Stewards, and IT Teams.
The Self-Serve Layer becomes the “Single Point of Truth” for your data.
Business and non-technical users can understand and explore the data seamlessly through the data product prototype.
Data from various sources can be easily integrated together without having to move them physically.
Data from various sources can be correlated in real-time for easier analytics.
In essence, the Self-Serve layer is a layer above base tools such as Snowflake that reverses the negative effect of cost overflow, which base tools or vendors aren’t optimised for. By nature, they run costs in the opposite direction, which is neutralised through strategic layers above.
How to Integrate Snowflake with a Self-Serve Layer?
Note that integration of a Snowflake data source happens after you’ve prototyped your business purpose. Accordingly, you connect the necessary sources and run exploration for further narrowing down your data for transforms.
🔌 Connect the Snowflake source by creating an input port on a Data Developer Platform (Self-Serve Layer)
🔍 Add the port to the primary query cluster for easy data discovery and querying
✅ Self-serve necessary data quality assertions
🔐 Self-serve policies to ensure required access and masking
🌟 With the Data Product Prototype as your guiding star, construct views, dimensions and metrics by utilising and combining multiple datasets from various data sources (input ports)
🛫 Activate data for applications or analysis by running queries on top of the model-first data product
Connect Snowflake Source to Self-Service Layer
Integrating a data source to the self-serve layer is done through an input port. The input port is a resource that acts as an intermediary connecting diverse data sources by abstracting the complexities associated with the underlying source systems (credentials, schema, etc.)
The port acts as a registration point for your data source in the Self-Service Layer, which makes your data more discoverable through the following hierarchical address structure.
ddp://[input-port]:[collection]/[dataset]
You can define as many input ports as you would like for each database on your Snowflake data warehouse (including the databases created from marketplace purchases). An input port is defined through a YAML file. Here is a sample Snowflake port definition:

Discovering Data from the Input Port
You can now enlist your input ports to the query cluster in the Self-Service Layer and explore the data on the self-service layer’s all-purpose catalog. Here, you can explore not just the schema or the description of the datasets but also understand →
Lineage of the datasets
Quality tests done on the data
Fundamental statistics on the data - Profiling
Frequent queries executed on this dataset
Governance policies
Querying the Snowflake Data Source
As soon as the snowflake data source is registered, you can start querying it either through a simple query interface or even query on top of model-first data products.
Sample query on a regular querying interface:
SELECT * FROM snowflake_port1.retail.customers
Plugging into the Data Product Prototype
The data product prototype is built in collaboration with the business counterparts. In our example of sales-funnel-accelerator, it’s the sales manager and their team. The product prototype materialises in the form of a semantic model and a global metric tree built on a collaborative interface.
This prototype constitutes components the business requires: entities, dimensions, measures, metrics, relationships, and SLOs on quality and security!
Based on this prototype and exploration of available data, move, transform, or process only the data demanded by the validated✅ prototype. This saves weeks and months of unnecessary transfer and computing costs.
As we saw above, the self-service layer also ensures self-service for analytics engineers, enabling them to transform data declaratively. Transformations are abstracted, and engineers are only required to declare port destinations and transformation steps instead of writing complex transformations from scratch - saving days to weeks in this stage as well.
Data Product Activated State
Once the actual data is plugged in, businesses can run queries on top of the data products, which abstracts all complexities of underlying joins, multiple data sources, credentials, and more. An example of one such query:

Once the model-first data product is activated and ready for querying, it is also open for supplying data to other business tracks such as dashboards, ML Notebooks, data applications, or data sharing channels.
This is materialised through the same port construct- but this time in the outward direction - output ports. By consuming data directly from these output ports, the data team ensures consistent, reliable data, available at the pace of business.
Learn more about platform standards that enable the Self-Service Layer we have discussed on datadeveloperplatform.org
End of Part 1 - Stay Tuned for Upcoming Segments!
Within the scope of this piece, we covered the cost angle and how the cost is optimised through purpose-driven data enabled through data products.
Stay tuned and revisit this space for upcoming pieces where we cover the revenue and experience angles in more detail and also touch upon other common workplace tools such as Dbt and Tableau!
Author Connect 🖋️

Find me on LinkedIn!
 | A guest post by
|
 | A guest post by
|