
Role of Contracts in a Unified Data Infrastructure | Issue #11

Disclaimer: This one’s a long-winded narrative because to build a case for contracts in the unified system, we need to break down the ideas of unified architecture and data products first. For those who are already privy to the concepts, feel free to skip to the section on Contracts.
TOC
Emergence of the Unified Infrastructure
How a Unified Infra is Incomplete without Data Contracts
It often comes as a surprise to me how a major fragment of the data community is unaware of the unified data architecture or the benefits it brings to the table.
Possibly this can be attributed to the major hangover of the maintenance-first Modern Data Stack, which was not just alluring at first glance, but also demanded a pretty hefty price with the requirement of not just cloud but a plethora of tools to operationalise the cloud.
With continued doses of point solutions, the org’s data initiatives grew heavy and the pipelines got more complex with every new feature, point tool, or bug, making it a mammoth task for data teams to even think about cleaning the mess or transitioning into a more seamless design.
After all, it’s not just substances but also ideas that can hook onto the host.
⬆️ A bit far-fetched yet IMO amusing analogy for the above | Courtesy of Nuggets
This is a big reason that while revolutionary design patterns such as the mesh are being strategised and evangelised, they are still not able to gain practical ground and stay as theoretical ideal states for most of the data-focused organisations to this day.
The Emergence of the Unified Architecture
The Unified Data Architecture was predicted and recommended way back in 2020, which is over three years ago from today. However, it largely did not get any immediate action or saw many aligned initiatives to bring the idea to fruition at scale.

But what is a unified infrastructure?
A Unified Architecture, as one might assume at first glance, is not an exercise of tying together multiple tools with disparate capabilities together. This goes against the primary principle of having a unified foundation.
Instead, a unified infra is built upon a common set of first-order solutions, or building blocks, that are composed together to build higher-order complex solutions.
Examples of first-order solutions: Storage, Compute, Workflow, Policy, Volume, Cluster, etc.
Examples of higher-order solutions: Security, Quality, Ingestion, Transformation, Streaming, etc.

To summarise, a unified architecture
Abstracts complex and distributed subsystems,
Omits excessive integration and maintenance overload,
Encapsulates building blocks of a data product
While maintaining customisation flexibility
To offer a consistent outcome-first experience
For both expert and non-expert end users.
There are a plethora of reasons other than the inherent ones in the above definition on why the above is a more seamless design. The most practical one is perhaps the fact that the unified infrastructure is future-proof in the sense that it is able to implement a wide range of design patterns, including the latest mesh, due to the availability of low-level building blocks.
The fundamentals don’t change nearly as fast as the latest tech de jour. Focus on what doesn’t change and build from there. ~ Joe Reis, Author of Fundamentals of Data Engineering
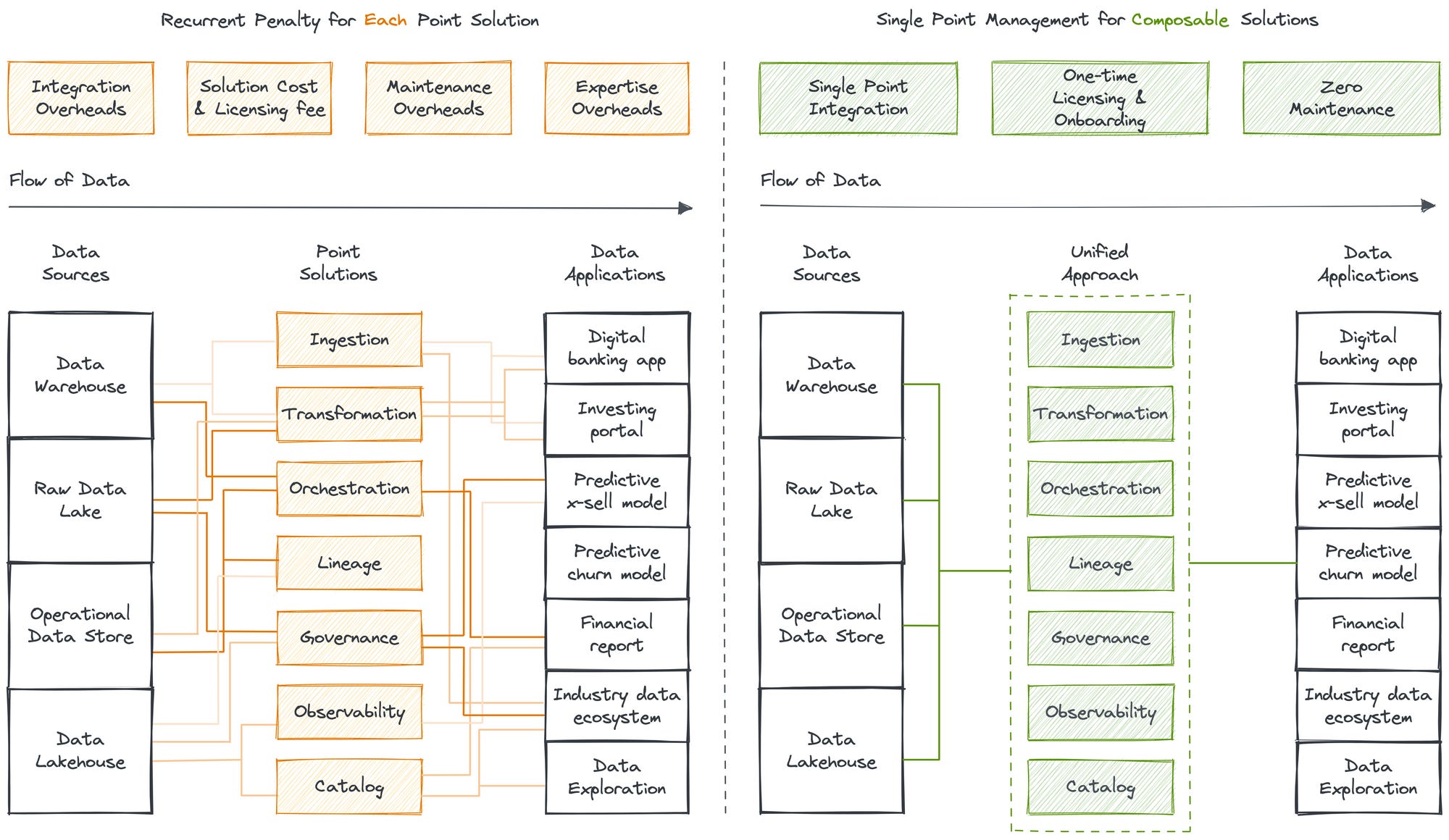
However, after three long years of the predicted or recommended infrastructure, transitions to a unified data architecture are finally apparent, even if not largely visible, in the data space. Several consumers, as well as producers of data tools and services, even though not completely, are gradually aligning to a more unified pattern, allowing multiple capabilities on top of a common base.
However, it is critical to understand that a product catalogue with multiple capabilities can be a boon as well as a curse. The key is to understand how the product is able to furnish the capabilities. If it is through a network of multiple integrations of disparate tools, it is essentially a landmine for the future. The system and pipelines will get heavier over time and choke even the thought of change. On the other hand, if the foundation is enabled through a unified architecture, the pipelines will only get stronger over time and reinforce every capability with additional data and metadata.
While not every data enablement product or org is able to implement the above due to rigid foundations built on archaic architecture paradigms, the orgs that are able to develop a unified base have an inherent lead in data management and operationalization.
The heart of the Data Product - The Unified Infra
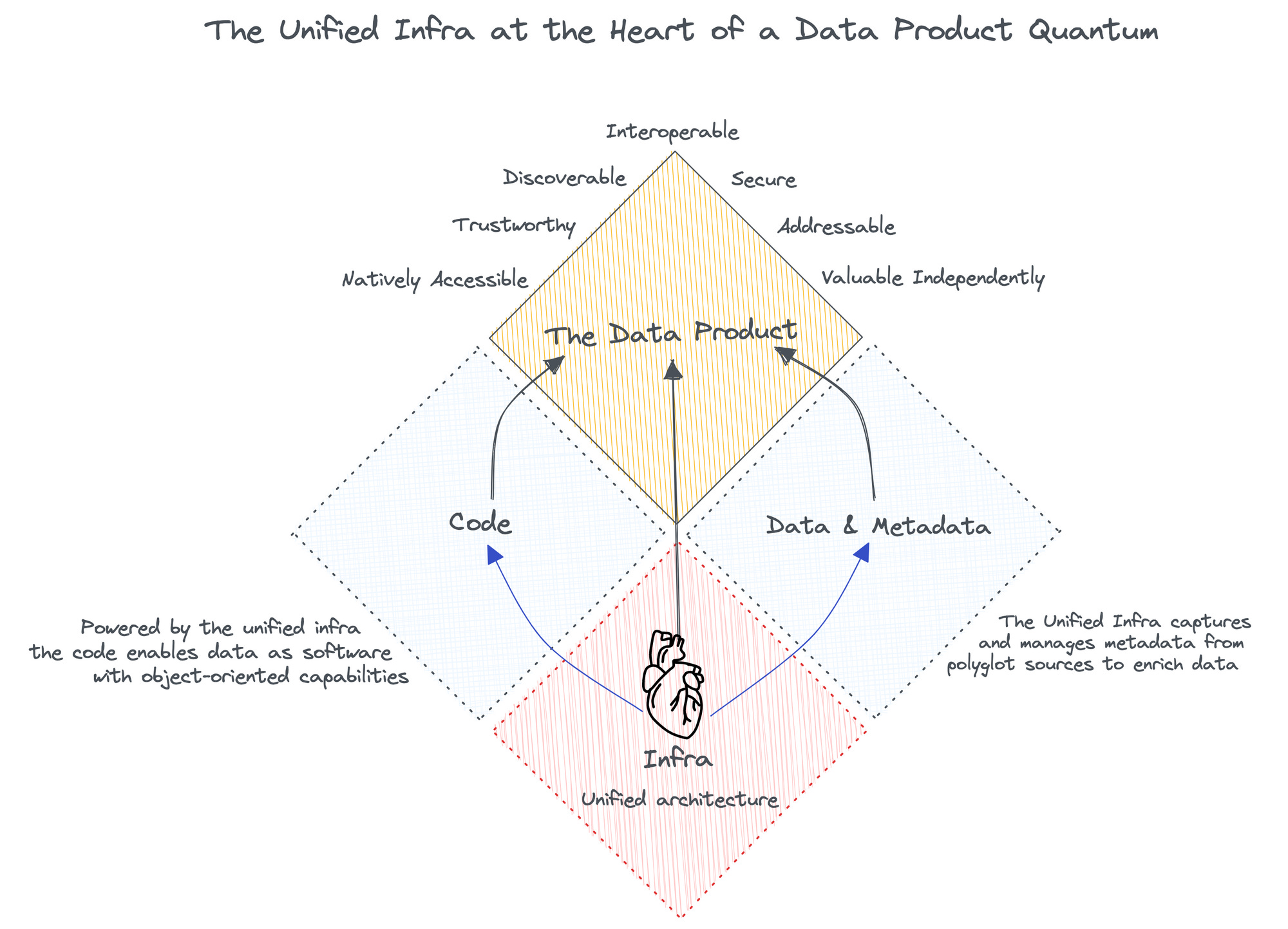
Talking about data products is essential in the narrative of unified infrastructure since the emergence of the data product concept reinforced the need for a unified architecture. The Data Product attributes, such as reliability, trustworthiness, addressability, discoverability, security, etc., are possible only through a common base where the first level is able to talk to the different building blocks within it that bifurcate into complex higher-order solutions.
Let’s reiterate what a data product is.
Data Product = Infrastructure + Code + Data & Metadata
Data Product ≠ Just Data
Inherently, it is the infrastructure, specifically one with a unified architecture, which is capable of powering both code and data & metadata counterparts more holistically. The illustration below should cleanly summarise the concept.
How a unified infrastructure is incomplete without contracts
If you're developing data products or unified data systems, data contracts effortlessly come into the picture. They might not steal the show, but they're one of the essential directors.
How? Let's draw a parallel to the software world.
Understanding Dynamic Configuration Management
To clearly understand the impact of Contracts’ single-point change management, we need to refurbish the idea of dynamic configuration management or DCM - a process often used in software development.
In software, developers working with robust systems are used to the concept of a common specification file for dynamic configuration management. In other words, a consistent standard file that reflects change across dependencies and multiple layers of infra or environments. This saves time, effort, and reduces bugs exponentially compared to when developers have to visit and revisit every site, initiate change, and tie changes back to the endpoints of that site.
Let’s all agree change is the only constant, especially so in the data space. Declarative, single-point change management, therefore, becomes paramount to developer experience and pace of development and deployment. This goes by the name of dynamic configuration management and is established through workload-centric development.
Let’s look at the flow of DDP to applications at a very high level:
A business use case pops up → The domain user furnishes the data model for the use case or updates an existing one → The data engineer writes code to enable the data model → The data engineer writes configurations for every resource and environment to provision infrastructure components such as storage and compute for the code.
In prevalent scenarios, swamps of configs are written, resulting in heavy configuration drifts and corrupted change management since the developer has to work across multiple touchpoints. This leads to more time spent on plumbing instead of simply opening the tap or enabling the data.
Dynamic configuration management solves this by distilling all points of change into one point. How is this possible? Through a low-lying infrastructure platform that composes all moving parts through a unified architecture. Such an architecture identifies fundamental atomic building blocks that are non-negotiables in a data stack. Let’s call them primitives.
Storage, compute, cluster, policy, service, and workflow are all examples of primitives. With these components packaged through infrastructure as code, developers can easily implement workload-centric development where they declaratively specify config requirements and the infrastructure is provisioned and deployed with respective resources at respective environments. Whenever a point of change arises, the developer makes the required change in the declarative specification to mirror the change across all dependent environments.
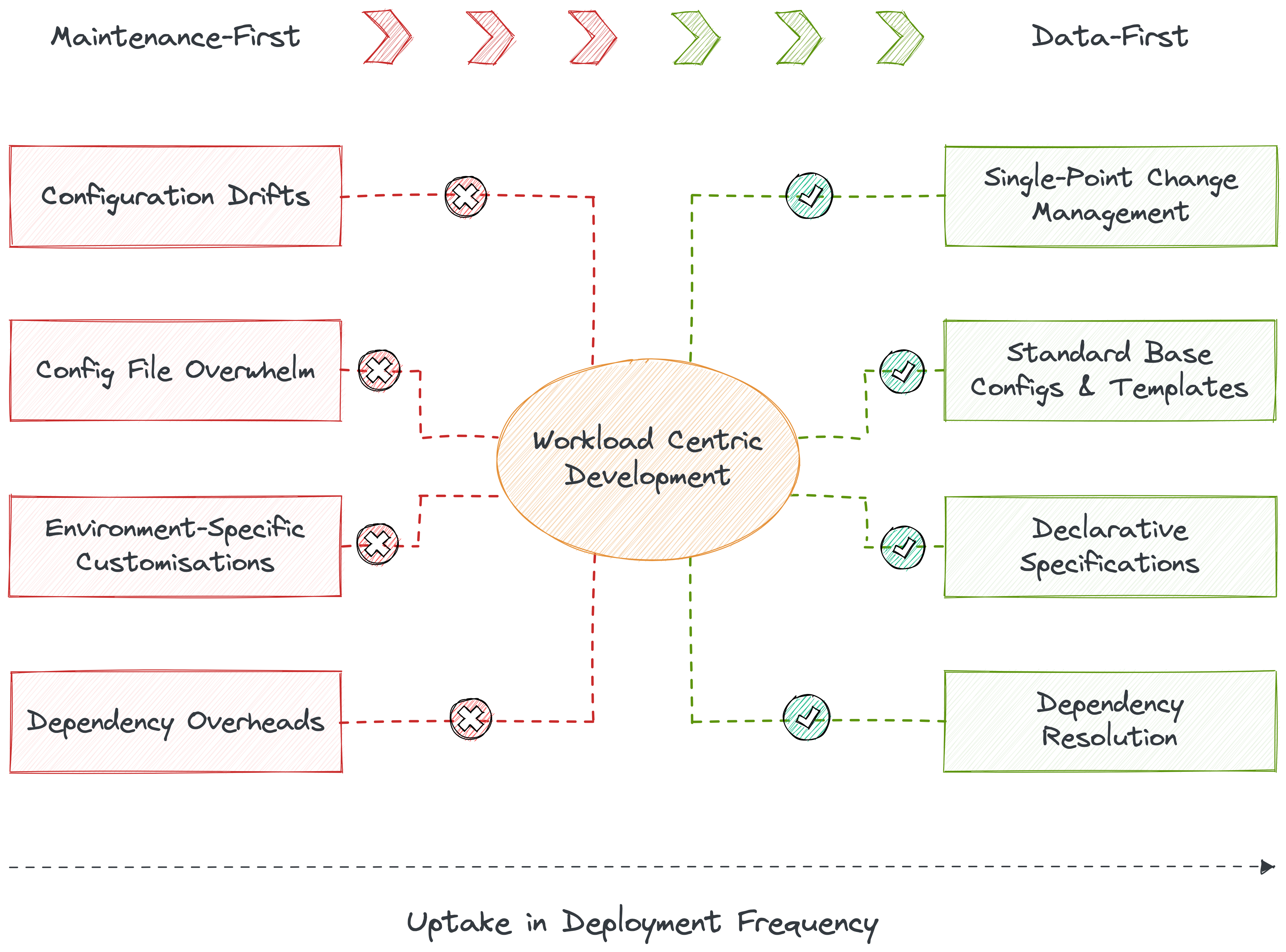
Workload-centric development enables data developers to quickly deploy workloads by eliminating configuration drifts and vast number of config files through standard base configurations that do not require environment-specific variables. The system auto-generates manifest files for apps, enabling CRUD ops, execution, and meta storage on top. Data developers can quickly spawn new applications and rapidly deploy them to multiple target environments or namespaces with configuration templates, abstracted credential management, and declarative and single workload specification.
The impact is instantly realised with a visible increase in deployment frequency.
Contracts as a single-point change manager
Contracts do the same for data products that a common specification file does for robust software products.
While a unified architecture already implements workload-centric development through common spec files for infrastructure provisioning, contracts do so on a more logical level and take care of the business stakeholders by enabling the principles of DCM for the more abstract business use cases.
For example, contracts specific for semantics, security, quality, and shape and any CRUD operation around these are deftly taken care of by the single source of logical change management. They also prevent mass failure of pipelines by handling the change at the inception nearer to the data producer.

The philosophy and purpose of well-acclaimed workload-centric development is to improve developer productivity and experience. Data contracts do the same on the logical front for the business. It improves productivity and experience for both data producers and consumers through a unified interface for specifications on data.
A product can be an excellent creation, but it's pointless and probably wasted effort if there's no adoption. Especially a high percentage of adoption if you want to create pivoting tech. And the top priority to solve for adoption is always the product experience.
While a unified data architecture solves problems around semantics, governance, and quality singlehandedly, it does so across distributed interfaces. When a contract becomes part of the unified architecture, it facilitates a more ideal state of single-point change management for logical specs across these interfaces.
The ideal need is always a single simple declarative interface, which, in the data ecosystem, is none other than the data contract.
In a unified infrastructure, a Data Contract:
Facilitates single-point change management across distributed interfaces of any unified architecture.
Takes care of the following specifications:
Shape: Schema of the data the contract governs
Security: Global and Local Policy specs for the data
Semantics: Logical and Business meaning of the data, such as column name & descriptions
Quality: Logical & Business conditions/rules that the data must adhere to
Acts as an API and a specification file to decouple multiple touchpoints from the overwhelmed user whenever a new change pops up.
Is the single source of truth for the
data producer to write specs for data,
data engineer to read & implement/map across various levels of infra
data consumer to discover, consume, and recommend changes.
Where do Contracts sit in the picture?
Another attribute of a data product is the ability to support multiple output ports, each designed and sustained to serve specific formats or requirements. Therefore, the logical conclusion is that a contract sits right before the gate or the output port to assert and verify if the data that exits the data product channel follows all the specifications.
The contracts can be created, manipulated, or deleted by data owners or producers who are closest to the domain and understand the business well. They can lay down the required policies and quality assessment conditions aligned to industry standards and can update the same periodically based on changes in the industry.

The above also decouples the data from the purview of the data developer, who only has a partial view of the business, saving him/her dozens of iterations with business teams. The same concept decouples changes from affecting multiple pipelines or other output ports, ensuring most of the endpoints are healthy and running even if one goes down.
What it means for data developers?
The lives of data developers drastically improve with the advent of Data Contracts, and indirectly, it is also the lives of business stakeholders and customers which improve as a consequence.
Data Developers don’t need to wander around talking to multiple stakeholders to capture partial business views and the meaning of the data they are enabling.
They don’t need multiple iterations to fix incorrect or insufficient information.
They don’t need to spend countless hours on fixing an overwhelming number of pipelines due to an untraceable upstream change.
They are relieved from the custodianship of data quality and governance and simply become enablers.
They can declaratively call for complex specifications and let the data developer platform translate the specs from contracts and implement them on demand.
They don’t need to take responsibility for the data since it passes on to the data contract and the creators of the contract.

Final Note
In summary, contracts are a simple addition to the unified data architecture and singlehandedly simplify data stack usage. Implementation of contracts can seem confusing and mammoth at first, given most teams don’t understand where the contract exactly sits in their infrastructure. Additionally, the fact that there’s no standardised version of contracts accepted and implemented industry-wide add to the misery.
However, given contracts are well-tied to a unified design, inclining towards a unified infrastructure is a low-hanging fruit, especially since such a design does not disrupt the existing setups, but gradually optimises the architecture, processes, and habits.
The unified design could be complex to explain but is extremely lightweight and easy to launch given the seamless hierarchical levels - achieving layers of complexity by first establishing the simplest first-order solutions or building blocks. It has proven to be a milestone detail for us as well as for our customers who are experiencing long-term benefits after investing only a few weeks of effort to establish a unified base.
To understand how a unified design could be non-disruptive or how it is effective within weeks instead of months and years, feel free to read a couple of the following pieces (shared below), keep watching this space for new entries, or directly reach out to me on LinkedIn.
Since its inception, ModernData101 has garnered a select group of Data Leaders and Practitioners among its readership. We’d love to welcome more experts in the field to share their story here and connect with more folks building for better. If you have a story to tell, feel free to email your title and a brief synopsis to the email-ID below:
The Essence of Having Your Own Data Developer Platform

TOC What is a Data Developer Platform (DDP) Conceptual Philosophy of DDP Outcome of a DDP Fundamental Principles of a DDP First Principles Design Approach Implementing Your Own DDP
Evolution of the Data Stack: The story of how we interpret ever-growing data

TOC The Stepping Stone: The Traditional Data Stack and why it became obsolete The Obvious Next Step: The Modern Data Stack & the MAD ecosystem The Solution: The Data-First Stack Defining Factors of a Data-First Stack Outcome of a Data-First Stack Summary
Data-First Stack as an enabler for Data Products

Last week, I published a piece on the Evolution of the Data Stack, and the community resonated well with the story of how the data industry has been interpreting data and the potential way it could effectively manage ever-growing data. Not surprisingly, the