
Building your Sausage Machine for Data Products 🌭: Less Tech, More Strategy | Issue #37
Product Mindset, Bizarre Analogies, and Your Compact Canvas

There's an idiom: “Like watching sausage getting made.” The idea being that you may like how sausage tastes, but that if you saw how sausage was made, you would find it a lot less appealing. The idiom applies not just to sausages but to the unsavory activities that are the backdrop for what we enjoy or admire, from law to medicine to politics to whatever.
~ The New Yorker
This holds true even in the realm of data, and “whatever” includes your very own data stack. We love the benefits Data Products earn for us but are averse to bringing product thinking into practice - not by choice but by years of habit imposed by traditional cycles.
But building a sausage machine is necessary to quickly produce sausages at scale and with a standard shape and consistency. These sausages are then delivered to masses in various formats, aka output ports, be it as hot dogs, pizza toppings, or sandwich filling - take your pick

Before jumping in, follow MD101 on our new socials! For weekly updates on the data industry, trends, jobs, innovations, and more, feel free to drop by on our LinkedIn and Twitter and be part of the conversation!
How brutal is the machine? Or, how brutally is it perceived?
The first thought that often strikes us is how vicious a munging and crunching machine could be. But in reality, when it comes to data, what mostly scares us is the black box effect. And anticipation that the data might cause digestive problems in downstream applications.
What is happening to my data?
Is the outcome going to be as reliable as my output?
How can I actively add ingredients for healthy crunching?
How can I have complete visibility into the process?
And on and on…
Building Less Scary Products Starts with a Practical Product Mindset
Be it sausage machinery or data products, it comes down to some fundamental product properties - ones we have unanimously agreed to be blind to for a very very long time in the data industry.
Such properties enable more transparency, confidence, and value from the processes and outcomes of the product.
The Differentiating Factor: Telling Products from Projects
The key difference between data products and data projects is how data interfaces with business metrics. As Don McGreal and Ralph Jockham point out in their extremely insightful book The Professional Product Owner:
In a project mindset, Success is defined upfront (inside out). And is largely guided by scope, time, and budget.
In a product mindset, Success is continuously driven by business metrics (outside in). The process is largely guided by user adoption/retention, revenue, cost savings per feature, and other such consumer-facing metrics. Factors such as scope, time, and budget get guided in turn by the above parameters.
How does it help the sausages? Intercepted with insights from McGreal & Jockham
The above parameters push for more frequent releases that bring in ‘feedback’ as a raw material for all consequent product versions. The product is now more ‘delightful’ to consumers, you are more likeable, and the sausage CEO is probably swimming in a bed of cash.
With right-to-left data management, suddenly the process loses significance and the metrics or objectives gain higher priority, enabling data teams to pivot and move creatively with more ownership over their plans and pitch.
Less waste, more to eat!

Contrastingly, prevalent processes (aka “projects”) mean:
Less to no visibility around business metrics or how they are associated with your “slice of the pie” in the project
Less motivation to show ownership or proactiveness with process-oriented tasks that suppress creativity
Consequently, more handoffs
Managing people and tasks instead of goals!
What to consider to build a product instead of a project: Your Go-To Canvas
If there could be just one word to describe the nature of “projects”, it would be “fixed”. Projects are inanimate, defined and executed within the “scope” of a pre-defined success criteria. On the other hand, “products” are more “evolving”- living and breathing for the convenience of consumers. They are reactive by nature to the consumer’s changing needs. The criteria for “success” becomes a moving metric.
For simplicity’s sake, let’s see what we’d need to create these machines first, along with some examples of each instance.
Collaborators: Meat supplier, distributors, machine operators, …
Value Proposition/Purpose: Consistency, high production, feedback-driven production, strong and long-term customer relations, …
Design Plan: Machinery experts/consultants, operator’s requirements, consumer’s requirements, resources available, …
Build Plan: Key resources, technique, workshop
Launch plan: Quality assurance, concrete delivery routes, automation, …
Improvisation/Evolution: Feedback assessment, advanced goals, …
Consumption Channels / Distribution Plan: B2B outlets, B2C endpoints, …
Target Metrics: #Orders per day, #Complaints per day, …
Alignment with Revenue Generating Streams: Segment-driven sales, Cross-selling new product variants, awareness campaigns, …
From a product point of view, the above factors are not so different whenever ideating and executing development of most types of product which relatively delegate, dissipate, or redirect good amount of effort. For example, how a pen eliminates the need to dip into ink constantly, or how the chopping machine eliminates heavy labor through simple levers, and how bottles reduce roundtrips to water filters, and so on…
The production processes are ideally repeatable, governed, quality-assured, and resource-optimised. These are the fundamentals. No one would argue with these parameters laid out by a factory or workshop.
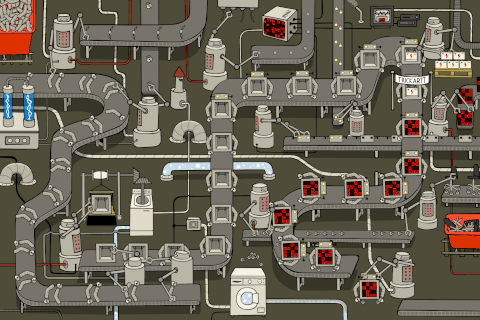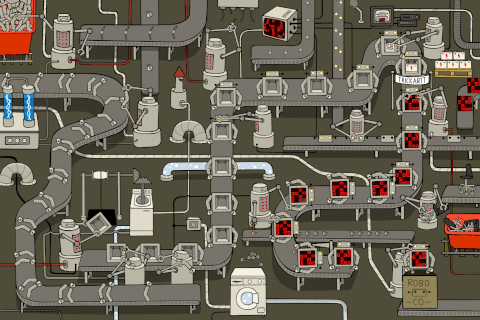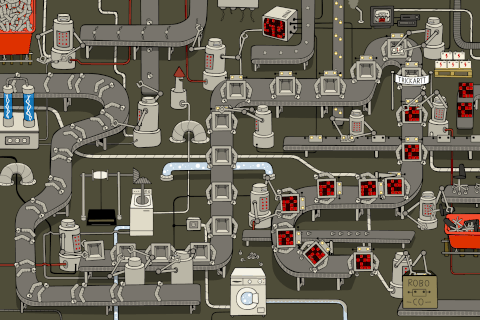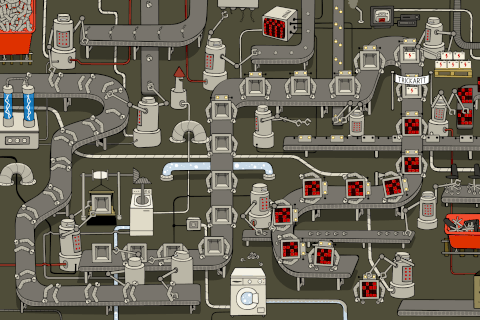
This shows us how the biggest barrier to data-as-a-product is, in fact, a mindset shift. We are so used to considering such parameters for regular products that, say, not aligning with business-driving metrics such as revenue or not regulating production end-to-end would just seem bizarre. But it doesn't seem bizarre for data, and ironically, the above fundamentals have often been perceived as bizarre when data products and data-as-a-product concepts started doing the rounds.
It holds true for the realm of data as well. And in this case, Data Products delegate, dissipate, or redirect good amount of cognitive effort. The production process is also repeatable, governed, quality-assured, and resource-optimised. And to create a Data Product, you need to focus on very similar instances behind product development.
Let’s visualise the same on a canvas, this time for data instead of 🍗

Too much work? Perhaps initially. And it’s always better than less returns on the dollars. Imagine if pen factories weren’t bothered about repeatability, quality, or speed/resource optimisation. Employees would be running around making one pen at a time for XYZ specifications from a random customer in one of the distribution shops. Isn’t it the same as spawning a whole new data pipeline to answer one specific business question or creating 1000K data warehouse tables being from 6K source tables?
Once the foundation, aka your Data Product Factory is ready, you could easily see the difference in speed, savings, reusability, and value for customers. That’s what would naturally happen with a product approach.
Want to deep-dive into repeatable production? Refer to Ch2 to Ch 5 in the End-to-End Data Product Guide.

Or, here’s a brief overview of the same: Data Product Lifecycle at a Glance

 | A guest post by
|