
The Identity Crisis: Why Entity Resolution Is the Missing Foundation of Every Data Product Stack
The demo problem, the three-layer architecture for unified identity resolution, and human-in-the-loop reality

About Our Contributing Expert
Sonal Goyal | Data Leader & Founder

Sonal Goyal is a data infrastructure and AI systems leader focused on solving one of the most foundational problems in enterprise AI: identity resolution and master data management. With more than two decades of experience spanning big data, distributed systems, machine learning, and large-scale data engineering, she has built and advised platforms that process billions of records across healthcare, finance, retail, and cloud-native ecosystems.
Sonal founded Zingg.AI, where she leads the development of an open-source, warehouse-native MDM and entity resolution platform. Her work centres on helping enterprises unify fragmented customer and operational data to enable trustworthy analytics, AI agents, compliance, and personalised experiences at scale.
Before founding Zingg, Sonal spent over a decade building advanced big data and distributed computing systems through her consultancy and contributed extensively to the Hadoop and open-source ecosystem. She has served on the program committee for O’Reilly Media Strata Data & AI and is part of the NASSCOM Centre of Excellence task force shaping India’s data and AI ecosystem.
An alumna of the Indian Institute of Technology Delhi, Sonal also writes the Learning From Data newsletter, where she explores MDM, entity resolution, and the infrastructure challenges behind production-grade AI systems. We’re thrilled to feature her insights on Modern Data 101.
We actively collaborate with data experts to bring the best resources to a 20,000+ strong community of data leaders and practitioners. If you have something to share, reach out!
🫴🏻 Share your ideas and work: community@moderndata101.com
*Note: Opinions expressed in contributions are not our own and are only curated by us for broader access and discussion. All submissions are vetted for quality & relevance. We keep it information-first and do not support any promotions, paid or otherwise!
Let’s Dive In
I have been reading Animesh Kumar’s work on data product systems for a while, but his recent piece here on MD101, The Network is the Product: Data Network Flywheel, Compound Through Connection, stopped me in a way I didn’t expect. Specifically, this line:
Local quality checks protect the integrity of a single data product, but they do nothing to guarantee the integrity of the system it participates in.
I had to set the piece down for a moment. Because that sentence names, with unusual precision, the exact gap I watch teams fall into over and over when building data product stacks, and it points directly at a problem that almost nobody in the data community is talking about loudly enough.
We build beautifully. We instrument quality checks at every output port, add contracts, ship data products that pass every local test. And then we discover that our customer product and their transaction product disagree on who the same person is. That our AI agent is drawing conclusions about a customer who is, in the underlying data, three different people and one ghost.
The system falters not because the products were built badly, but because identity, the question of who or what this record actually refers to, was never resolved before the products were built on top of it. That is the identity crisis hiding inside most modern data stacks. And it is genuinely the hardest problem to solve.
The Stack Narrative Gap
For a long time, the data community has struggled with the demo problem.
Conference talks show stunning AI-ready architectures: data contracts between domains, semantic layers, self-serve platforms, and AI-ready pipelines. The narrative assumes that the data flowing through these elegant structures is already clean, already deduplicated, already referring unambiguously to the right entities.
But it never is.
Underneath every impressive composable architecture, most teams are quietly struggling with questions like:
Do we have one customer or three versions of the same customer?
Why does the marketing data product report 120,000 unique users when the CRM says 85,000?
Why does the AI recommendation engine keep making offers to people who already bought, or worse, to people who no longer exist?
The answer, almost always, traces back to unresolved identity.
The organisations that have moved on to real-time personalisation, AI-driven workflows, and cross-domain analytics solved identity first. They are just not talking about it loudly, because it feels like admitting that the foundation wasn’t glamorous.
It wasn’t. It was the hardest work they did.
MD101 has been covering this territory directly. The recent piece, AI-Native vs Rule-Based Entity Resolution: Which One is More Scalable? maps the landscape of approaches, and 5 Entity Resolution Myths That Are Destroying Your Data Strategy gets at exactly the underestimation problem described above.
I want to add the practitioner-level account of what it takes to build this well, and why it belongs at the foundation of every data product stack.
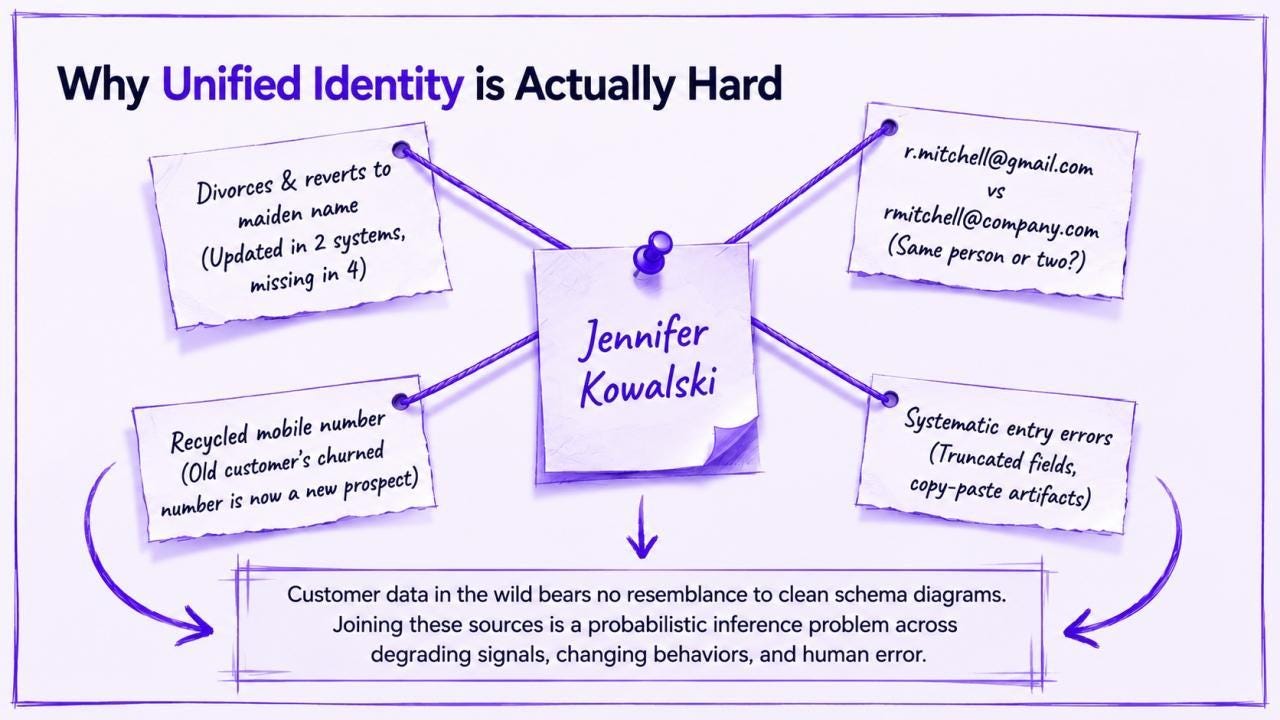
Why Unified Identity Is Actually Hard
Let me be precise about what “resolving entity identity across a data product stack” actually requires, because the underestimation of this problem is what drives most teams off course.
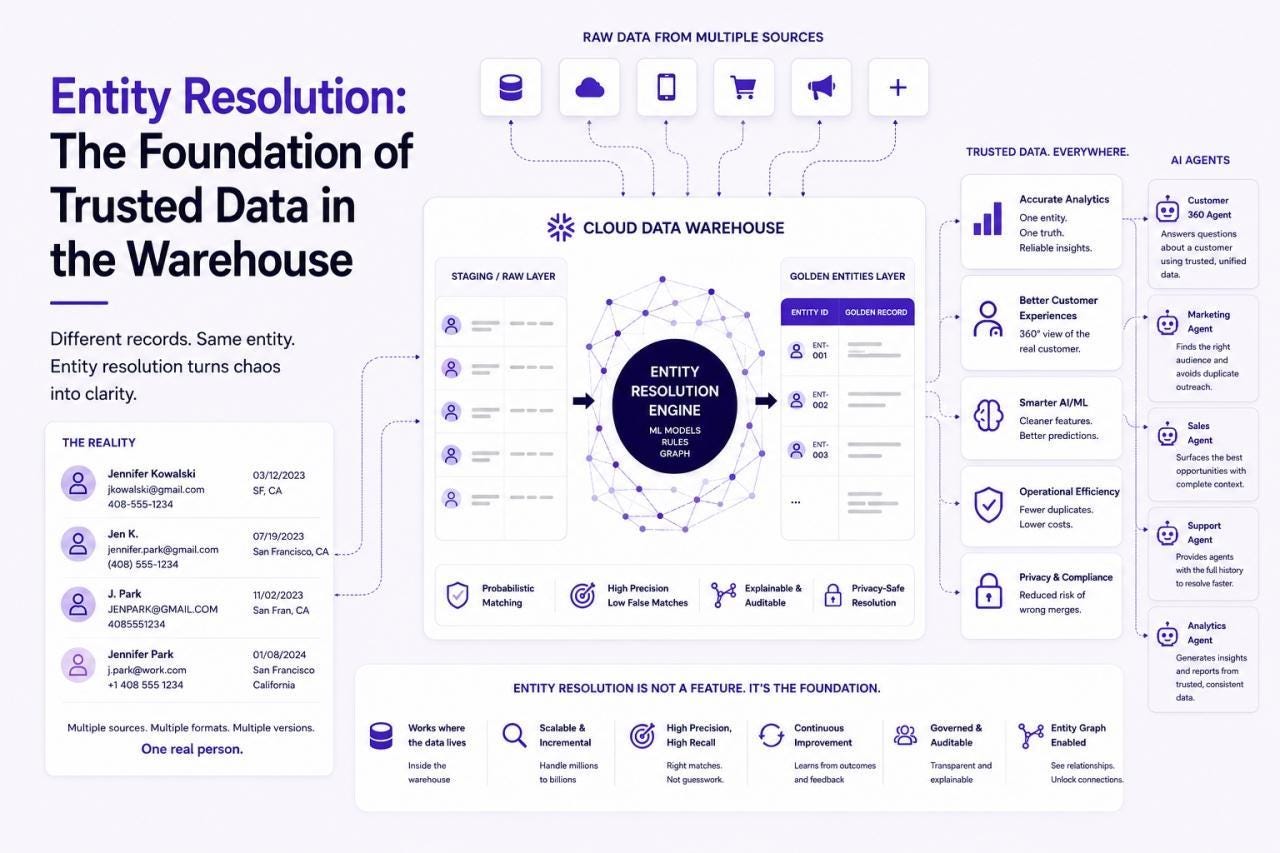
The Data Reality
Customer data in the wild bears little resemblance to the clean schemas in architecture diagrams:
Jennifer Kowalski gets divorced, reverts to her maiden name, Jennifer Park, and updates it in two systems, but not four others
r.mitchell@gmail.comandrmitchell@company.comcould be the same person across personal and work accounts — or two entirely different peopleMobile numbers change hands; the churned customer’s old number now belongs to a new prospect
A single address might appear in dozens of valid formats across source systems
Systematic entry errors like truncated fields, default values, and copy-paste artefacts masquerade as legitimate data
A resolution system has to work through all of this reliably, at scale, without trading accuracy for speed. Under-match, and your supposedly unified view is still fragmented across silos. You and Over-Match have collapsed distinct people into a single phantom record: a privacy violation, an analytics disaster, and a model-poisoning event rolled into one.
The Technical Challenge
The scope of the problem compounds when you consider what “across a data product stack” means. Identity resolution is not a database deduplication exercise. You are reconciling representations of the same person or entity that exist independently in:
Behavioural analytics platforms (cookie-based signals, device graphs, increasingly degraded by privacy changes)
Mobile applications (device-bound identifiers with no native cross-app linkage)
CRM and sales systems (contact records built from manual entry)
Commerce and transaction systems (loyalty identifiers, payment tokens)
Marketing and campaign tools (each maintaining its own contact universe)
Partner and third-party data feeds (with opaque lineage and variable quality)
Every one of these sources uses different identifiers, operates under different data quality norms, and refreshes on a different cadence. Joining them is not a schema problem. It is a probabilistic inference problem across systems.
The Scale Problem
Now put hundreds of millions of records into that picture. Brute-force comparison (every record against every other) is computationally out of the question at this scale; the search space grows as O(n²).
You need blocking strategies intelligent enough to shrink candidate pairs by orders of magnitude while still surfacing the true matches hiding in the noise. And this cannot be a periodic batch process. New records land continuously. People change. Your resolution layer has to stay current without re-processing the entire dataset from scratch each time.
The Governance Risk
Layer on consent management, privacy regulation, data retention, and the right-to-be-forgotten. Your identity system is not just a technical challenge, but a governance framework that has to operate across jurisdictions, respect preferences, and produce audit trails.
This is where Master Data Management practitioners have long argued that governance fails when it stays conceptual: entity resolution is where governance stops being a policy document and starts being architecture.
MD101’s own Top 10 Data Quality Dimensions and How Unified Data Platforms Enable Them walks through what “trustworthy data” actually requires structurally, and entity resolution is the layer that underpins most of those dimensions at the record level.
This is not “basic”, but some of the most sophisticated data engineering your organisation will ever do.
Why This Must Run in the Warehouse
There is a critical architectural decision embedded here that the community should be discussing more directly: entity resolution must run natively inside your data warehouse or lakehouse.
Animesh’s flywheel argument makes this intuition formal. The value of a data product system compounds through interaction, but only when the trust loop holds. As he writes in the same piece, quality must “inherit the topology of the data network.”
If you are resolving entity identity in an external system and syncing results back, you are creating exactly the kind of disconnected quality layer that breaks that trust loop.
You also create:
Data gravity problems: your data is already in Snowflake, Databricks, BigQuery, or Redshift. Moving billions of records out for resolution and back in defeats warehouse-native architecture. Resolving outside defeats a single source of truth in the warehouse.
Synchronisation lag: time between new records arriving and resolution completing, which means downstream products run on stale identity graphs
Governance duplication: your warehouse already has RBAC, audit logging, encryption, and masking. Replicating customer data to an external system means rebuilding all of that, or accepting a compliance gap
Run resolution where the data lives. It is the only way the quality layer can actually propagate across the network.
The Three-Layer Architecture That Works
For teams ready to tackle unified identity seriously, successful implementations share a common pattern.
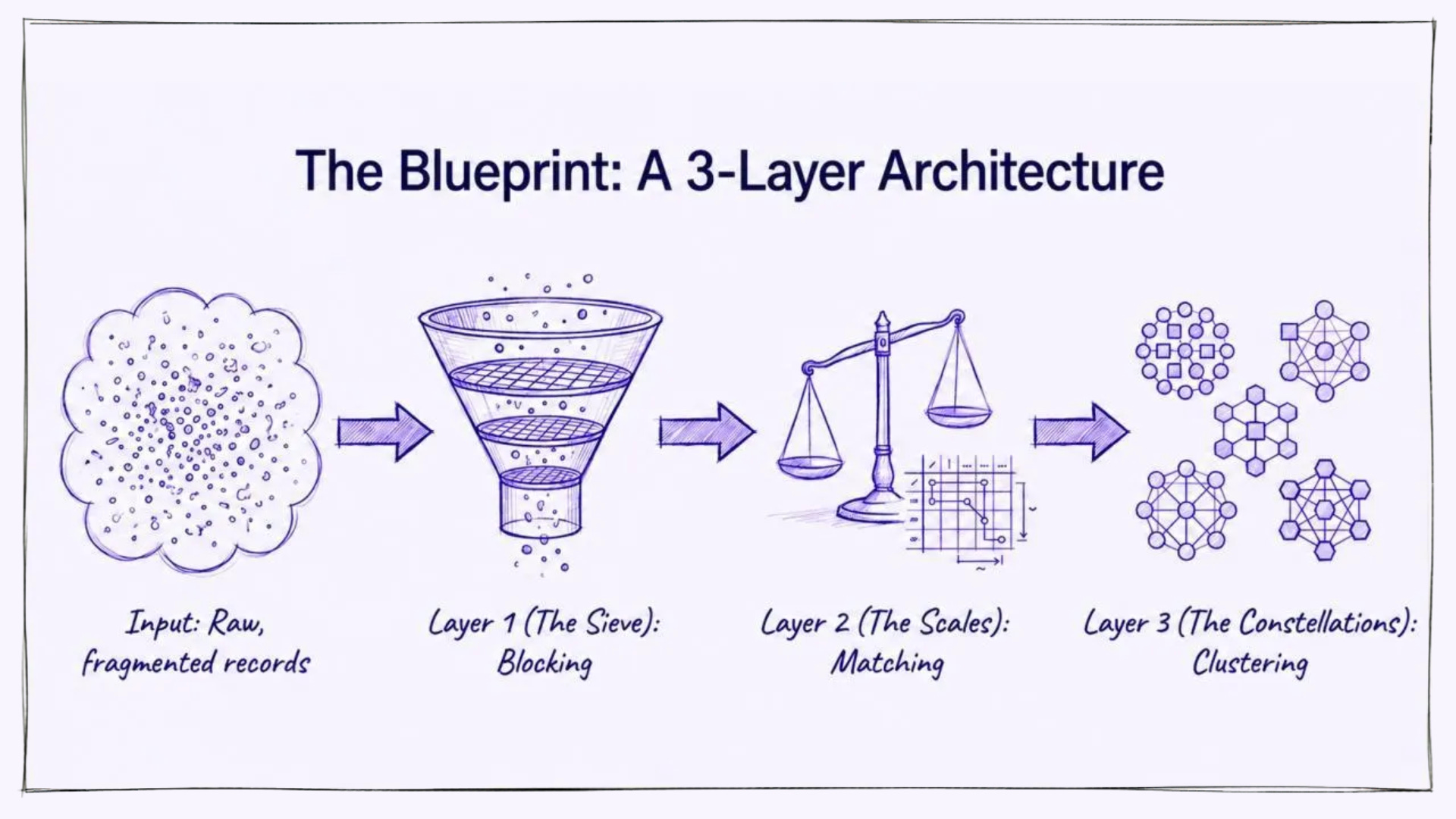
Layer 1: Blocking
Before any matching can happen, you need to dramatically narrow the comparison space. Blocking groups records into candidate sets using lightweight keys (phonetic encodings of names, partial postcode plus first name, email domain combined with approximate age, normalised address tokens) so that only plausible pairs ever get compared.
A single blocking pass is never enough; multiple passes with different keys ensure that records separated by a typo or a formatting difference still make it into the same candidate set. Done well, blocking eliminates the vast majority of impossible comparisons while preserving recall on the pairs that actually matter.
Layer 2: Matching
This is where ML earns its place. For each candidate pair that passed blocking, a model scores the probability they refer to the same entity, using string similarity, phonetic similarity, temporal proximity, geographic consistency, and behavioural patterns. The output is probabilistic, not binary, giving you control over precision-recall trade-offs by use case.
The debate MD101 recently surfaced (AI-Native vs Rule-Based Entity Resolution: Which One is More Scalable) is the right question, but the answer in practice is: neither alone is sufficient, and the choice shouldn’t be either/or.
Rule-based matching is fast and deterministic for high-confidence signals, exact email matches, government IDs, and account numbers. ML-based matching handles the ambiguous middle: names with typos, phone numbers that changed, and addresses with formatting variations.
The problem with picking only one is that you leave records unresolved. A pure rules system misses every fuzzy case. A pure ML system introduces unnecessary uncertainty in records you could have matched deterministically. The right architecture runs both in a single unified flow, rules handle what they can confidently resolve, and ML handles everything the rules cannot. No record is abandoned to the unresolved pile simply because one method hit its limits.
Layer 3: Clustering
Pairwise scores need to become coherent entity groups. If Record A and Record B score 0.92, and Record B and Record C score 0.88, the question of whether A, B, and C all belong together cannot be answered from the pair scores alone, it requires a clustering step that reasons over the full graph of relationships.
This layer also handles the harder lifecycle events: splitting a cluster when new evidence reveals two records were incorrectly merged, or absorbing newly arrived records into existing groups without destabilising what was already resolved.
Modern Data 101’s recent article on Entity Resolution at Scale: Deduplication Strategies for Knowledge Graph Construction addresses the knowledge graph dimension of exactly this challenge, the transitivity and consistency problems that arise in customer identity are the same ones you encounter when building entity graphs across domains.
The Human-in-the-Loop Reality
Full automation sounds appealing, but breaks in practice. Even well-calibrated models encounter cases where the right answer genuinely requires judgment: two people with the same name living at the same address, a family sharing an email account, a person who has legally changed their name, a data entry pattern so consistent it looks like a signal but is actually noise. No model trained on historical labels handles every new edge case correctly.
What separates implementations that hold up over time is not the absence of human review but the design of it:
Label curation: the quality of your training pairs determines everything about how the model generalises; getting these right is worth disproportionate attention
Threshold setting: probability scores need business-calibrated cut-offs, not arbitrary defaults; where you draw the auto-match and auto-reject lines should reflect the actual cost of errors in your context
Steward workflows: low-confidence pairs should surface to reviewers efficiently, with decisions fed back as new training signals rather than discarded
Audit and override capability: downstream teams will challenge merge decisions; you need the lineage to explain them and the tooling to correct them when the model was wrong
The measure of a good implementation is not how little human involvement remains. It is whether the human involvement that does remain is concentrated where it actually changes outcomes.
What This Enables
Let me share what this foundation looks like when it is built correctly.
Fortnum & Mason, the 300-year-old luxury retailer, had customer data fragmented across restaurant bookings, email signups, online transactions, and in-store purchases. An initial attempt at third-party resolution created non-persistent identifiers with limited process visibility and raised privacy concerns about sharing data externally.
By implementing ML-based entity resolution running natively in their data warehouse, their Customer Engagement Director, Jon Moss, describes the result:
“For the first time, we’re able to understand how customers are shopping with us: online, in-store, over the phone, or in restaurants.”
Orthodox Union, operating over 40 websites, 5 mobile applications, and multiple custom CRMs, needed a resolution that understood not just individual identities but household relationships. Their Director of Product Development, Shelomo Dobkin, describes it:
“I was very surprised about how well we matched and how good the results are. It’s just unbelievable. It far exceeded our expectations.”
What makes these cases worth examining is not the technology. It is what the technology enables downstream: audiences that marketing can trust, customer journeys that analytics can build on, model training data that is not corrupted by identity fragmentation, and AI agents that operate on coherent context rather than amplified noise.
Animesh’s framing is exactly right: trust multiplies usage, and usage multiplies value. But trust has to start somewhere. It starts here.
The Proactive Path
Every team building on a composable data product stack will arrive at this problem eventually. The variable is not whether identity resolution becomes necessary; it is whether you build it into the foundation or scramble to retrofit it after something breaks in production.
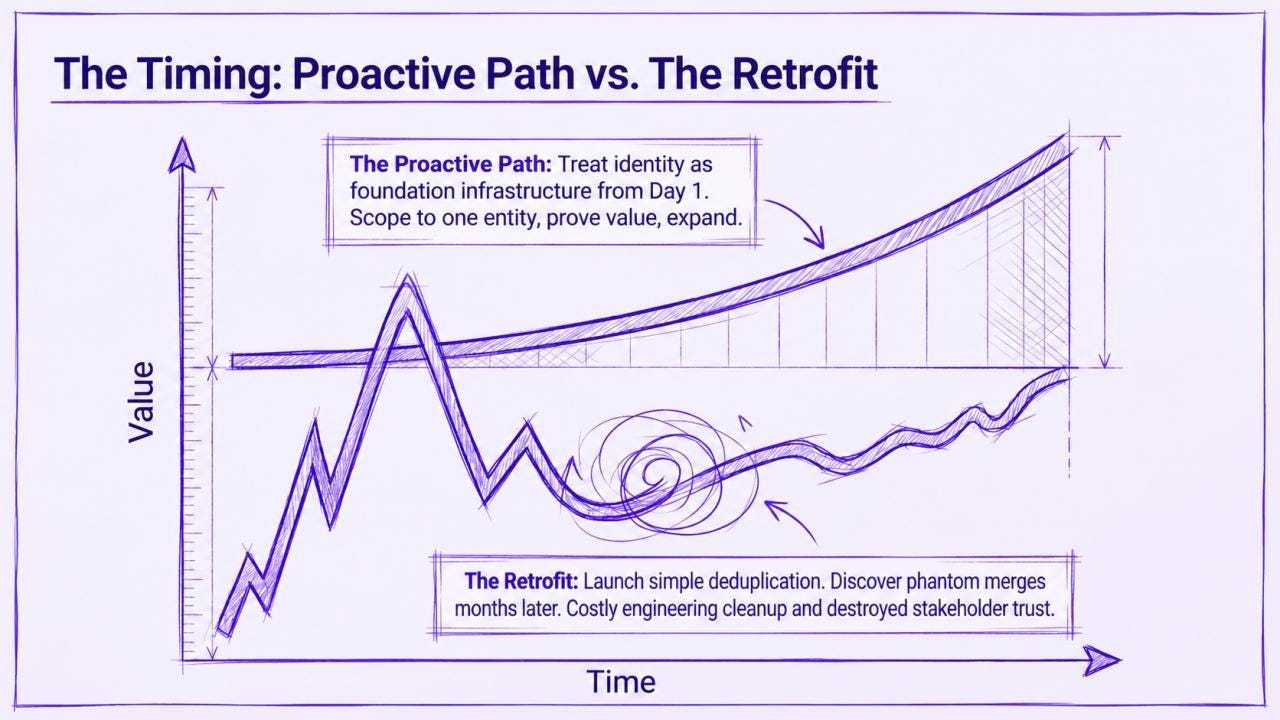
The retrofit story tends to go the same way: launch on simple deduplication logic, build audiences and downstream products on top, then discover months later that a meaningful share of your “unified” entities are duplicates, or worse, that distinct people were incorrectly merged and decisions were made on that basis. Unpicking it is expensive in engineering time, costly in stakeholder trust, and sometimes irreversible in its downstream effects.
The alternative is treating identity resolution as infrastructure from the start, scoping to one entity type, proving value, and expanding, rather than as a cleanup task that never quite makes the sprint. The stacks that compound in value are the ones where the foundation was built to carry the weight. This is unglamorous, invisible work. It is also the work that makes everything built on top of it possible.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 💬

Got questions? Find Sonal on LinkedIn or drop a comment below. 💬
 | A guest post by
|
Thank you. Identity resolution and consolidation is super important and not talked about enough considering its wide surface area for potentially occurring in any organization's records.
Take your point about business-calibrated cutoffs one step further. Identity doesn't have one resolved state. Two records that are the same person for a marketing audience can be different people for a compliance audit. The three layers resolve that mechanically. Where to draw the line, they can't. The cost of a false merge versus a false split is a business call that shifts by decision. In most orgs no one owns that call. That's why identity stays unresolved, long before the ML gets hard.