
7 Minutes to Understand the New Spark Streaming Feature that Changes Everything
How Spark 4.1’s Real-Time Mode Breaks the Micro-Batch Barrier and Brings Millisecond Latency to Structured Streaming

About Our Contributing Expert
Vu Trinh | Data Engineer
Vu Trinh is a Data Engineer and educator known for breaking down complex data engineering concepts into simple, structured explanations. Currently working at Amanotes, a music game company, Vu combines hands-on industry experience with a deep passion for learning and teaching.
He is the creator of VuTrinh, a fast-growing newsletter read by 17,000+ data engineers worldwide. Through long-form articles and curated weekly resources, Vu explores everything from Apache Spark internals and lakehouse table formats to BigQuery pricing models and the evolution of data engineering itself. His writing is practical, research-driven, and grounded in first principles.
Based in Ho Chi Minh City, Vu’s mission is simple: cut through shallow content and help engineers truly understand how data systems work under the hood. As he often says, his mom started reading his articles to support her son, and now she can design data architectures and write ETL scripts! We’re thrilled to feature his unique insights on Modern Data 101!
We actively collaborate with data experts to bring the best resources to a 15,000+ strong community of data leaders and practitioners. If you have something to share, reach out!
🫴🏻 Share your ideas and work: community@moderndata101.com
*Note: Opinions expressed in contributions are not our own and are only curated by us for broader access and discussion. All submissions are vetted for quality & relevance. We keep it information-first and do not support any promotions, paid or otherwise.
Let’s Dive In
Apache Spark now cares about the ultra-low latency.

When it comes to stream processing, everybody usually brings Spark and Flink to the table. Flink is famous for its true stream processing: every record is processed continuously, nearly as soon as it arrives. Spark Structured Streaming, on the other hand, relies on its batch-processing engine to process a continuous stream in microbatches.
The latency is indeed higher than Flink’s; however, Spark has the advantage of its user base: many users already use Spark, and if they want to switch from batch to stream processing, they only need to tweak the code a bit.
Thus, you commonly see advice like this: “Only if you actually need millisecond latency, invest in Flink. Spark is still a good choice for second-tier latency use cases, given its simplicity and familiarity (Flink has a steep learning curve and requires significant resources to manage).
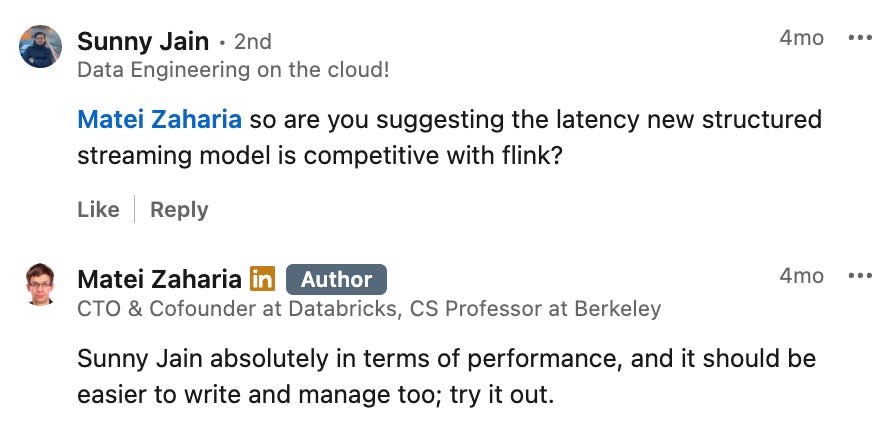
However, in the latest version, Spark introduced a new mode for Spark Structured Streaming that promises to overcome the limitations of the original approach and achieve millisecond latency, similar to Flink. The cofounder of Databricks said that this new mode could offer the latency competitive to Flink:
In this article, we will dive into Spark Structured Streaming’s real-time mode to see how this feature could change the “latency game” in stream processing. We will first briefly review Spark and Spark Structured Streaming to understand their limitations in low-latency scenarios better; only then will we see how the new streaming feature addresses them.
This article only has a brief overview of Spark and Spark Structured Streaming. For the deep dives, you can check these two articles:
Spark Cluster
Spark is a distributed processing engine. Thus, there must be a cluster of nodes.
Every Spark application is associated with a Spark cluster, which comprises a driver and a set of executors. All of these nodes are JVM processes that consume resources from a physical cluster, which consists of physical machines and is managed by the Cluster Manager process.

When you submit your application, the cluster manager first initiates the driver on one of the physical machines (if you run it in cluster mode). The driver contacts the cluster manager to launch the executor.
Anatomy
 of stages for a Spark job. The DAG ensures that stages are scheduled in topological order. Task: A task is the smallest unit of execution within Spark. Each stage is divided into multiple tasks that process data in parallel across different partitions. | Modern Data 101")
Spark has hierarchical processing units:
Job: A job represents a series of transformations applied to data. It encompasses the entire workflow from start to finish.
Stage: A stage is a job segment executed without data shuffling. A job is split into different stages when a transformation requires shuffling across partitions.
DAG: In Spark, RDD dependencies are used to build a Directed Acyclic Graph (DAG) of stages for a Spark job. The DAG ensures that stages are scheduled in topological order.
Task: A task is the smallest unit of execution within Spark. Each stage is divided into multiple tasks that process data in parallel across different partitions.
Scheduling
To provide the executor with tasks to run, the driver must first plan execution based on the user-defined logic. Then the driver starts scheduling the execution according to the plan.

This scheduling process involves some components (which also live inside the driver):
The DAGScheduler for stage-oriented scheduling
The TaskScheduler for task-oriented scheduling
The SchedulerBackend interacts with the cluster manager and provides resources to the TaskScheduler.
The DAGScheduler schedules stages according to the DAG’s topological order. Each stage is submitted once all its upstream dependencies are completed. If stages don’t have dependencies on each other, they can be run in parallel.
Remember this: Stages are scheduled in topological order.
The DAGScheduler creates fully independent, unprocessed tasks for that stage. Then, the DAGScheduler sends them to the TaskScheduler. This component is responsible for scheduling those tasks on available executors. It requests resources from the SchedulerBackend to schedule tasks.
The Micro-batch Structured Streaming
Overview
After the revision on how Spark works, it is straightforward to understand how Spark Structured Streaming operates.
Its core design principle is to treat a continuous stream as a bounded dataset. When we start a streaming application in Spark Structured Streaming, we create a long-running Spark application (a Spark cluster).
The Driver process remains active at all times, managing the entire streaming query lifecycle. Each stream will have a trigger. This trigger determines when Spark checks for new data. When the trigger fires, the Spark engine does the following:
It queries the source (e.g., asks Kafka “what are the latest offsets?”).
It identifies the new data that has arrived since the last batch (e.g., Kafka offsets 1001 to 5000).
This chunk of new data is a micro-batch. Internally, Spark treats it as a static DataFrame.
. It identifies the new data that has arrived since the last batch (e.g., Kafka offsets 1001 to 5000). This chunk of new data is a micro-batch. Internally, Spark treats it as a static DataFrame. | Modern Data 101")
And for every micro-batch, things will happen pretty much like how batch processing works in Spark: the driver, parse the logic, create/optimize plan, and schedule the stages in order.

The Delay
Although the current Spark Structured Streaming approach can leverage Spark’s robust batch engine for stream processing, it has some disadvantages, especially regarding the low latency performance:
First, the stages are scheduled in order, which means the stage can only be scheduled when all its upstream stages are completed.

For every batch, the driver needs to coordinate the communication between the nodes, parse, plan, schedule the stages/tasks, and commit the output. These overheads are included in each record-processing latency.

That’s why some online sources suggest that if you prefer super-low latency, you should go with Flink rather than Spark.
The Real-time Mode
However, the Spark 4.1 release (Dec 16, 2025) released a very cool feature: Structured Streaming Real-Time Mode (RTM).
Databricks introduced this feature in 2025 August and later contributed it to the community version. (Source)

The RTM targets millisecond latency for use cases, while the original micro-batch is suitable for seconds-latency use cases. RTM achieves this through these clever changes (not exhaustive, but I believe these are the crucial changes)
Consuming Fresh Data
In micro batch mode, the source reading process occurs only when a trigger is present. In real-time mode, the engine keeps reading fresh, available data from the source in longer-running batches (default: 5 minutes).

Stages Scheduled Concurrently
Unlike in (micro)batch processing, where stages are scheduled sequentially, RTM schedules all stages concurrently, eliminating wait time for upstream stages before scheduling a new one.

Longer batches and concurrent scheduling of stages mean lower coordination and planning overhead.
Streaming Shuffle
If you work with Spark, you must know about data shuffle. There are two transformations in Spark: narrow and wide dependencies.
The first is where each partition in the child RDD has a limited number of dependencies on partitions in the parent RDD. These partitions may depend on a single parent (e.g., the map operator) or on a specific subset of parent partitions known beforehand (e.g., with coalesce).
This means that operations like map and filter do not require data shuffling. RDD operations with narrow dependencies are pipelined into a single set of tasks per stage (e.g., map and filter can be baked into a single stage)

The latter requires data to be partitioned in a specific way, where a single partition of a parent RDD contributes to multiple partitions of the child RDD. This typically occurs with operations such as groupByKey, reduceByKey, or join, which involve data shuffling. Consequently, wide dependencies result in stage boundaries in Spark’s execution plan.

Thus, when a shuffle occurs, data must be exchanged between executors.
When thinking about Spark, people often assume that every operation must run in memory. That’s not 100% true. Although Spark tries to keep data processing in memory and spills only when needed, data shuffling occurs on the executor’s local disk.
The “map” tasks will write shuffle data to the executor’s local disk. They first write data to a memory buffer. When the buffer is full, they spill data to temporary disk files and merge them into the final shuffle files.

The “reduce” tasks communicate with the shuffle service, pull data from the target executor’s local disk into the memory buffer, and then start the processing.
However, exchanging data like this might not meet the RTM latency requirement.
Thus, RTM allows data to be passed between stages as soon as it is produced using an in-memory streaming shuffle.

Note: I only know that streaming shuffle allows for faster data exchange between stages in memory. I can’t find the details of the streaming shuffle implementation anywhere at the moment. Hope more resources are released in the future.
Checkpointing
In micro-batch mode, checkpointing is done straightforwardly. During the planning phase, the driver already knows which data ranges (the batch) the cluster must process, and the start and end of that batch are written to the checkpoint location before processing.
However, in real-time mode, things become more challenging because the driver doesn’t know the batch’s end boundary beforehand.
Thus, the strategy must change a bit.
Checkpointing occurs only at the end of batch processing, rather than at the beginning.

If the batches have a wider data range, RTM checkpointing occurs less frequently, reducing overhead but increasing the read workload because the engine must read a broader range of data from the source when failures occur.
If the batch is smaller, checkpointing occurs more often, which harms the low-latency. When failure happens, the recovery process might be faster as it reads a narrower range of data from the source.
My Thoughts
The key thing about this feature is that the user only needs to make a minor change to the micro-batch code.
The user needs to change the trigger to RealTimeTrigger. Source

This convenience allows users to seamlessly switch to the new mode if the latency performance of the original Spark Structured Streaming does not satisfy them anymore
For me, this is a game-changer.
In the past, the only way to achieve that lower-latency performance was to use Flink. However, managing, operating, and developing Flink requires significant effort (as much as you use Spark).
Now with RTM, users can consider this new mode instead of Flink. If users can leverage RTM, they don’t need more resources to manage Flink and still stay in the Spark ecosystem, which is a big win for any organization that has been investing in Spark (e.g., engineers who are only familiar with Spark)
Although the real adoption of RTM is still being observed, and Flink won’t be replaced anytime soon (its true stream processing capabilities, robust watermarking, and state management still make it a strong stream processing engine), RTM will change how companies choose a stream processing engine.
Final Note
I opened this article out of curiosity about Spark Structured Streaming’s real-time mode, which promises to deliver competitive low-latency performance compared to Flink. Then we have a brief review of how Spark works as a cluster, its processing units, and the scheduling process. Next, we revisit Spark Structured Streaming, which processes continuous data in small batches, each handled in the same way as Spark batch processing.
From there, we understand the factors that impact the latencies of the micro-batch processing approach. Finally, we see how the real-time mode solves these problems by consuming fresh data, scheduling stages concurrently, using a streaming shuffle, and employing a different checkpointing strategy.
Thank you for reading this far. See you in my next articles.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect

Connect with Vu Trinh on LinkedIn 💬 | Or dive into his work on Substack:

From MD101 team 🧡
🌎 Global Modern Data Report 2026
The Modern Data Report 2026 is a first-principles examination of why AI adoption stalls inside otherwise data-rich enterprises. Grounded in direct signals from practitioners and leaders, it exposes the structural gaps between data availability and decision activation.
With hundreds of datapoints from 500+ data leaders and experts from across 64 countries, this report reframes AI readiness away from models and tooling, and toward the conditions required and/or desired for reliable action.

References
[1] Databricks, Real-Time Mode Technical Deep Dive: How We Built Sub-300 Millisecond Streaming Into Apache Spark™ (2025)
[2] Databricks, Real-time mode in Structured Streaming Documentation
 | A guest post by
|
Great summary. I wonder how we could go from "if stages have upstream dependencies we schedule them sequentially" to "we schedule stages co currently". How does this work exactly in RTM?