
What Is an AI Operating System or AI OS
A POV from an Architect of the Data Operating System

A decade ago, a small group of us sat with a question that sounded almost too simple to be worth asking: why does every company have to build its own data infrastructure from scratch?
Every organisation was independently solving the same problems: connecting to sources, moving data, governing access, monitoring pipelines, serving it back out to humans and applications. Different logos, same plumbing.
Architecture is never about the tools, which we weren’t short on. We were short on a system that made the tools disappear into the background, the way an operating system makes a hard disk and a network card disappear into the background for an app developer.

Such questions led us to build DataOS: the first operating system for data. And it’s the same question, asked again, that I think explains the “AI operating system.” If you start from the same first principles, the line from one to the other is not a metaphor. It’s a direct continuation.
AI Operating Systems today are the talk of the town. YC has suggested it as a “company brain.” This is not a chatbot over documents, but a dynamic, structured map of how the company actually works: how refunds get handled, how pricing exceptions get decided, how engineers respond to incidents.
It’s the same pattern of turning scattered raw material into a governed, queryable, reusable product, applied to operational knowledge instead of tables.
First, What is an Operating System?
Forget data and AI for a second. What is an operating system, at the most stripped-down level?
It’s the thing that sits between messy, heterogeneous infrastructure and people who just want to get something done, and makes the second group never have to think about the first.
Think about your laptop. A gamer uses it to run a graphics-heavy game. An accountant uses the exact same machine to crunch a spreadsheet. Neither of them opens a terminal to manage memory allocation or talk to the disk controller directly.
The OS abstracts all of that. It gives both of them, and every app developer in between, a small set of stable primitives (files, processes, permissions, drivers) that can be composed into wildly different applications.
Nobody asks “why doesn’t the gamer need their own infrastructure team?” because the answer is obvious: a small, dedicated team builds and maintains the OS once, and everyone else gets to build on top of it. Same infrastructure with different use cases.
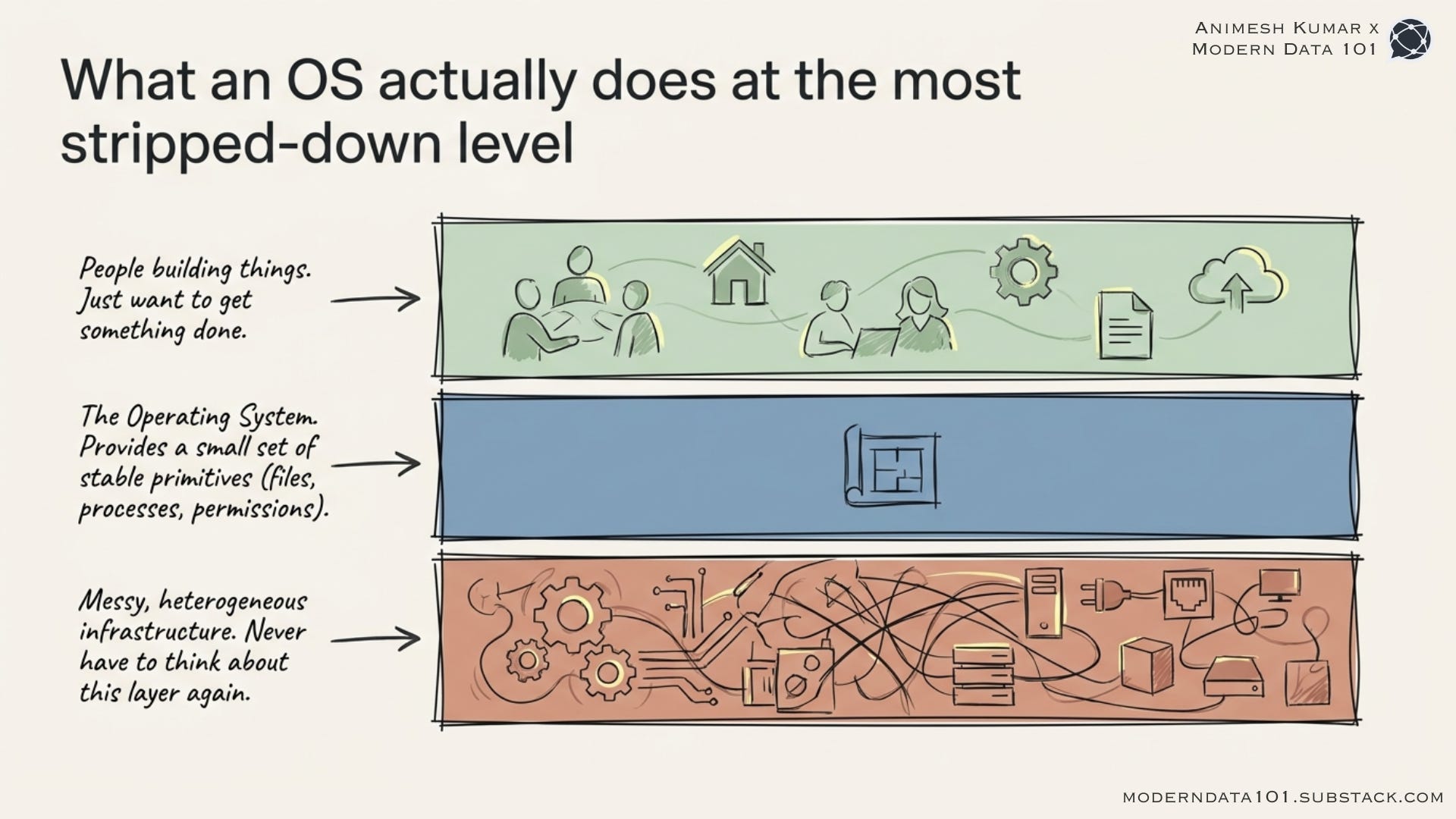
That asymmetry of one team maintaining the foundation, many teams building value on it is the entire point of an operating system. That asymmetry is exactly what was missing in data. And it’s exactly what’s missing in AI today.
Why Data Needed its Own OS
When we looked at the data stacks inside most companies a decade ago, here’s the pattern that stood out to us: a pile of independently operating tools.
A catalog here, a governance engine there, an observability layer bolted on somewhere else, all stitched together by hand, all needing their own care and feeding. It wasn’t a system. It was an assembly: a bunch of disparate capabilities thrown together in a mix, dressed up to look like a stack.
The consequence wasn’t subtle. Data engineers spent the overwhelming majority of their time connecting sources, fixing broken pipelines, chasing down why a table didn’t refresh.
Instead of producing anything that touched revenue. The skilled talent who should have been building things that brought more immediate value were sucked into infrastructure maintenance instead.
The instinctive fix everyone reached for was decentralisation: give each business domain its own data team, let marketing and sales and support each own their pipelines.
It sounds appealing in a slide deck but falls apart against three blunt resource constraints:
there are never enough skilled people to staff every domain,
never enough budget to rip out and rebuild every pipeline,
and never enough experts to train everyone through the transition.
Decentralisation without a shared foundation doesn’t scale, but multiplies the plumbing problem by the number of teams.
The actual fix was autonomy, and autonomy is very different from decentralisation.
Autonomy means a business analyst or a domain team can get what they need without needing their own infrastructure team, the same way the accountant doesn’t need to understand the laptop’s memory bus.
You get that by building one well-designed, declarative platform underneath everyone: a system with stable primitives that a small platform team operates centrally, while everyone else builds on top without ever touching the plumbing.
That’s what DataOS is: a system that treats the data product as the atomic, software-like unit of value.
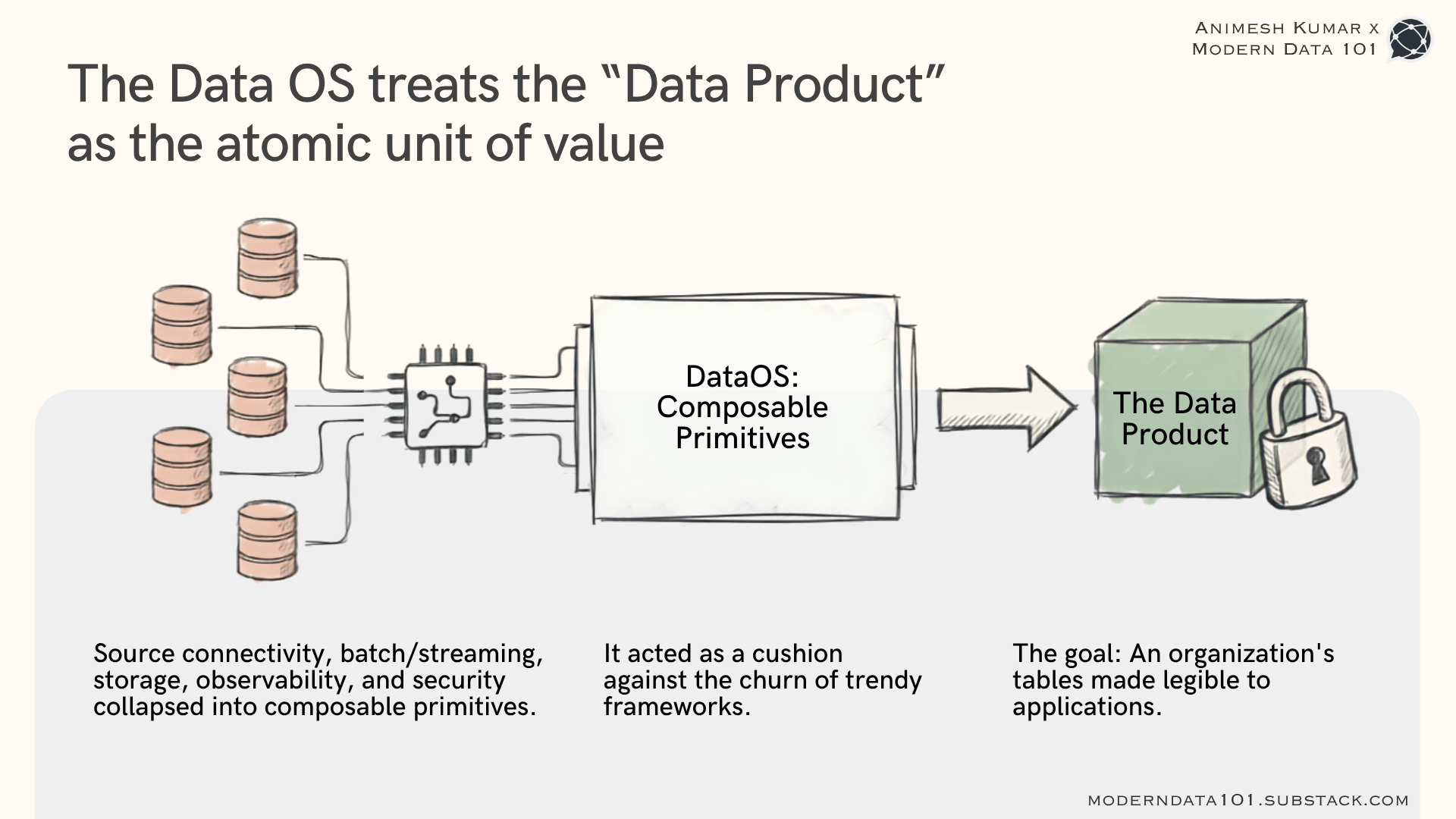
Learn more about what data leaders think about the atomic unit of value for data:

Source connectivity, batch and streaming movement, storage, observability, security, deployment- all collapsed into composable primitives instead of a pile of disconnected tools.
This architecture doesn’t chase whatever framework was fashionable one year (fabric this year, mesh the next, something else the year after) because the primitives were designed to be recomposed into whatever pattern the moment demanded. The OS was a cushion against the churn and never a bet on any one trend.

Now Ask the Same Question about AI
Here’s where it gets interesting, because the same diagnosis is playing out again, almost word for word, just one layer up the stack. In the data consumption space.
Y Combinator runs something called Requests for Startups: a periodic, public list of the problems its partners most want founders to go solve. It’s a genuinely useful signal, because it’s written by people sitting across the table from hundreds of companies a year, watching the same patterns repeat.
In their most recent batch, partner Diana Hu wrote an entry on the AI operating system for companies.
The best AI-native companies we're seeing have figured out something most haven't: they've made their entire company queryable. Every meeting recorded, every ticket tracked, every customer interaction captured, all legible to an intelligence layer that learns from it.
This turns a company from an open loop into a closed loop. In an open loop, you make a decision and maybe check the results weeks later. In a closed loop, the system monitors what's happening, compares it to what should be happening, and adjusts. I've seen teams that do this cut sprint time in half and ship twice as much.
The problem is building this today requires brutal integration work, stitching together Slack, Linear, GitHub, Notion, call recordings, and a dozen other tools with custom glue code.
And then comes the diagnosis, which is the part that should sound familiar: building that closed loop today requires brutal, bespoke integration work. Stitching together Slack, Linear, GitHub, Notion, call recordings, and a dozen other tools with custom glue code, by hand, per company. There’s a need for a platform that connects all of that context into one intelligence layer capable of reasoning across it.
Swap “Slack, Linear, GitHub, Notion” for “Snowflake, Kafka, S3, Postgres”, and you have the exact same sentence written on the data stack back in 2016.
Valuable signal scattered across disconnected systems, each requiring custom plumbing to reach, with no shared foundation underneath that makes the whole thing legible by default.
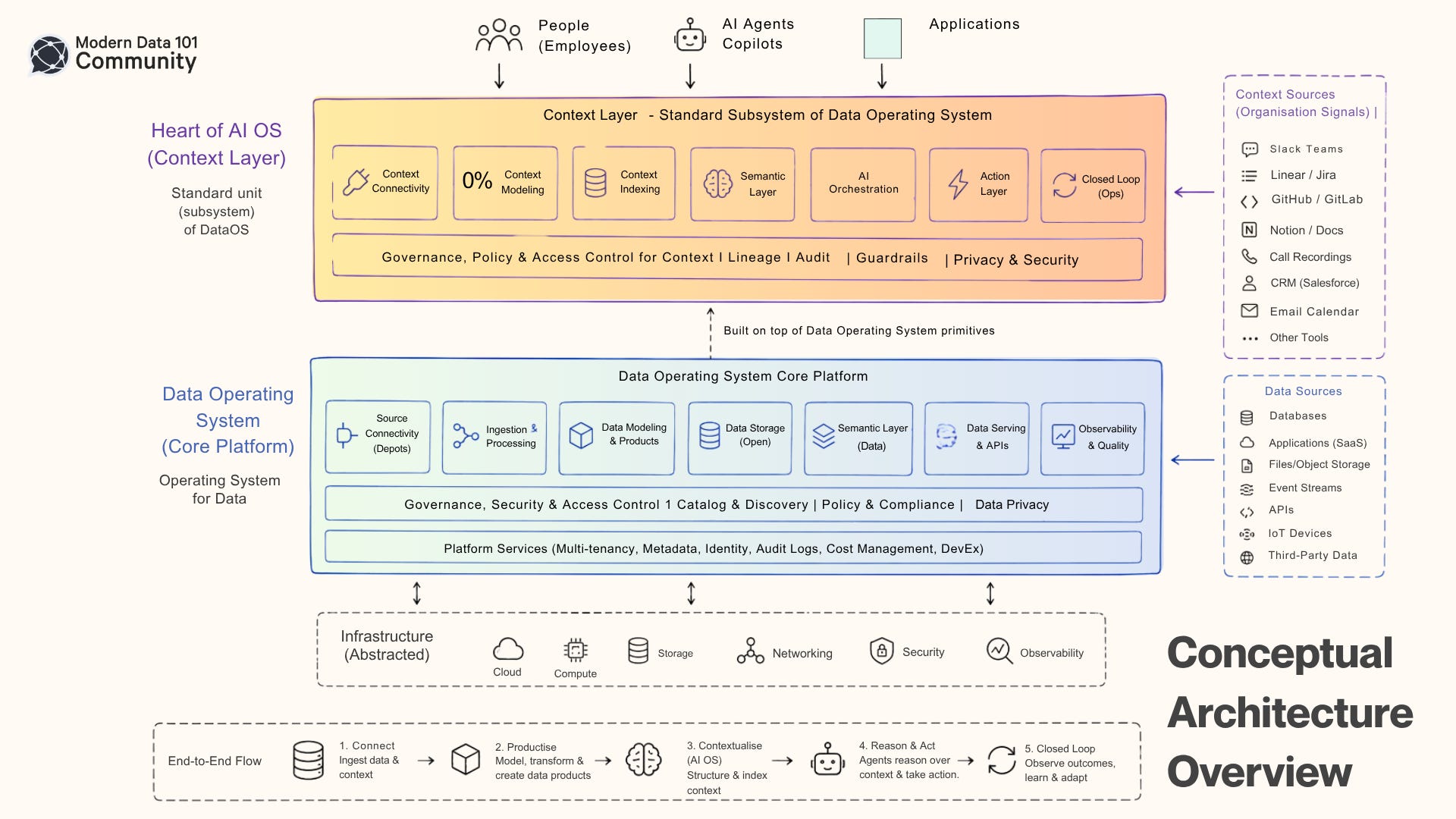
The AI Operating System is the Data Operating System’s Context Layer
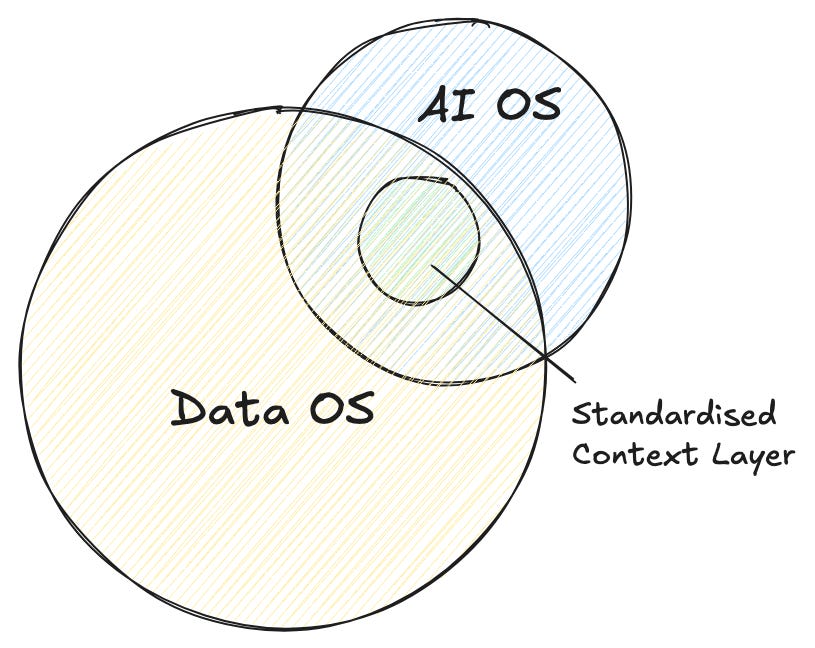
This is the part I want to be precise about, because it’s tempting to treat “AI OS” as a brand-new category that happened to appear because of LLMs. It’s the same architectural answer to the same underlying problem.
A data operating system’s job was to abstract the infrastructure of data so that a data product could be built, governed, and served without anyone touching the underlying plumbing.
An AI operating system’s job is to abstract the infrastructure of the organisation itself so that an AI agent can act on a company’s real operational state without someone hand-wiring it to twelve different tools.
Context has become a supremely important layer, given the new strain of machine data consumers. This evolution led us to build on top of our very own OS and standardise the context layer as a reusable unit instead of making it available only for custom use cases.
It was an easy transition given the underlying operating system was already in place and therefore, savvy with the organisation’s environment and the domains operating within it.
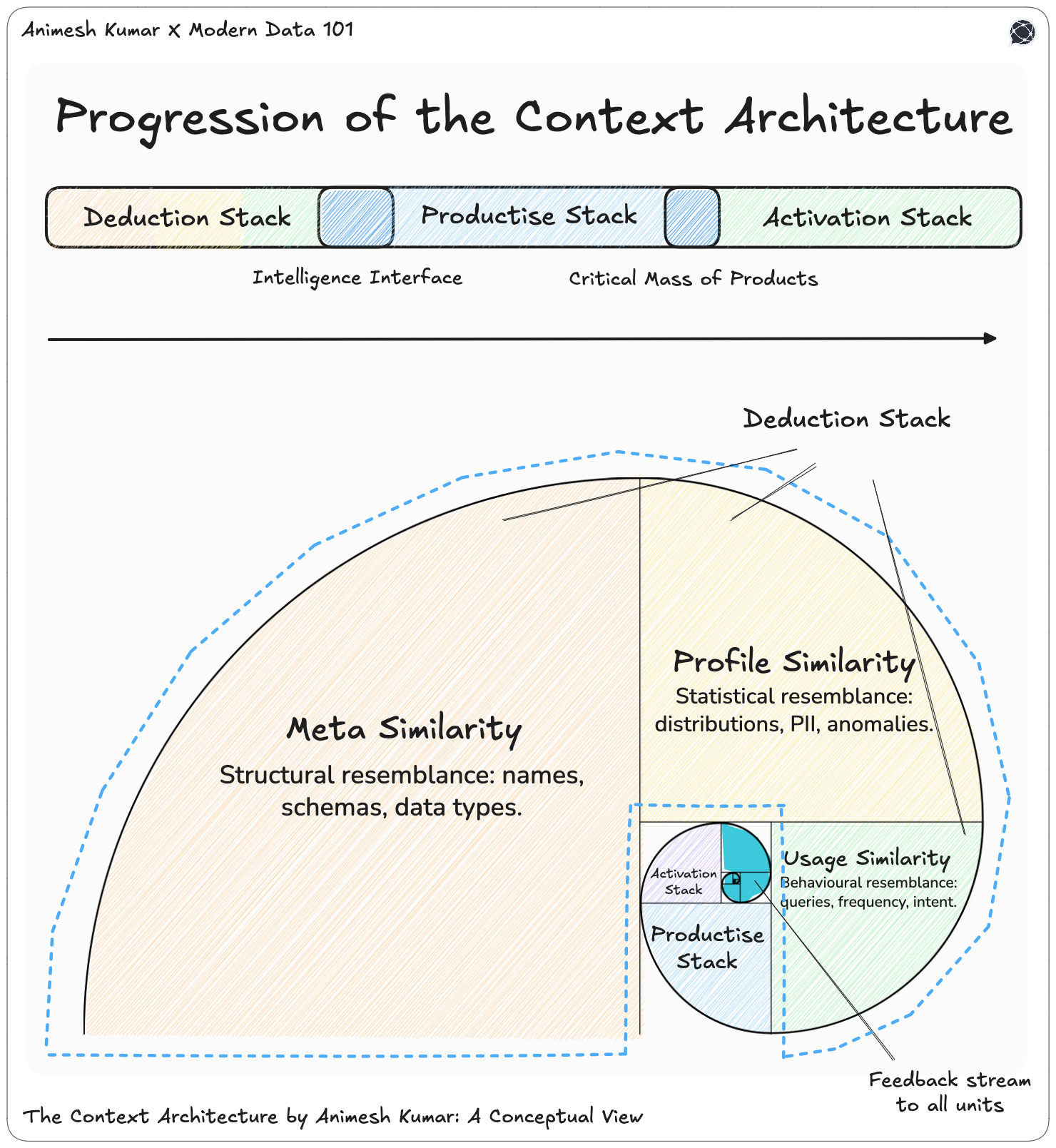
We have written at length on this aspect in the article on Rise of the Context Architecture

Walk through the parallel piece by piece:
Source connectivity becomes context connectivity.
DataOS uses depots (adapters) that could plug into any database, warehouse, or stream without the developer caring about the underlying protocol. An AI OS at the consumption level requires the same mechanism for Slack threads, ticket systems, call transcripts, codebases, and CRMs. More like context sources instead of data sources, but the abstraction problem is identical.
The data product becomes the company’s operating model.
In DataOS, the data product is the unit that fuses purpose and execution: a self-contained, governed, discoverable asset that captures why a piece of data exists and how to use it correctly.
The equivalent unit in an AI OS doesn’t change. The unit here is the data product as well (produced at scale in the productise stack), which has embedded context that plugs into the context layer in the activation stack.
Observability becomes the closed loop.
DataOS watches data products, and flags drift before it becomes an outage. While an AI OS watches the company itself, comparing what’s happening against what should be happening.
And that comparison is the closed loop Diana Hu is describing. It’s the same monitor-and-alert primitive from the data world, just pointed at the business instead of at a workflow. On this note, think about how the assets of the productise stack become the new primitives for AI OS.
Each unit of data product is directly tied to a business value and process. And AI OS would directly use these products as the primitives for observability and drift management at the business level.
Governance and access control become more important.
If an AI agent can act on a company’s dynamic operational state, the policy layer that is already part of a data operating system becomes even more essential. It decides dynamically who and what can see and touch which data.
It’s the filter standing between “agent that helps” and “agent that does something irreversible.” Anyone building an AI OS for their org needs to treat governance as the first primitive instead of an afterthought. Otherwise, it’s the exact mistake the data world spent a decade unlearning.
The platform team principle continues to hold.
Just like a small platform team runs dataOS so that hundreds of analysts and domain teams never have to think about infrastructure, an AI OS lets a company run on agentic automation without every department reinventing its own integration layer. The autonomy-over-decentralisation lesson transfers untouched.
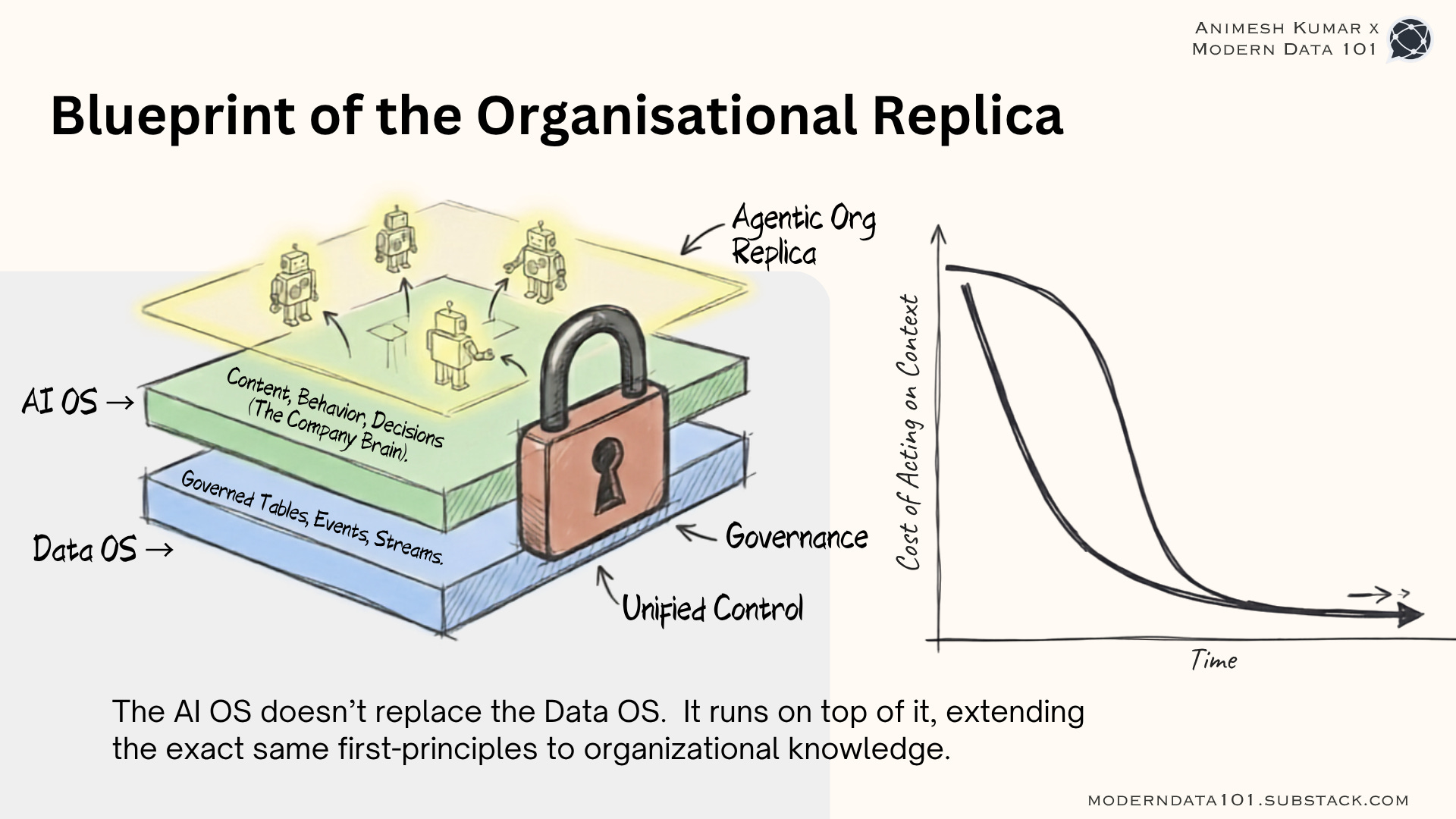
The Organisation as the New Data Source
A data operating system is built on the premise that an organisation’s data is too valuable and too fragmented to leave unmanaged. An AI operating system is built on the premise that an organisation’s behaviour (decisions, conversations, escalations, and judgment calls) is too valuable and too fragmented to leave unmanaged.
Clearly, the AI layer cannot manifest without first, or parallelly, building the data layer. An architecture of an AI OS runs on top of dataOS. And it extends the same idea to a new kind of asset.
DataOS already makes an organisation’s operating model legible to agents. The AI OS is another application built on top to drive and manage agents operating the organisation itself.

Once a company’s communications, tickets, code changes, and decisions are connected, structured, and governed, what you’re left with is something genuinely new: an AI system that doesn’t just answer questions about the company, but can act as a kind of operational replica of it.
A copy of how the organisation behaves when it’s working well, expressed as something an agent can execute against.
That’s the part that’s easy to undersell. A chatbot trained on your wiki can tell you what your refund policy says. A system built the way Diana Hu is describing and the way DataOS is built for data can tell an agent what your refund policy means as well as act at the edges of the organisation’s ecosystem: the operational systems.
Sachin Dharmapurikar, Head of Client Technology for DataOS, explains how the action layer takes effect and enables complete autonomy for governed intelligence.

That’s the difference between a tool the company uses and an operating system the company runs on.
Why AI OS now, and why does it rhyme 😁
The technology, approach, and philosophy have been true before the AI revolution. And even before DataOS, of course. The architectural argument for an OS-shaped abstraction layer has been true since the creation of the Operating System itself.
An AI OS, paired with agents capable of multi-step execution, is the next step in the evolution of the Operating System design pattern.
That’s also exactly why the governance lessons from the data world matter more. The data industry spent years learning, sometimes the hard way, that abstraction without access control just moves the blast radius around instead of shrinking it.
First data, now organisational knowledge and behaviour. All too important to leave scattered across a pile of disconnected tools, custom glue code, and tribal memory.
The fix isn’t to add another point solution. It is to build the operating system underneath: a small set of governed, composable primitives that a small team maintains so that everyone else, human or agent, can build on top of it without ever touching the plumbing.
We built that system for data because the data was sitting there, ungoverned and barely usable, while teams kept reinventing the same pipeline. The same opportunity exists today for the organisation as a whole, and we are already exploring these ideas, as you can already see.
Get that foundation right, and what you have is something close to an AI-native replica of how your company actually runs. One an agent can act on safely.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 💬

Connect with Animesh on LinkedIn 💬