
The Semantic Infrastructure Opportunity: Building Meaningful Operational Frameworks
Ontology Pipeline as a strategic framework for semantic engineers to prove their professional value by linking abstract models to functional entity resolution

About Our Contributing Expert
Jessica Talisman
Knowledge Infrastructure Strategist, Founder & Advocate of The Ontology Pipeline Framework

Jessica Talisman is a Semantic Engineer, Information Architect, and knowledge infrastructure strategist dedicated to building information systems. With more than 25 years of experience in enterprise architecture, e-commerce content systems, digital libraries, and knowledge management, Jessica specialises in transforming fragmented information into coherent, machine-readable knowledge systems.
She is the founder of the Ontology Pipeline, a structured framework for building semantic knowledge infrastructures from first principles. The Ontology Pipeline emphasises progressive context-building: moving from controlled vocabularies to taxonomies, thesauri, ontologies, and ultimately fully realised knowledge graphs.
Professionally, Jessica has led semantic architecture initiatives at organisations including Adobe, where she architected an RDF-based knowledge graph to support Adobe’s Digital Experience ecosystem, and Amazon, where she worked in information architecture and taxonomy. She also founded Contextually LLC, providing consulting and coaching services in ontology modelling, NLP integration, and knowledge governance.
An educator and thought leader, Jessica publishes regularly on her Substack newsletter, Intentional Arrangement, where her writing frequently explores the relationship between semantic systems and AI. We’re thrilled to feature her unique insights on Modern Data 101!
We actively collaborate with data experts to bring the best resources to a 15,000+ strong community of data leaders and practitioners. If you have something to share, reach out!
🫴🏻 Share your ideas and work: community@moderndata101.com
*Note: Opinions expressed in contributions are not our own and are only curated by us for broader access and discussion. All submissions are vetted for quality & relevance. We keep it information-first and do not support any promotions, paid or otherwise.
Let’s Dive In
The Opportunity Before Us
Ontologists and semantic engineers face a persistent professional challenge to demonstrate that our work produces tangible value. We build controlled vocabularies, develop metadata standards, structure taxonomies, and design ontologies. Yet too often, these artifacts remain siloed rather than operational infrastructure.
Business stakeholders often struggle to connect our deliverables to measurable outcomes due to a lack of understanding about the mechanics of semantic systems.
Direct returns on investment prove difficult to quantify because the benefits of semantic knowledge systems tend to be secondary, reflected in downstream successes rather than standalone metrics.
Entity resolution changes this equation. When semantic infrastructure directly enables entity reconciliation (determining who is who and who is related to whom across data sources), our work becomes measurably operational.
Match rates improve. False positives decrease. Disambiguation succeeds where string matching fails. The thesaurus we build from entity resolution results becomes part of the critical infrastructure, which makes the use case work.
The emergence of tools like Senzing’s sz-semantics library and specifically, the Senzing thesaurus creates an inflection point for our profession. These tools leverage the Ontology Pipeline: the systematic methodology I have articulated for constructing semantic knowledge management systems to shape logic through executable code.
For taxonomists, ontologists and semantic engineers, this means our frameworks now have concrete tooling, with a methodology and deployable artifacts. While elegantly simple in its shape and code base, the Senzing thesaurus demonstrates how essential our expertise becomes as neurosymbolic AI solutions based upon Semantic Web principles emerge in the public repositories of enterprises.
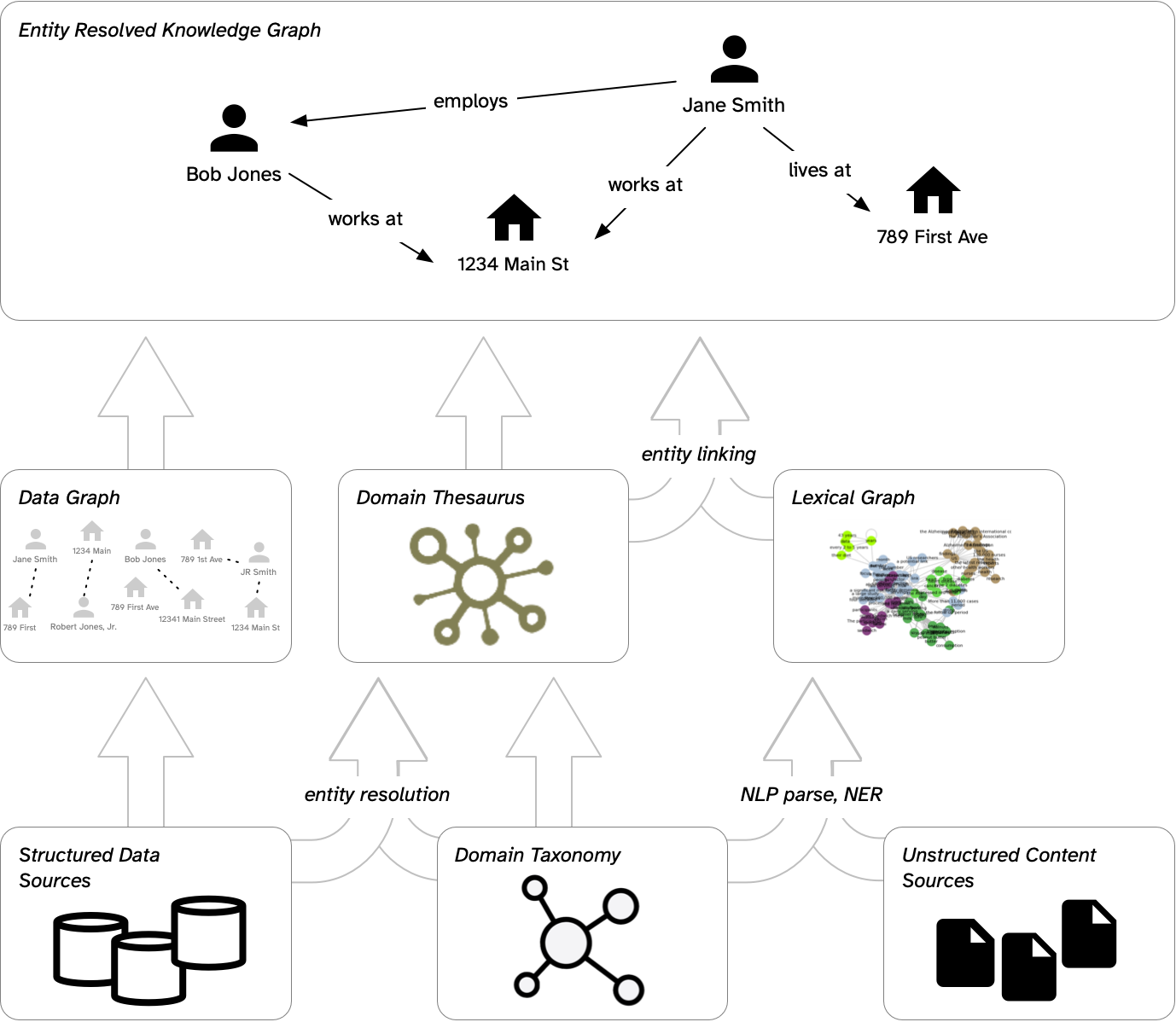
Why Entity Resolution Needs Us
Entity resolution engines excel at resolving multiple records from different data sources based on evidence, for which Senzing uses entity-centric learning. The system architecture supports the detection of names, addresses, phone numbers, identifiers, and other features that constitute entity profiles.
They handle messy, inconsistent data with remarkable sophistication, accommodating variations in spelling, formatting, and completeness that plague enterprise data integration. What they do not do or what they cannot do without semantic infrastructure is interpret what matches mean within a knowledge domain.
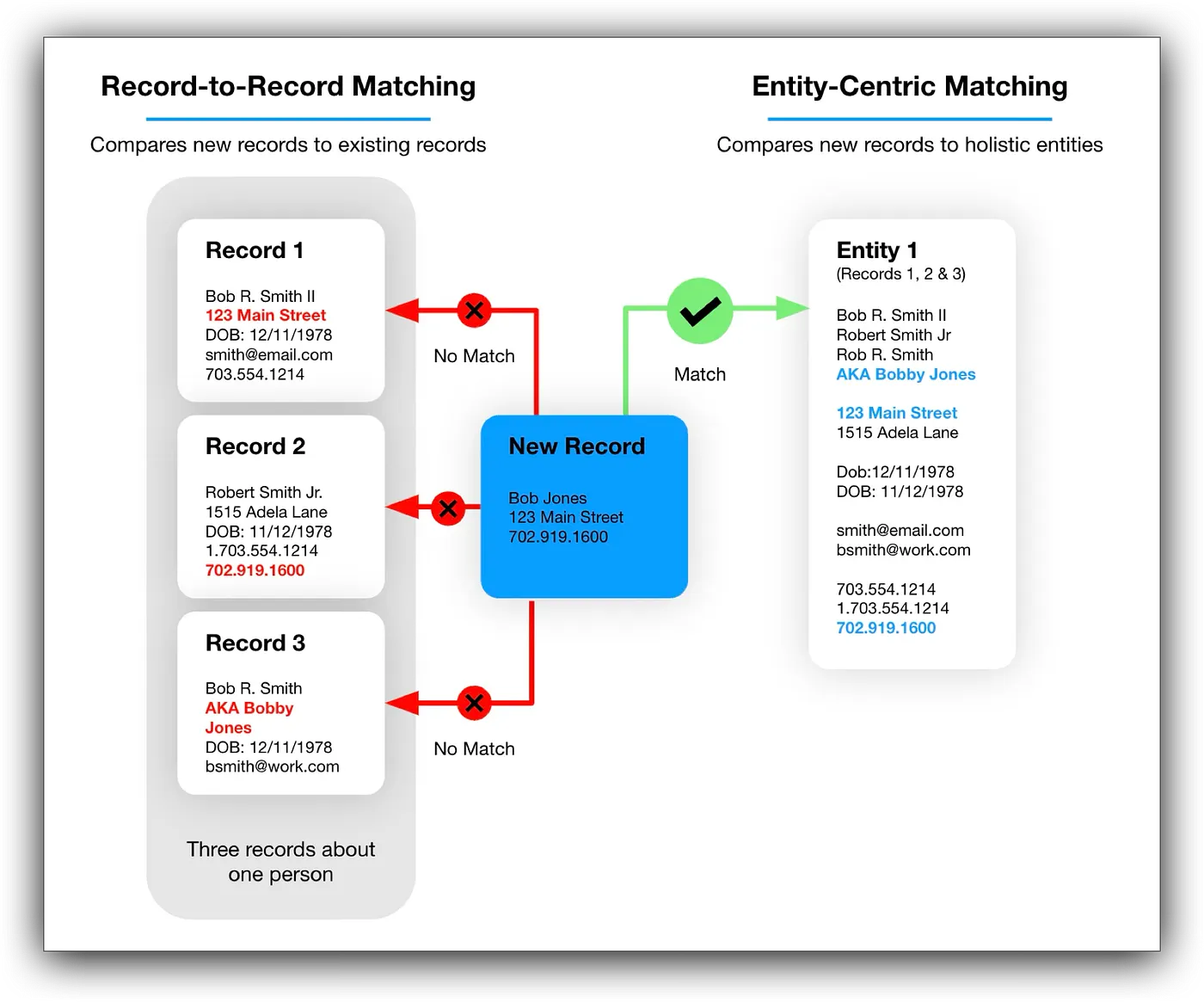
When entity resolution operates without our work, results remain technically useful but semantically isolated. The output captures what matches, but not why it matters. Two records merge because phone numbers align,
but what does that merged entity represent in the domain?
What relationships does it participate in?
What constraints govern its behavior?
Semantic engineering and ontologies can model and architect domains to answer these questions, thereby adding rich context and meaning to the underlying data.

On the way to building out supporting, semantic infrastructure, the Ontology Pipeline becomes essential. The pipeline’s iterative stages (controlled vocabulary, metadata standards, taxonomy, thesaurus, ontology, knowledge graph) prepare data and information for semantic interpretation.
Each stage builds towards maturing semantic systems to support the meaningful classification of resolved entities. Discovered relationships can be mapped to edges, where the ambiguity inherent in real-world data resolves through principled knowledge organization.
Machines love ontologies because of their high fidelity disambiguation and descriptive logic, which bring clarity to machine understanding.
Entity resolution produces candidate matches. But as ontologists and semantic engineers know all too well, the semantic infrastructure determines what those matches mean.
The Ontology Pipeline as Professional Framework
The Ontology Pipeline provides the technical methodology and professional framework for scoping, estimating, and delivering semantic engineering projects. When business stakeholders ask what ontology work costs or how long it takes, the pipeline offers concrete answers. Each stage has defined inputs, outputs, and success criteria. Each stage maps to identifiable skills and time investments.
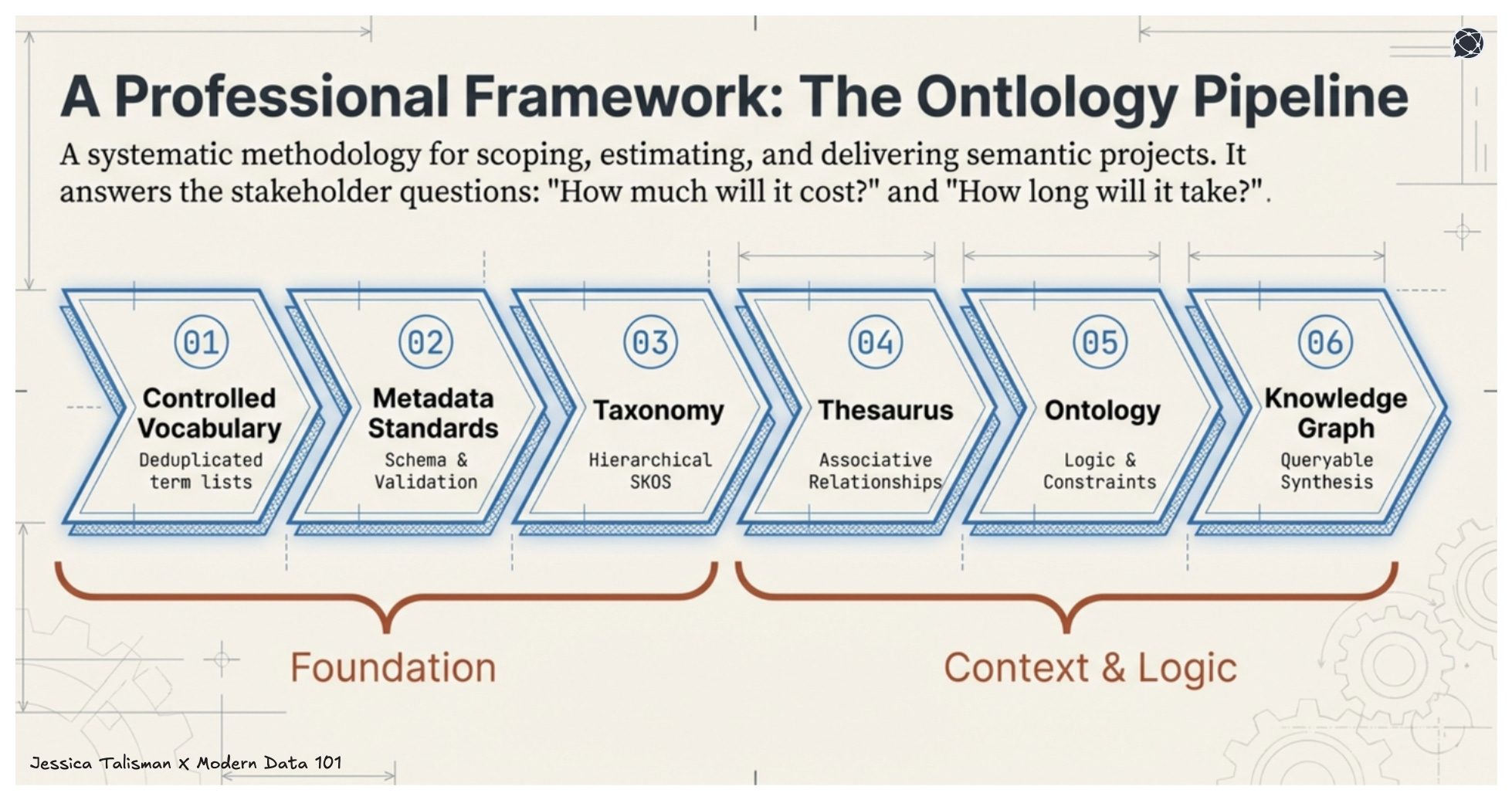
To build resilient systems that fit into the expectations of organizations, the pipeline’s defined stages translate to tangible project deliverables. Controlled vocabulary construction produces deduplicated, defined term lists with clear scope and cardinality.
Metadata standards development delivers schema documentation with element definitions, value constraints, and validation rules, informing semantic engineering products of how data traverses complex data ecosystems.
Taxonomy construction yields hierarchical concept schemes in SKOS format with defined depth and breadth.
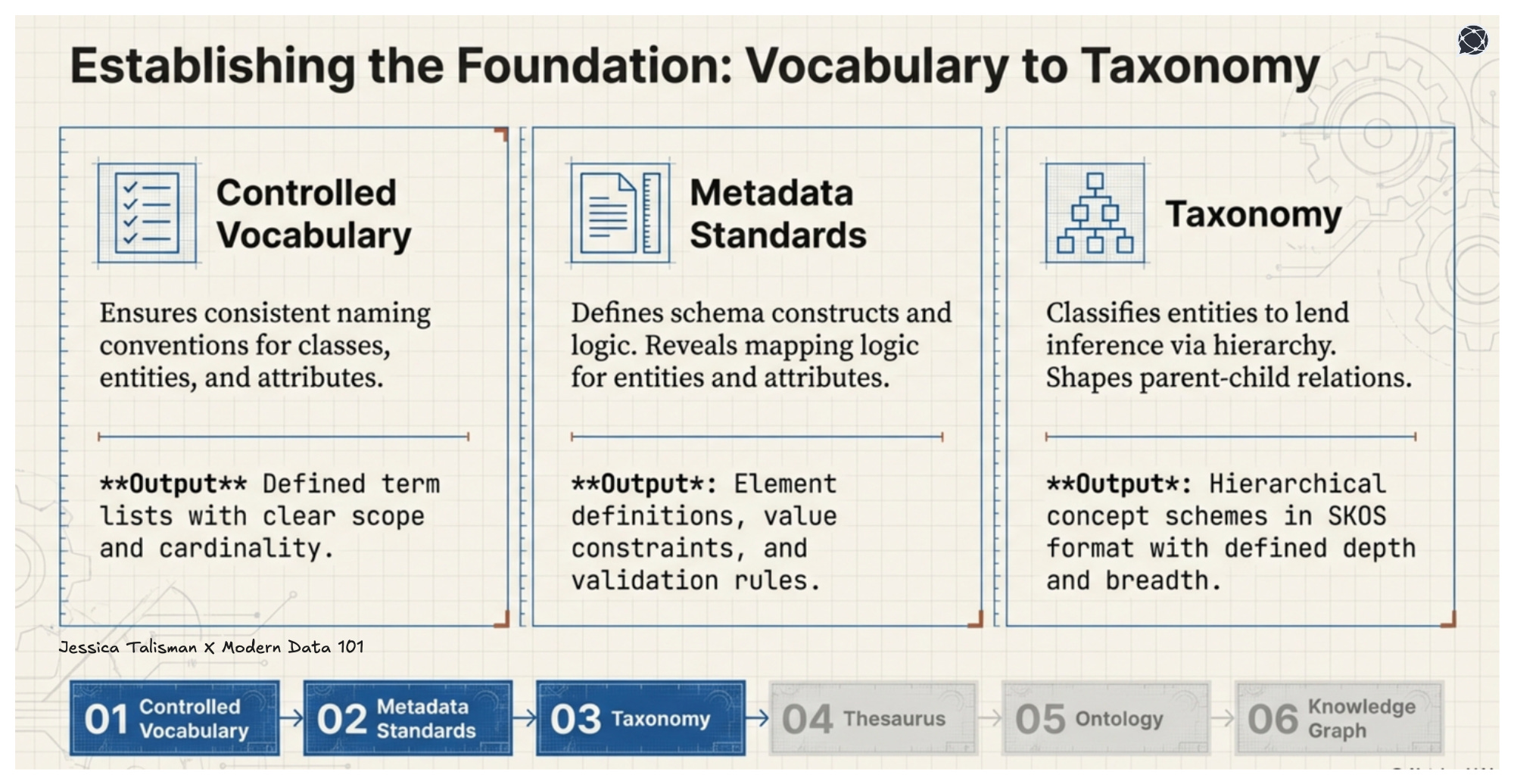
The thesaurus extends the taxonomy by adding associative relationships, synonyms, and cross-references that handle domain ambiguity. Ontology development introduces classes, properties, attributes, relations and logical constraints. Knowledge graph deployment represents an architecture that synthesizes all stages into a dynamic and queryable knowledge infrastructure.
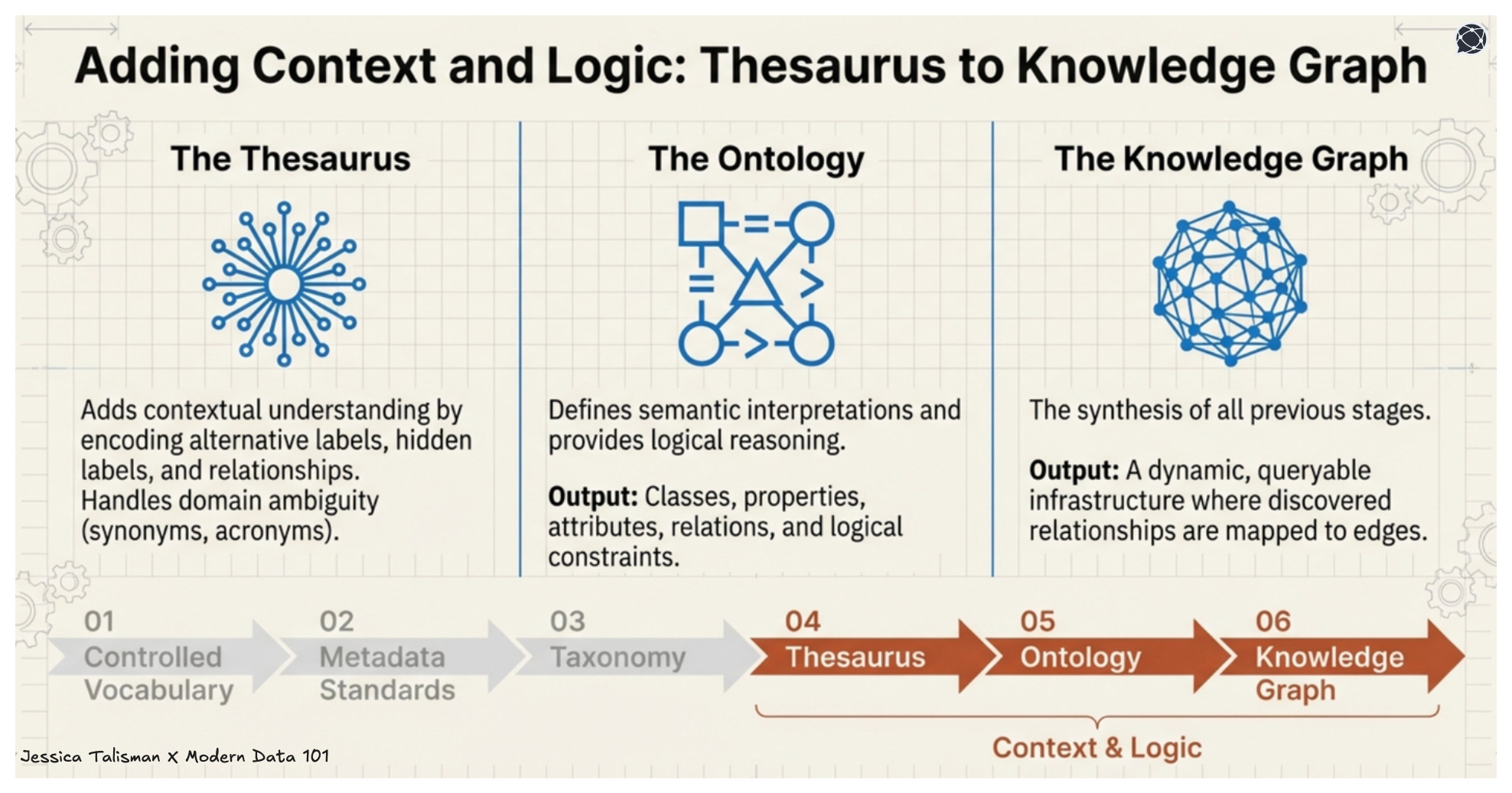
Each deliverable can stand on its own, and be easily purposed for specific needs and use cases. Each can be reviewed, validated, and versioned. Each contributes measurably to the semantic system’s capabilities.
When entity resolution connects to this pipeline, stakeholders and the business can understand exactly how ontology work enables data integration outcomes.
The controlled vocabulary ensures consistent class, entity and attribute naming conventions and definitions. Metadata standards define schema constructs and logic while also revealing the mapping logic for entities, classes and attributes. The taxonomy classifies entities, lending inference by way of a hierarchy that shapes parent-child relations.
The thesaurus adds more contextual understanding to the taxonomy by encoding alternative labels, hidden labels, relationships and documentation properties. The ontology defines semantic interpretations while providing logical reasoning. The knowledge graph can include all parts of the Ontology Pipeline, making it all queryable.
This is how we justify investment and build buy-in. Trust is formed when we move beyond abstract arguments and demonstrate how each pipeline stage directly enables entity resolution quality and contextual understanding for machines and humans.
The Thesaurus Stage, The Sweet Spot
Of all the Ontology Pipeline stages, the thesaurus is the low-fidelity powerhouse that can provide the most value to entity resolution. A thesaurus handles ambiguity by forming associative relationships between terms, going beyond the parent-child relationships within a hierarchy.
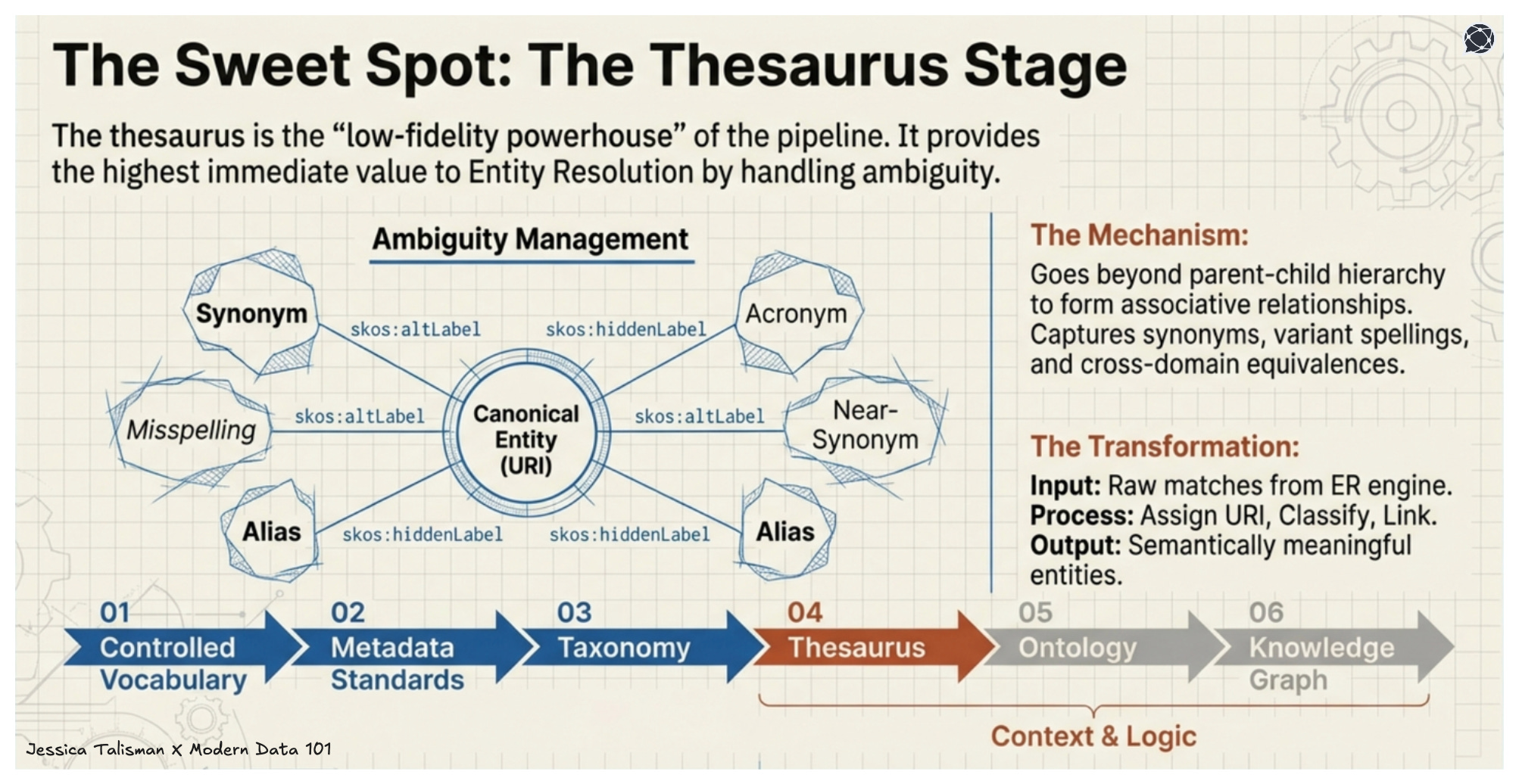
It captures synonyms, near-synonyms, variant spellings, acronyms, cross-domain equivalences and linked data enrichment. This is what entity resolution needs but cannot generate on its own.
When Senzing determines that records from different sources describe the same person, it performs a matching function. When the semantic thesaurus assigns that resolved entity a URI, classifies it within a taxonomy, and links alternative names as skos:altLabel relationships, it performs a knowledge organization function. The thesaurus transforms raw matches into semantically meaningful entities that participate in broader information ecosystems.
The sz-semantics library implements this transformation directly. Its Thesaurus class takes entity resolution results and a domain taxonomy as inputs, then generates RDF fragments that extend the taxonomy with resolved instance data. Alternative names discovered through matching become thesaurus relationships. Entity types map to taxonomy concepts. The output serializes a SKOS-compliant RDF formatted corpus, and applies these values to entity resolution outcomes.
For semantic engineers, this means our thesaurus expertise directly determines entity resolution quality.
The richer our synonym relationships, the better the system handles name variations.
The more precise our taxonomy classification, the more meaningful the resolved entity profiles. The more complete our associative relationships, the more discoverable the connections between entities. The thesaurus can provide the necessary support to imbue data with rich context and meaning.
Human-in-the-Loop: Expertise Becomes Essential
Automated entity resolution and semantic transformation cannot replace human judgment. The Strwythura project, which implements the complete Ontology Pipeline workflow, explicitly includes a human-in-the-loop curation stage.
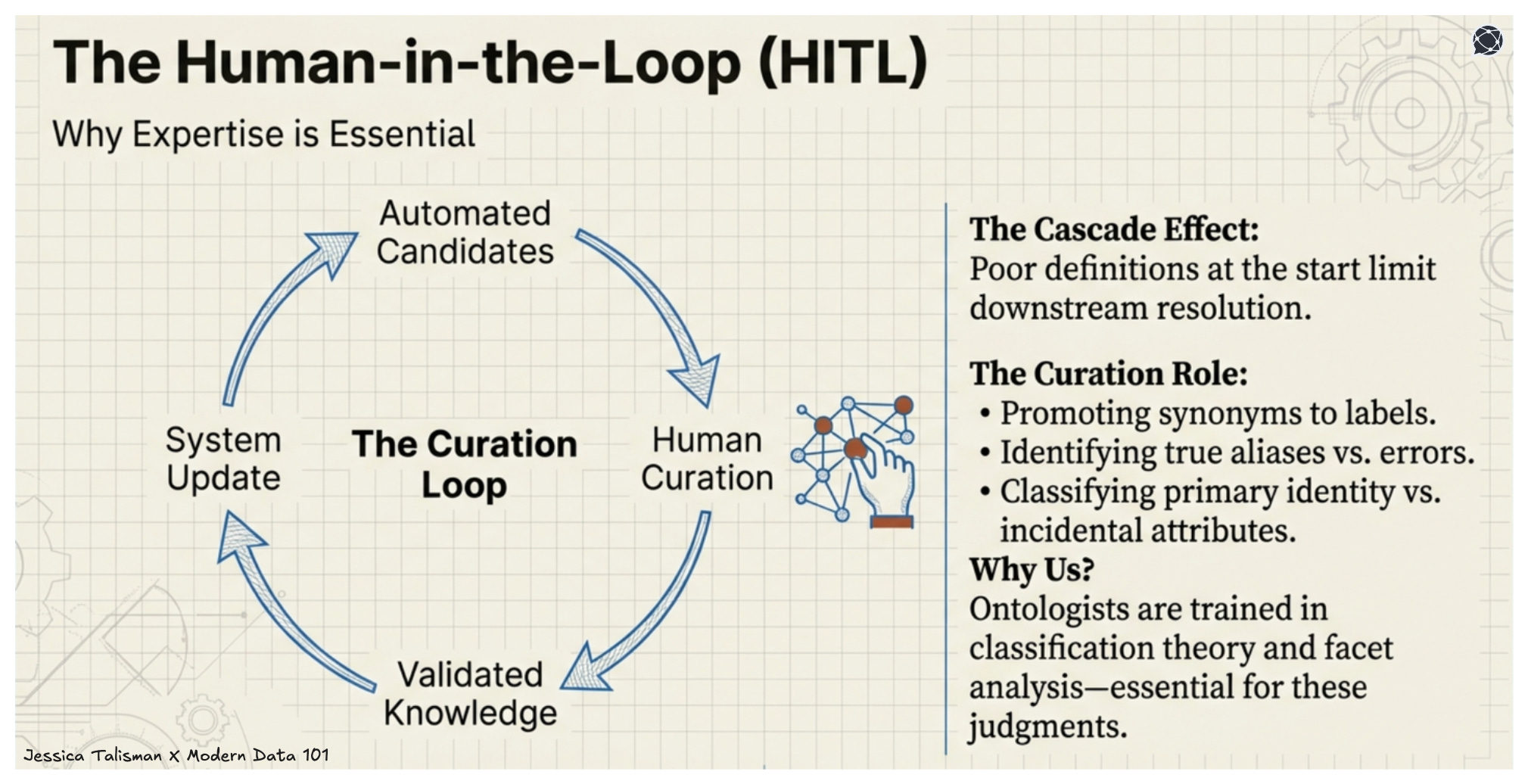
As noted in The Strwythura project’s GitHub readme, the human-in-the-loop (HITL) is an essential step, whereby
“humans curate definitions for entities extracted from the unstructured content...There is a ‘cascade’ effect, where the quality of entity definitions poses a limiting factor for how well the system can perform relation resolution downstream.”
Senzing formalizes HITL because it is instrumental to the success of semantically supported entity resolution, highlighting the critical importance of semantic quality and expert oversight.
What’s involved with curation exactly?
Entity resolution produces candidate matches with varying confidence levels. The semantic thesaurus assigns these entities to taxonomic categories based on available evidence.
Some assignments will be correct while others will require refinement.
Which synonyms should be promoted to preferred labels?
Which alternative names represent genuine aliases versus data entry errors?
Which taxonomic classifications capture the entity’s primary identity versus incidental attributes?
These are knowledge organization questions that semantic engineers answer through thesaurus construction and enrichment. Our training in classification theory, facet analysis, and vocabulary management prepares us to make exactly these judgments.
Our understanding of domain context enables us to recognize when automated assignments miss nuance. Our familiarity with SKOS and ontology engineering allows us to encode corrections in standard, machine readable, interoperable formats.
HITL curation prioritizes data quality and semantic integrity according to thesaurus and ontology standards. Entity resolution produces the matching framework while the thesaurus supports the capture of rich semantics and context, to ultimately enable reliability and accuracy.
While automated transformation produces candidates and matches, the thesaurus produces validated knowledge. As ontologists and semantic engineers, the Senzing thesaurus was engineered by ontologists with design decisions and judgment that defines our expertise.
NIEM: A Case Study in Pipeline Application
The National Information Exchange Model (NIEM) presents a compelling case study for ontologists applying the pipeline to entity resolution. NIEM already institutionalizes the first two pipeline stages: it provides controlled vocabularies for government information exchange and metadata standards that define how those vocabularies apply to data elements. For semantic engineers working in the public sector, NIEM represents existing infrastructure ready to be extended, with the objective.
Entity resolution challenges are at the core of NIEM use cases. Law enforcement agencies share suspect information across jurisdictions. Emergency management coordinates resources across organizational boundaries.
Immigration systems reconcile traveler identities from multiple sources. Each scenario involves determining who is who when data quality varies, terminology differs, and completeness fluctuates.
Applying the Ontology Pipeline, semantic engineers extend NIEM’s existing vocabulary and metadata foundations into taxonomy, thesaurus, and ontology stages.
Through the Senzing RDF thesaurus, we map SKOS concept schemes to NIEM data components, organizing elements, types and attributes through matching frameworks based upon vocabulary concept definitions and semantic relationships.
We build thesauri that capture the alternative terminologies different agencies use for the same concepts. We develop ontologies that constrain how NIEM-compliant data participates in entity resolution.
The NIEM-Senzing mapping exercise is semantic engineering work. Aligning NIEM element definitions with Senzing feature types (NAME_FULL to nc:PersonName, ADDR_LINE1 to nc:LocationStreet, organizational identifiers to NIEM organization components) constitutes a crosswalk, leveraging thesaurus concepts and properties to support resilient mapping and transformer logic.
This mapping becomes a metadata standard, enabling entity resolution results to flow directly into NIEM-compliant information exchanges.
For ontologists working with the NIEM ecosystem, entity resolution integration represents an opportunity to demonstrate that semantic engineering enables interoperability outcomes.
Federated entity resolution across agencies becomes possible because semantic infrastructure ensures consistent definitions and interpretation. The thesaurus captures variant agency terminologies while the ontology enforces exchange constraints; the knowledge graph provides queryable access. Our work makes it work.
The Value of Ontology Work
Semantic knowledge systems are rapidly emerging as essential for achieving highly performant AI applications and services. Large language models require clean, well-structured, semantically enriched data to provide accurate and reliable results.
Knowledge graphs underpin retrieval-augmented generation systems that ground LLM outputs in verifiable facts. Entity resolution ensures that the entities referenced in AI responses correspond to accurate, real-world subjects.
The Ontology Pipeline positions semantic engineers at the center of this infrastructure. By following the pipeline’s rigorous, iterative process (cleaning, preparation, reconciliation, modeling, testing, enrichment, enforcement), we ensure the data quality that AI systems require.
Entity resolution validates that the knowledge we organize corresponds to reality. The semantic thesaurus ensures that the vocabulary AI systems use is consistent and unambiguous.
Tools like sz-semantics and Strwythura demonstrate that our frameworks support complex ecosystems, with or without AI. The Thesaurus class generates SKOS from entity resolution results. The pipeline workflow produces entity-resolved knowledge graphs ready for GraphRAG integration. Interactive visualization makes our work accessible to stakeholders who need to understand what the semantic system contains.
This architecture demonstrates the value of semantics in supporting complex knowledge infrastructures, and moreover, a professional opportunity. Semantic engineers and ontologists are essential to making semantic architectures such as Senzing’s a reality.
Entity resolution needs semantic engineers because matches without meaning are just data. The Ontology Pipeline provides the methodology; these tools provide the implementation; our expertise provides the quality, context and meaning. Ontologists make the knowledge work.
Getting Started With Designing for Infrastructure
For semantic engineers ready to apply the Ontology Pipeline to entity resolution, the work involves the familiar in addition to new tools, methodologies and applications.
Audit your existing semantic assets
What controlled vocabularies, metadata standards, taxonomies, and ontologies already exist in your organization? These represent completed pipeline stages. Assess their quality, coverage, and the SKOS compliance of controlled vocabularies. Identify gaps that entity resolution integration would expose.
Learn the Senzing Vocabulary and NIEM Vocabularies
The Senzing Entity Specification documents available entities and features: NAME_FIRST, NAME_LAST, ADDR_LINE1, PHONE, and dozens of others. Familiarize yourself with the NIEM standard, paying attention to the object-oriented logic of NIEM. NIEM organizes its standard by types, elements and attributes.
For further guidance, the NIEM Naming and Design Rules (NDR) specifies guidelines for creating data models, namespaces, schemas, and messages, in addition to guidelines for naming conventions, syntax, semantics and RDF crosswalks.
Understanding this vocabulary enables you to design crosswalks between your domain’s metadata elements and entity resolution features. This semantic engineering work is extremely effective at supporting interoperability while preserving rich semantics, entity reconciliation and mapping logic.
Structure Your Domain Thesaurus in SKOS
If your existing taxonomies use spreadsheets or proprietary formats, migrate them to SKOS. After your taxonomy is SKOS compliant, add alternative labels, hidden labels and definitions (if absent) to create your SKOS thesaurus. The SKOS taxonomy or thesaurus produces the TTL file that sz-semantics requires—and positions your taxonomy or thesaurus for broader semantic web interoperability.
Plan for Thesaurus Extension
Entity resolution will discover synonyms, variant spellings and acronyms that your current vocabulary does not include. These newly discovered terms can be integrated into a domain taxonomy or thesaurus and represented as alternative labels.
To support this work, establish governance processes for incorporating these discoveries. Define criteria for promoting matches to canonical semantic definitions. This is where your expertise in vocabulary management will be handy, and essential to operations.
Engage With the Tooling
The sz-semantics and Strwythura repositories are open source and documented. Work through the tutorials. Understand how the thesaurus class transforms entity resolution results. Identify where your semantic assets would integrate into the workflow. Prototype with sample data before proposing production integration.
Build the Business Case
Document how each pipeline stage contributes to entity resolution quality. Estimate time and cost for each deliverable. Define metrics that demonstrate semantic infrastructure value, such as match rate improvements, false positive reductions, and disambiguation successes. Speak the language of measurable outcomes.
The Moment
The Ontology Pipeline offers the framework to support semantic engineering, from documentation practices to infrastructure discipline. Entity resolution provides the use case that demonstrates this transformation concretely.
Controlled vocabularies enable consistent entities, classes relations, properties and attributes. Taxonomies classify resolved entities meaningfully, as concept classes. The thesaurus disambiguates and documents alternative names and documentation properties.
Ontologies encode the logical constraints and semantic interpretations. Ontologists and semantic engineers are critical to making this work happen, to build robust and resilient semantic knowledge infrastructures.
Tools like sz-semantics implement the pipeline stages as executable code. The thesaurus we build becomes the infrastructure that entity resolution depends upon. The SKOS concepts we define become the URIs that identify resolved entities globally. The associative relationships we curate become the semantic edges that make knowledge graphs queryable.
For ontologists and semantic engineers, this is an exciting opportunity. LLMs and AI systems need rich context, semantics and principled knowledge organization that makes data meaningful.
Entity resolution benefits from the semantic infrastructures we build, to transform matches into knowledge.
As new frameworks and tools emerge, there are exciting opportunities to participate in new innovations that support semantic interoperability, integrations between systems and semantic data transformations.
Operationalizing RDF and semantic web standards to negotiate data mapping logic, enable transformations, and support entity resolution tasks is a fantastic opportunity for ontologists and semantic engineers that will increase demands for our skillsets.
For ontologists seeking to demonstrate the practical value of their discipline, entity reconciliation provides a compelling application domain, and sz-semantics provides the tools to realize it.
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect

Connect with Jessica Talisman on LinkedIn 💬 | Or dive into her work on Substack:

From MD101 team 🧡
🌎 Global Modern Data Report 2026
The Modern Data Report 2026 is a first-principles examination of why AI adoption stalls inside otherwise data-rich enterprises. Grounded in direct signals from practitioners and leaders, it exposes the structural gaps between data availability and decision activation.
With hundreds of datapoints from 500+ data leaders and experts from across 64 countries, this report reframes AI readiness away from models and tooling, and toward the conditions required and/or desired for reliable action.

References
DerwenAI. (2024-2026). Strwythura: Construct an entity-resolved knowledge graph from structured data sources and unstructured content sources. GitHub. https://github.com/DerwenAI/strwythura
Senzing. (2025). sz-semantics: Transform JSON output from Senzing SDK for use with graph technologies, semantics, and downstream LLM integration. GitHub. https://github.com/senzing-garage/sz-semantics
Senzing. (2025). Senzing Entity Specification. https://senzing.com/docs/entity_specification/
Talisman, J. (2025). The Ontology Pipeline: A Semantic Knowledge Management Framework. Intentional Arrangement. https://jessicatalisman.substack.com/p/the-ontology-pipeline
Talisman, J. (2025). Knowledge Graph Lite, Part III: The Mighty Thesaurus, SKOS in Action. Intentional Arrangement.
Tesfaye, L., & Jonas, J. (2025). Expert Analysis: How Do I Get Started with a Semantic Layer? Enterprise Knowledge.
W3C. (2009). SKOS Simple Knowledge Organization System Reference. https://www.w3.org/TR/skos-reference/
ANSI/NISO Z39.19-2005 (R2010). Guidelines for the Construction, Format, and Management of Monolingual Controlled Vocabularies.
ISO 25964-1. Information and documentation — Thesauri and interoperability with other vocabularies.
 | A guest post by
|
Very interesting! I have a feeling every decade ontologies are getting rediscovered, then people realise it’s a lot of work and they get forgotten. Do you think it will be different this time now that ontology extraction approaches are getting more mature?
We are entering a world where words function as infrastructure. In that context, semantic fidelity becomes the key to preserving meaning as information scales. Ontologies and knowledge graphs provide the structure that allows AI to interpret reality rather than distort it. This is foundational work for the future of intelligent systems.