
The Semantic Medallion: Building a Knowledge Graph-Powered Data Catalog
How you can transform raw data sources into a unified knowledge graph in four lines of Python

About Our Contributing Expert
Veronika Heimsbakk | Knowledge Graph Specialist, Author, and Speaker

Veronika Heimsbakk is a Knowledge Graph specialist, semantic technologies expert, author, and international speaker known for transforming chaotic, unstructured data into rich semantic systems that both humans and machines can reason with. Currently working at Data Treehouse, she specialises in knowledge graphs, SHACL, ontology engineering, information architecture, and AI-ready semantic ecosystems.
Veronika is the author of the widely recognised book SHACL for the Practitioner and has become a prominent voice in the global semantic web and knowledge graph community. She has led ontology and semantic architecture initiatives across public sector, maritime, automotive, and life sciences organisations, including work with the Norwegian Maritime Authority and The National Archives of Norway. Previously, she held leadership roles at Capgemini, where she helped drive semantic technologies, knowledge graph adoption, and GenAI initiatives across the Nordics.
Beyond enterprise architecture and AI, Veronika is deeply passionate about STEM education, makerspaces, and communicating complex technical concepts with clarity and humanity. A frequent conference speaker and guest lecturer at the University of Oslo, she advocates for the growing importance of knowledge representation in the era of AI and predictive systems. We’re thrilled to feature her insights on Modern Data 101.
We actively collaborate with data experts to bring the best resources to a 20,000+ strong community of data leaders and practitioners. If you have something to share, reach out!
🫴🏻 Share your ideas and work: community@moderndata101.com
*Note: Opinions expressed in contributions are not our own and are only curated by us for broader access and discussion. All submissions are vetted for quality & relevance. We keep it information-first and do not support any promotions, paid or otherwise!
Let’s Dive In
Every data engineer knows the medallion architecture: Bronze (raw), Silver (cleaned), Gold (business-ready). It’s become the standard pattern for data lakehouses.
But what if your Gold layer wasn’t just “clean data in nice tables”? What if it were a knowledge graph, where every record understands its relationship to every other record, across all your sources?
This article draws from practical observations based on the work we have done for a client.
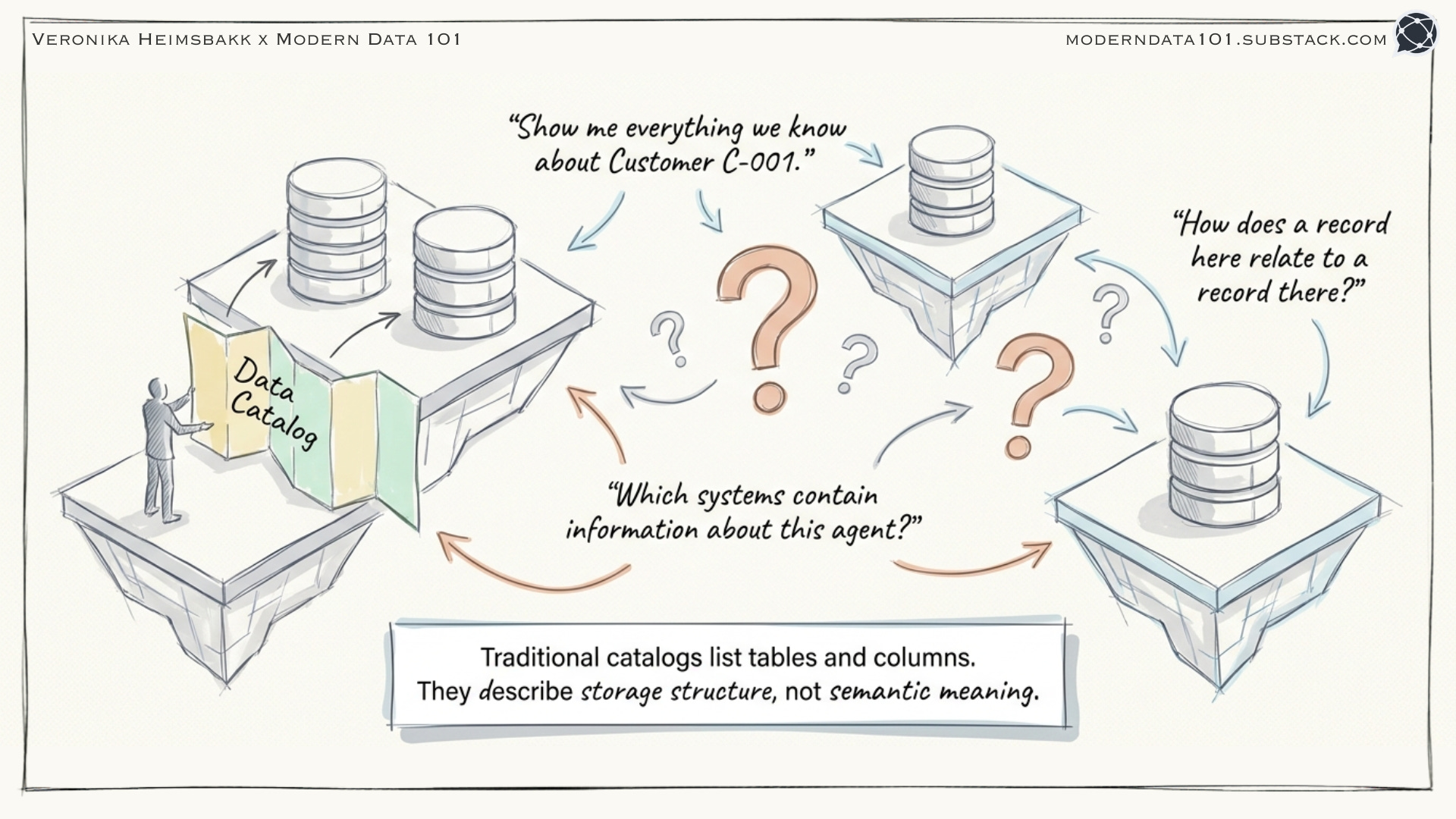
The Problem: A Data Catalog That Actually Connects Things
The client had a familiar challenge: several data sources, each describing overlapping concepts from different angles, to a greater or lesser extent.
They are building a data catalog and exploring the wonders of knowledge graphs and semantic technologies. We’re not building a static list of tables and columns, but something that could answer questions like:
“Show me everything we know about this record.”
“Which data sources contain information about this agent?”
“How does this record in System A relate to that record in System B?”
Traditional data catalogs struggle with this. They can tell you where data lives. They can’t easily tell you how it connects.
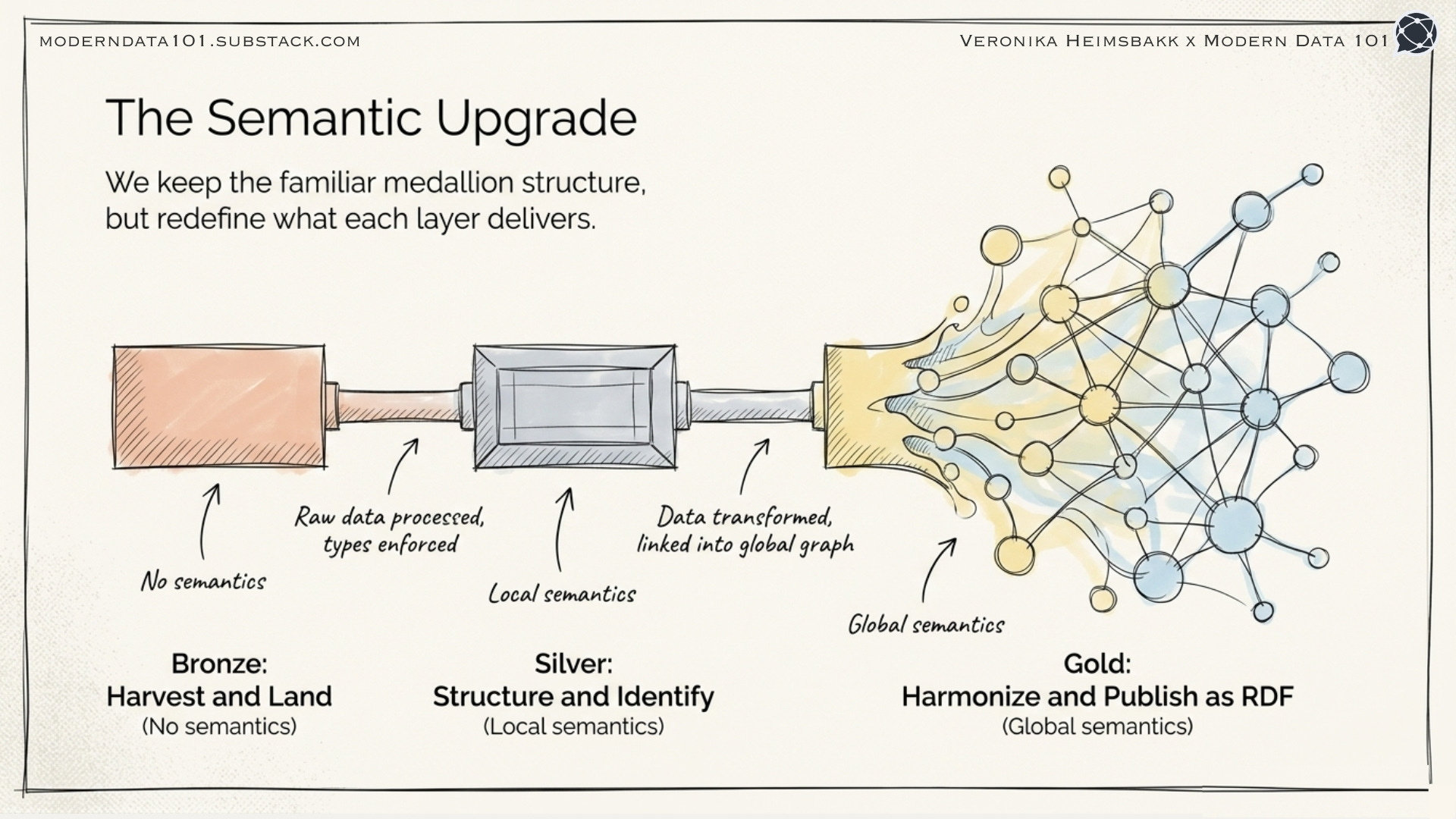
The Architecture: Medallion Meets Knowledge Graph
We kept the familiar medallion structure but redefined what each layer delivers:
Bronze: Harvest and Land
Standard practice. We used data orchestration tools with connectors to pull from various sources: APIs, databases, file shares, and external registries.
Raw data lands as-is. No transformations yet.
Silver: Structure and Identify
Here’s where it gets interesting.
Instead of just cleaning data and enforcing types, we added one crucial step: minting IRIs (Internationalized Resource Identifiers) for every entity.
Each record gets a stable, globally unique identifier. Not a database auto-increment ID. Not a GUID, which means nothing. An IRI that identifies the thing being described.

The IRI is the join key that works across all systems. Not just within one database, but across your entire data landscape.
Gold: Harmonize and Publish as RDF
This is where the magic happens.
We map Silver DataFrames to a shared ontology: a common vocabulary that describes what things mean and how they relate. Then we publish as RDF, ready for graph queries.
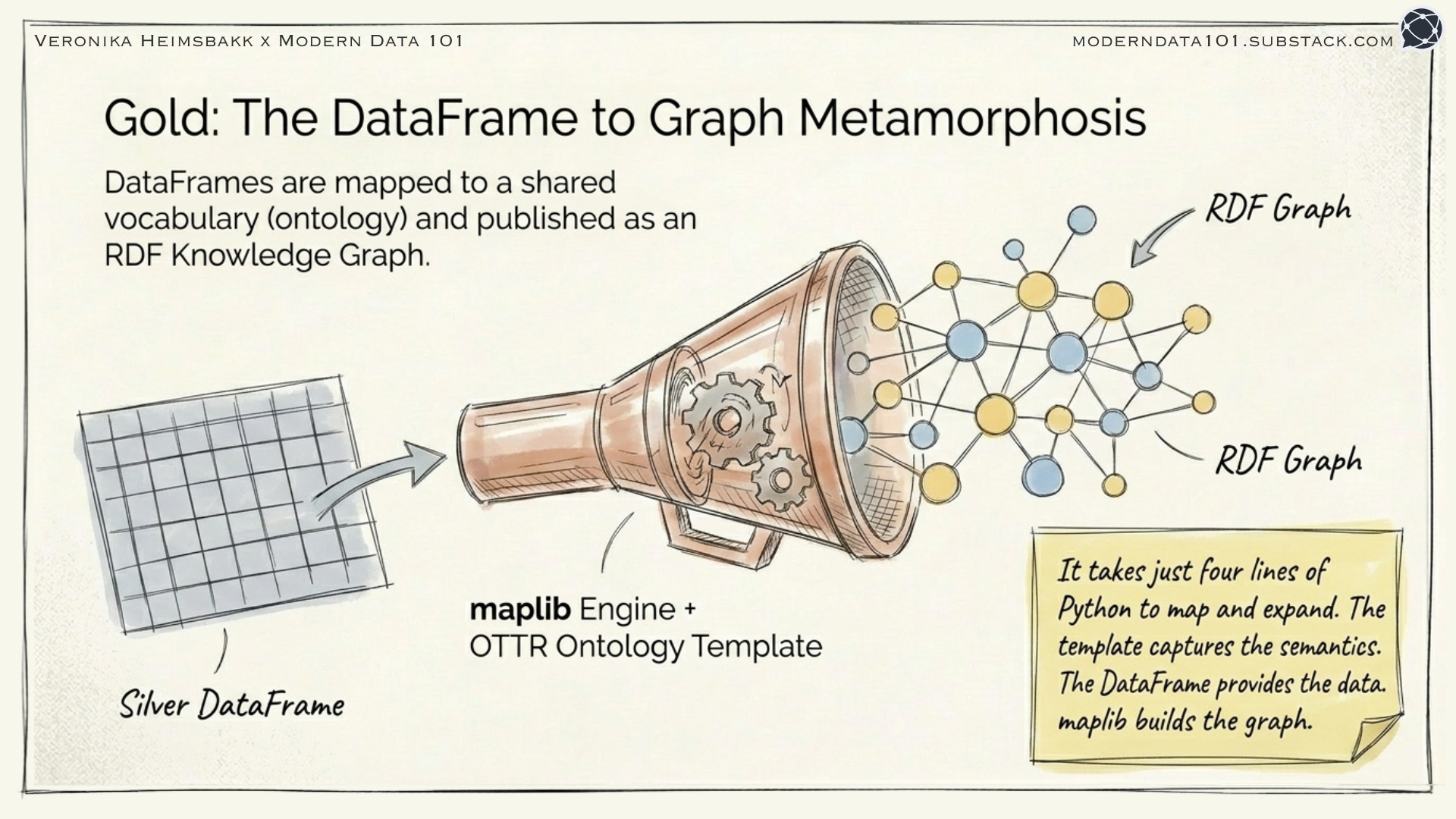
Four lines of Python:

That’s it! DataFrame to knowledge graph.
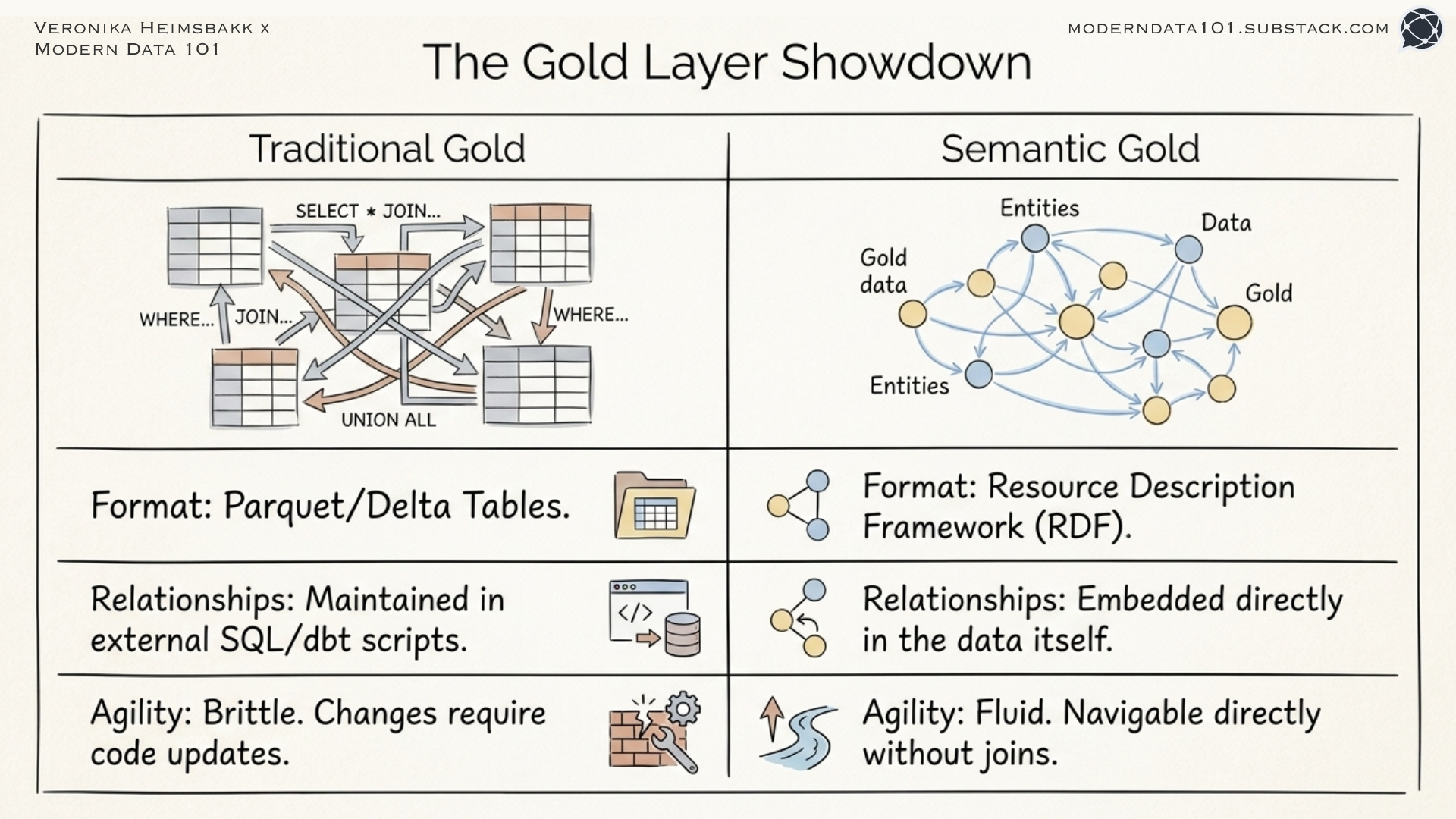
What the Gold Layer Actually Looks Like
Traditional Gold layer (Parquet/Delta):

Four separate tables. You write joins to connect them. You maintain the join logic in dbt or SQL scripts. When relationships change, you update code.
Our Gold layer (RDF)

The relationships are in the data. Not in join logic. Not in SQL scripts. In the data itself.
The Catalog Experience
With the knowledge graph in place, the data catalog becomes genuinely useful.
Query: “Show me everything about customer C-001”

Result: Every fact from every source, unified under one identifier.
Query: “Which sources contribute to our customer records?”

Query: “Find customers with billing issues who have active contracts”

No joins. No hunting through five different tables. The relationships are navigable directly.
The “Four Lines of Python” in Detail
Let me show you what those four lines actually do.
Step 1: Define a template
We use OTTR templates (stOTTR syntax) to map DataFrame columns to ontology properties:

Step 2: Map and expand

That’s the complete Silver-to-Gold transformation. The template captures the semantics. The DataFrame provides the data. maplib does the rest.
Why This Works for Data Catalogs
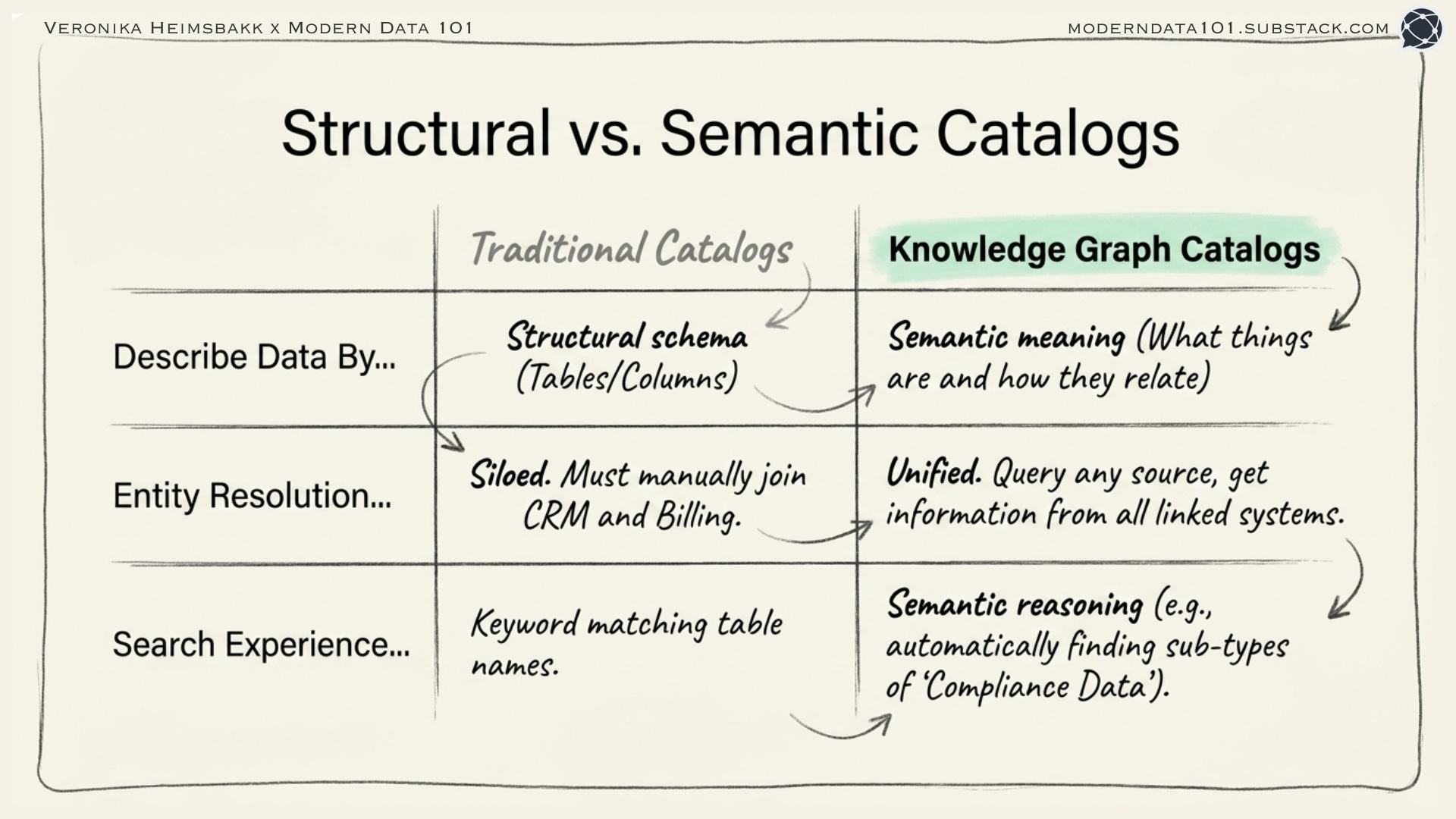
Traditional data catalogs have a fundamental limitation: they describe data structurally.
A knowledge graph-powered catalog describes data semantically. What things mean, how they relate, and what you can ask.
Three capabilities we gained:
1. Entity resolution across sources
When the same customer appears in CRM, billing, and an external registry, we link them:

Query any one, get information from all three.
2. Semantic search
“Find all entities related to financial compliance” doesn’t require knowing which tables contain compliance data. The ontology encodes that :ComplianceOfficer, :AuditRecord, and :RegulatoryFiling are all subtypes of :ComplianceRelated.
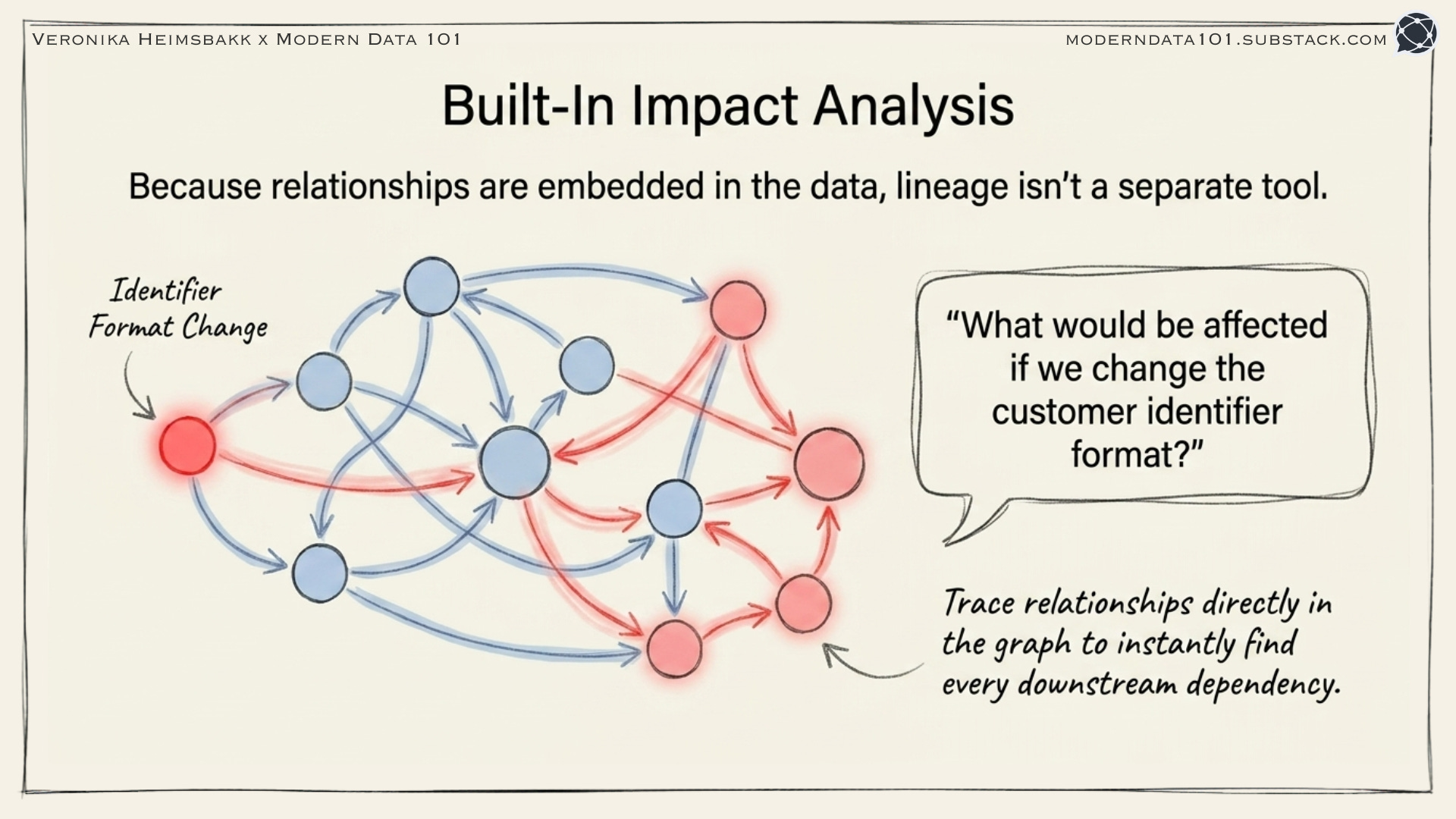
3. Impact analysis
“What would be affected if we change the customer identifier format?” Trace all relationships in the graph to find every downstream dependency.
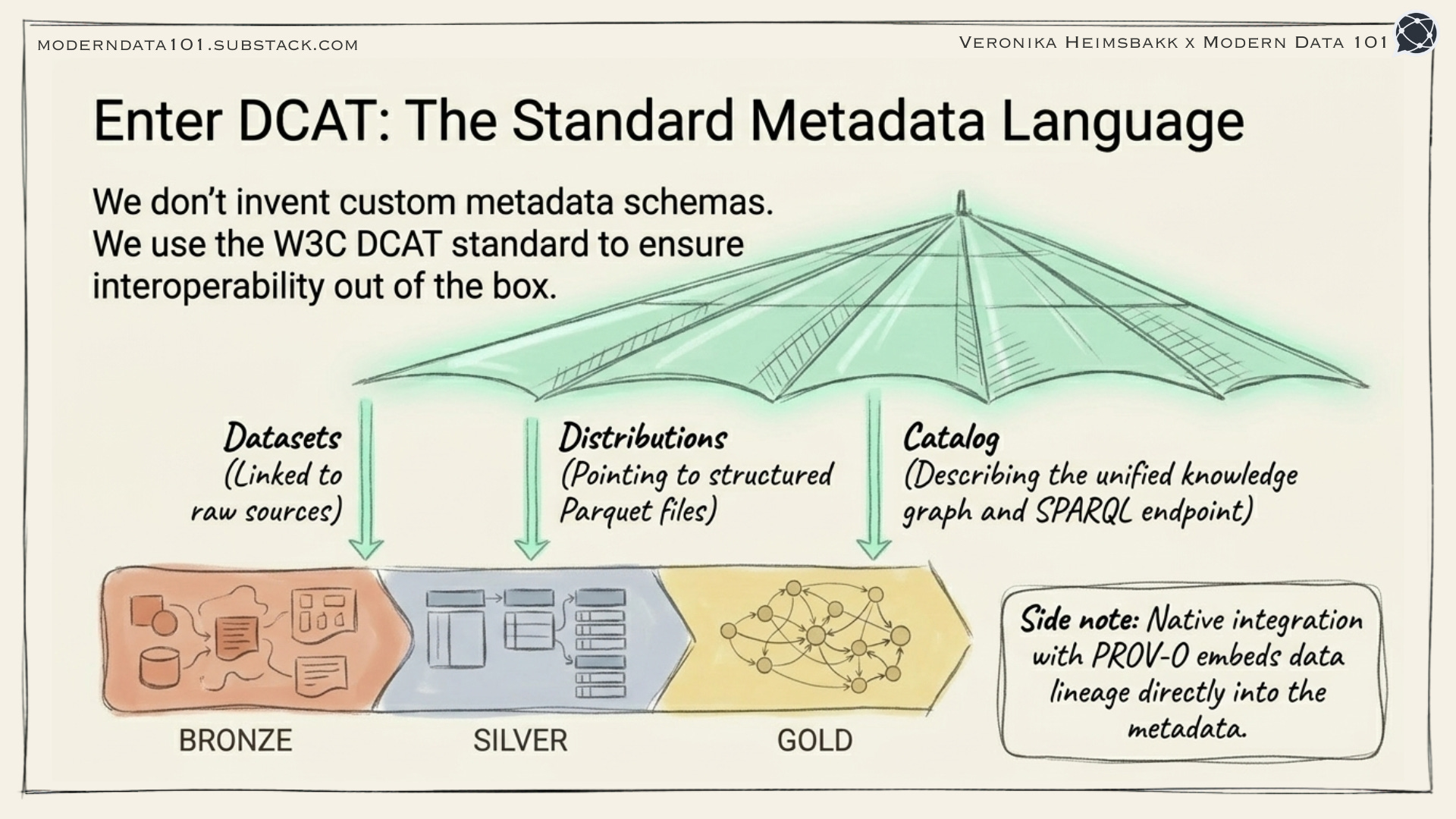
Enter DCAT: The Standard for Data Catalogs
Here’s where it gets even better. We didn’t invent a custom vocabulary for describing our datasets; we used DCAT (Data Catalog Vocabulary), a W3C standard designed exactly for this purpose.
DCAT gives you a ready-made ontology for describing:
Catalogs (dcat:Catalog): collections of datasets
Datasets (dcat:Dataset): logical groupings of data
Distributions (dcat:Distribution): how you can access the data (API, file download, SPARQL endpoint)
Data Services (dcat:DataService): APIs and endpoints that serve data
1. Interoperability out of the box
DCAT is used by data.gov, the European Data Portal, and thousands of organizations worldwide. When you describe your datasets with DCAT, you’re speaking a common language. Your internal catalog can federate with external catalogs. Your metadata is portable.
2. Rich metadata without reinventing the wheel
Instead of designing your own “dataset” schema, DCAT gives you:

Publishers, themes, access methods, formats, and lineage; all standardized.
3. It connects the catalog TO the data
Here’s the key insight: DCAT describes your datasets as RDF. Your data is also RDF. They live in the same graph.

Your catalog isn’t a separate system pointing at data; it’s part of the same knowledge graph. Metadata and data, unified.
4. Provenance and lineage are built-in
DCAT works seamlessly with PROV-O (the provenance ontology). You can trace where data came from:

Data lineage as queryable triples, not a separate lineage tool with its own database.
DCAT in the Architecture
DCAT becomes the glue between the medallion layers:
Bronze datasets: Described with DCAT, linked to their raw sources
Silver datasets: DCAT distributions pointing to structured Parquet files
Gold layer: DCAT catalog describing the unified knowledge graph, with SPARQL endpoint as distribution
The catalog isn’t a separate application; it’s part of the graph itself. Query the data, query the catalog, same endpoint, same language.
What We Learned
Start with IRIs early. The biggest challenge wasn’t the RDF conversion; it was establishing stable identifiers in the Silver layer. Do this first.
Ontology design is iterative. We didn’t design the perfect ontology up front. We started with what we had, mapped it, then refined as we discovered relationships.
The medallion pattern still applies. Bronze-Silver-Gold is a useful mental model. We just redefined what “Gold” means: not “clean tables” but “connected knowledge“.
“Four lines of Python” is real. maplib made the transformation tractable. Without it, we’d be writing plenty of lines of RDF serialization code.
The Bigger Picture
This project convinced me of something: the medallion architecture isn’t just about data quality layers. It’s about semantic enrichment layers.
Bronze: Raw data (no semantics)
Silver: Structured data with identifiers (local semantics)
Gold: Harmonized data with shared vocabulary (global semantics)
The Gold layer becomes a knowledge graph not because graphs are trendy, but because that’s what “fully enriched, connected, query-ready data” actually looks like.
Try It Yourself
If you’re curious about building something similar:
maplib: The Python library that makes DataFrame-to-RDF transformation practical
Start small: Pick two data sources that describe overlapping entities
Mint IRIs: The most important decision is how you identify things
Query it: Use SPARQL to explore relationships you couldn’t easily query before
The data catalog that actually connects things? It’s closer than you think.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 💬

Got questions or want to share your own experiments? Find Veronika on LinkedIn or drop a comment below. 💬
From the MD101 team 🧡
The Data Product Maturity Assessment

 | A guest post by
|