
The Retrieval Layer between Your Data and Your AI Outputs is a Product Decision
Your AI Is Reading the Wrong Things: Lessons from the Trenches of Enterprise AI Enablement.

About Our Contributing Expert
Ankita Chatrath | Vice President, Finance AI Hub

Ankita Chatrath is a Senior AI Product Manager and fintech product leader with over a decade of experience building data and AI-powered enterprise platforms for financial planning, accounting, revenue management, and regulatory operations.
Currently serving as Vice President in the Finance AI Hub at State Street, Ankita leads the development of responsible AI solutions that help enterprise finance teams automate complex workflows, improve decision-making, and scale operational efficiency. Her work spans AI product strategy, large language models (LLMs), retrieval-augmented generation (RAG), intelligent automation, data platforms, and finance transformation.
Throughout her career, she has built and scaled products used by thousands of operators globally, including AI-ready revenue data platforms, finance automation systems, and enterprise master data management initiatives. She is particularly passionate about translating complex institutional knowledge into practical AI applications that deliver measurable business outcomes while maintaining governance, accuracy, and trust.
Ankita holds an MBA in Data Analytics and Finance from Binghamton University School of Management and a Bachelor’s degree in Computer Science from Dharmsinh Desai University. Through her writing on Lessons from the Trenches and industry engagement, she explores the intersection of AI, data products, finance operations, and enterprise transformation. We’re thrilled to feature her insights on Modern Data 101.
We actively collaborate with data experts to bring the best resources to a 20,000+ strong community of data leaders and practitioners. If you have something to share, reach out!
🫴🏻 Share your ideas and work: community@moderndata101.com
*Note: Opinions expressed in contributions are not our own and are only curated by us for broader access and discussion. All submissions are vetted for quality & relevance. We keep it information-first and do not support any promotions, paid or otherwise!
Let’s Dive In
There is a specific kind of enterprise AI failure that does not announce itself.
You have done the upstream work. The semantic layer is documented. Definitions are governed. The knowledge graph connects entities to relationships in the way your business actually operates. The data pipeline feeds clean, structured information into a system that should, by every measure, produce useful answers.
The AI still gets things wrong.
No error fires or alert triggers. The output arrives fluent, confident, and cited to a real document. It is also incomplete in a way that matters, and nobody catches it until someone acts on it.
This is the retrieval problem. It sits between your data and your model, and it is the most consequential layer that most AI product managers do not treat as a product decision.
In this article, we will explore what retrieval means from a product standpoint, where it fits in the AI Workflow, how to design specs to manage retrieval, and how to validate the retrieval mechanism.
What the model reads
When a user sends a query, the model does not read your entire data estate. It reads a small window of context assembled from retrieved chunks of your documents and data. Retrieval-Augmented Generation, or RAG, is the architectural pattern that governs what lands in that window.
The implication is direct. Everything you invested upstream: the semantic layer that defines what terms mean inside your organization, the knowledge graph that connects customers to contracts to policies, the data pipeline that makes those definitions accessible, only reaches the model if retrieval surfaces it.
“Your output is bounded by what retrieval returns.”
This is why two systems with identical underlying data can produce dramatically different answers. The model is not the variable. The retrieval layer is.
What happens between the question and the answer
Most teams treat retrieval as a single lookup. It is three phases, each with its own decisions, and the model only appears at the very end.
Phase one: shape the query
Before the question touches any document, the system may rewrite or expand it, turning a short phrase like ‘SAR deadline’ into several equivalent forms to improve what the search will find.
The query then gets converted into a numerical representation that the document store can search against. Think of it as translating the question into a format that measures meaning, not just keywords. The embedding model making that translation is a product decision, and it determines how well questions map to the documents that answer them.
Phase two: find and filter
The translated query searches the document store, but not blindly. A filter runs first, narrowing the search to the right documents: active policy files, correct domain, current version. Without this gate, a query surfaces documents that happen to use the word ‘deadline.’
The filtered search returns the closest-matching document chunks. A re-ranker then sorts those candidates by how completely they answer the question, not just how similar they sound to it. This is the step that determines whether a rule and its exception travel together or get separated.
Phase three: assemble and answer
The top-ranked chunks get arranged into the window of text the model actually reads. The model generates an answer from that assembled context, and an output validation layer runs before the response reaches the user.

Product decisions live inside all three phases, not only in the model at the end. Most teams specify the model and hand off everything else. That is where the gaps form.
A team that did everything right
Consider a compliance team at a mid-market financial institution: a scenario from within my domain of expertise, Finance, but one that maps directly to regulated workflows in healthcare, legal, and insurance.
They have built an AI assistant to help analysts answer questions about internal AML policy and regulatory guidance. The semantic layer is solid: terms are defined, ownership is assigned, and vocabulary conflicts have been resolved. The underlying policy documents are accurate and current.
The assistant answers a routine query: What is our SAR filing deadline?
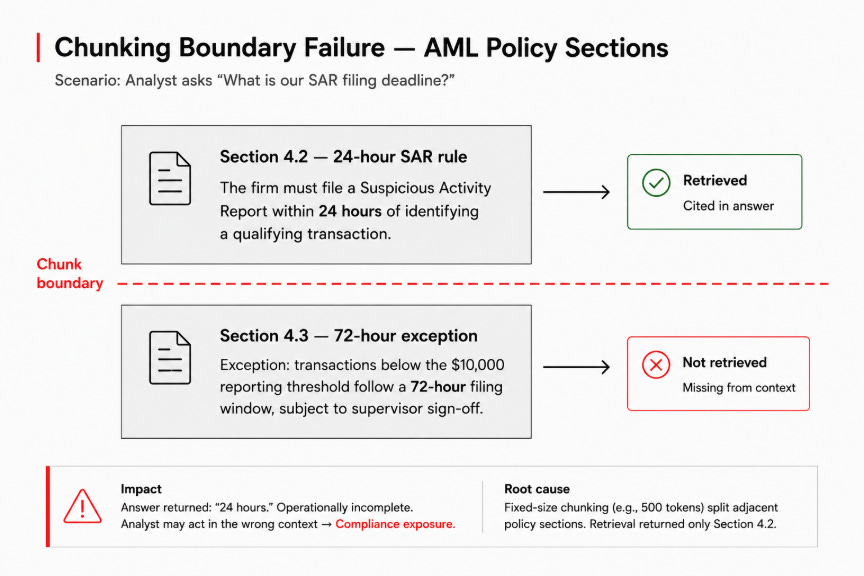
The firm’s AML policy has two adjacent sections.
Section 4.2: “The firm must file a Suspicious Activity Report within 24 hours of identifying a qualifying transaction.”
Section 4.3: “Exception: transactions below the $10,000 reporting threshold follow a 72-hour filing window, subject to supervisor sign-off.”
The assistant answers: 24 hours. It cites Section 4.2 of the policy document. The citation is real, given the document exists. The answer is operationally incomplete, and an analyst who acts on it in the wrong context carries a compliance exposure.
What happened has nothing to do with the model and nothing to do with the data.
The policy document was ingested using fixed-size chunking: a default that splits documents into consecutive 500-token segments regardless of content structure.
The chunk boundary fell between Section 4.2 and Section 4.3. Retrieval returned the highest-similarity chunk for the query. That chunk contained 4.2. Section 4.3 never surfaced.
Three decisions that determined what went wrong
Every retrieval pipeline reflects three product decisions, whether or not the team made them consciously. The compliance team above made all three by default.
Decision 1: Chunking strategy
Fixed-size chunking splits documents at token count boundaries with no awareness of content structure. A rule and its exception occupy adjacent sections of a policy document precisely because they belong together. Splitting them produces a retrieval surface where the rule exists, but the condition governing it does not.
A 2024 peer-reviewed study published in NAACL Findings: Is Semantic Chunking Worth the Computational Cost? by researchers at Vectara and the University of Wisconsin-Madison, evaluated 25 chunking configurations across document retrieval, evidence retrieval, and answer generation tasks.
The finding was more nuanced than the conventional wisdom: semantic chunking’s advantages were highly task-dependent and often insufficient to justify the added computational cost.
More significantly, chunking configuration influenced retrieval quality as much as or more than embedding model selection. Chunking is a deliberate design decision, not an infrastructure default.
For the compliance scenario, section-aware chunking: splitting at heading boundaries, preserving the section number in chunk metadata, with one paragraph of overlap between adjacent sections, keeps Section 4.2 and 4.3 together. The rule and its exception arrive in the same context window.
Decision 2: Query-document alignment
There is a deeper problem underneath the chunking decision, and it explains why retrieval can fail even when the right chunks exist in your document store.
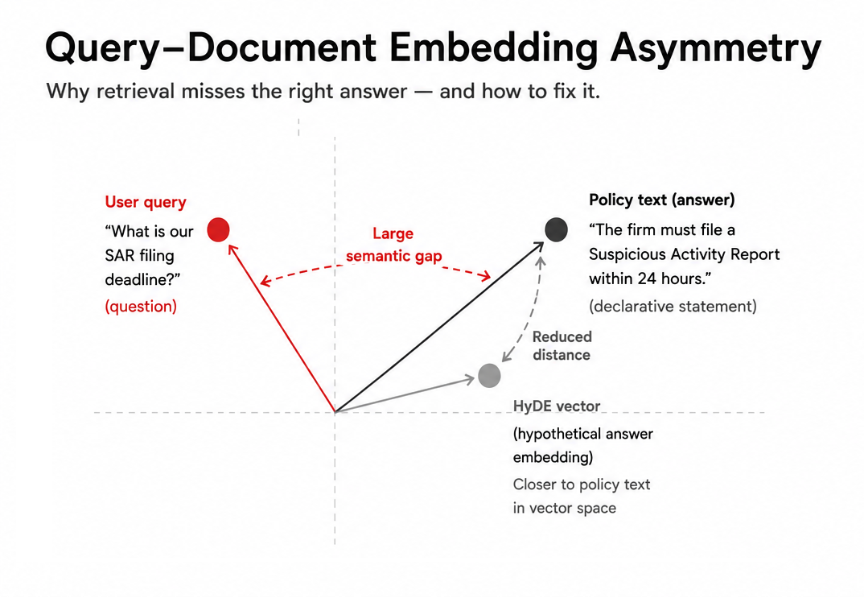
A user’s question and the text that answers it embed very differently in vector space. “What is our SAR filing deadline?” is a question. “The firm must file a Suspicious Activity Report within 24 hours” is a declarative policy statement.
A general-purpose embedding model converts both to vectors, but those vectors do not land close to each other in the high-dimensional space where similarity is measured.
The model was trained to recognize similarity between text that looks alike, not between questions and the declarative statements that answer them.
This is the query-document asymmetry problem, and it runs underneath every retrieval pipeline. A chunk that would answer the question perfectly sits in your document store, its vector pointing in a slightly different direction than the query vector. Retrieval ranks it lower than a less relevant chunk that happens to share surface vocabulary with the query.
Three approaches address this directly.
Asymmetric embedding models
Models trained specifically on question-document pairs rather than document-document pairs, so the query vector and answer vector land in compatible regions of the embedding space.Query expansion
Rewrites the query into multiple forms before embedding: converting “SAR deadline” into “suspicious activity report filing timeline,” “AML reporting requirement,” and “SAR submission window,” then searching with all three.HyDE: Hypothetical Document Embeddings
Generates a synthetic answer to the query first, embeds that synthetic answer instead of the original question, and uses the resulting vector to search. The synthetic answer looks like document text, so it embeds closer to document text.
For the compliance assistant, the right combination is an asymmetric embedding model fine-tuned on regulatory question-answer pairs, with query expansion enabled for the terminology variants that appear across different policy documents and regulatory guidance vintages. Without these, a well-chunked document with the right content still gets missed when the query language and document language diverge.
Decision 3: Re-ranking for completeness
Single-stage retrieval returns the most semantically similar chunk. It does not return the most complete answer. A two-stage pipeline retrieves a broader candidate set first, then re-ranks by relevance and completeness before passing context to the model.
A re-ranker recognizes that Section 4.2 and Section 4.3 reference the same underlying rule with a conditional relationship and scores them as a pair. Single-stage retrieval has no such logic.
For workflows where partial answers carry operational risk, like compliance, legal, and financial reporting, re-ranking is warranted. The computational cost is real. So is the cost of surfacing a rule without its exception.
Retrieval as a product spec
In the article on making enterprise data AI-ready, I introduced the context YAML as the artifact that captures structural and semantic facts about your data. The same discipline applies to retrieval.
The decisions above belong in a product spec, not in an engineering default. When retrieval quality degrades after a schema change, a document update, or an embedding model version bump, this spec is the baseline to check against.

This is not a handoff document. It is a record of the product decisions that determine what the model can and cannot answer. Without it, a retrieval degradation looks like a model problem and gets triaged as one.
When the answer exists in two documents
The AML scenario works the way it does because Section 4.2 and Section 4.3 live in the same policy document. Better chunking and re-ranking can surface them together. The structural problem changes when the rule and its exception are in different documents.
Consider a harder version of the same scenario. The 24-hour SAR filing requirement lives in the firm’s internal AML policy. The $10,000 threshold exception lives in OCC regulatory guidance published six months after the internal policy was last updated. An analyst asks: Does our internal SAR policy align with the current OCC guidance?
That question requires two things: retrieving the relevant section from the internal policy and retrieving the relevant section from the OCC document, then reasoning across both. Standard single-pass RAG makes one pass across the document store. It surfaces one answer or the other, not a comparison. The model never sees both simultaneously, and it cannot surface a conflict it was never given.
This is multi-hop retrieval, and it is where most compliance, legal, and financial reporting workflows eventually arrive. The questions that matter most are rarely answered by a single document. Policy alignment checks, regulatory gap analyses, and exception handling across jurisdictions all require reasoning across document boundaries.
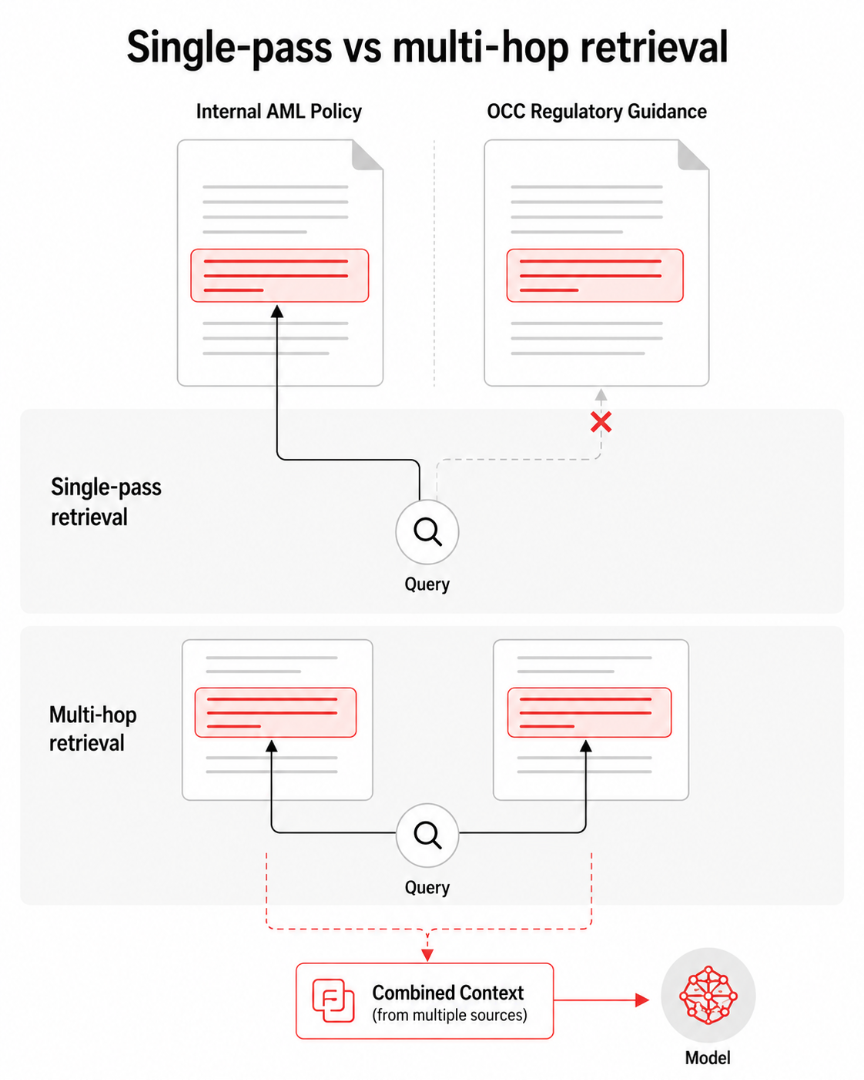
A multi-hop pipeline runs retrieval in stages. The first pass retrieves the most relevant chunks from the primary source: the internal AML policy. The model reads those chunks and generates an intermediate answer or a clarifying sub-query.
The second pass retrieves from a secondary source (the OCC guidance) using the intermediate output to sharpen the search. The pipeline then assembles results from both passes into a combined context window, and the model reasons across them to produce a comparison.
The product decisions here are different from single-document retrieval.
The pipeline needs a routing layer that classifies queries before retrieval begins: questions that involve comparison, regulatory alignment, or exception-finding across document boundaries route to the multi-hop branch.
It needs a source taxonomy that tells the pipeline which document stores to search in each pass. And it needs an intermediate context layer that carries the first-pass output into the second retrieval step without losing the thread of the original question.
For the compliance team, this means classifying alignment queries as multi-hop, routing them to a pipeline that searches internal policy in pass one and regulatory guidance in pass two, and assembling a combined context that surfaces both the internal rule and the external requirement together.
Without that architecture, the question “Do we comply with the OCC guidance?” gets answered from internal documents only. The model says yes. The answer may be wrong.
Why retrieval failures are the hardest kind
A broken API throws an error. A failed database query returns nothing. Bad retrieval returns something: fluent, formatted, cited, and in the right tone. Call this the completeness gap: the output looks complete, cites a real source, and is wrong in a way that only becomes visible when someone acts on it.
“These errors are potentially more dangerous than fabricating a case outright, because they are subtler and more difficult to spot.”
Stanford researchers studying two commercially available RAG-based legal research tools found that nearly one in five queries produced misleading or false information, even with retrieval grounding the model in real documents.
The researchers noted that citation-level errors are harder to catch than outright fabrications: verifying them requires a user to locate the cited source, read and understand it, and compare its content against the proposition the model used it to support. Most enterprise users do not do this for routine queries.
In the hallucinated responses the Stanford team analyzed, 47% had naive retrieval as a contributing cause, meaning the retrieval layer, not the model, produced the conditions for the wrong answer. The model reasoned correctly from the context it was given. The context was incomplete.
This is why retrieval quality needs its own monitoring layer, separate from model quality metrics. Tracking task success rate tells you whether outputs are good. It does not tell you whether retrieval is the reason they are not.
That requires different instrumentation: retrieval precision by document type, chunk hit rate for multi-section queries, retrieval failure rate after document or schema updates. Production monitoring that only watches model outputs has no visibility into the layer where most failures originate.
The layer the data work assumed
The semantic layer article earlier in this series covers how to make meaning explicit in enterprise data: the definitions, ownership, and vocabulary conflicts that determine whether an AI system reasons correctly about your organization’s concepts. The knowledge graphs piece covers how to connect those definitions to the real-world entities and relationships they describe.
Both assume the model can access what you have built. Retrieval is the mechanism that makes that assumption true or false at query time. A well-structured knowledge graph with a broken retrieval pipeline produces the same incomplete answers as no knowledge graph at all, because the model never sees the relevant nodes.
The data layer work creates the conditions for good answers. Retrieval determines whether those conditions are met. Both deserve product-level decisions, written down, with failure modes documented.
Where in your stack has retrieval been the failure point you didn’t see coming?
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 💬

Got questions or want to share your own experiments? Find Ankita on LinkedIn or drop a comment below. 💬
More from Ankita
From MD101 team 🧡
🌎 State of Data Products, Q1 2026
Don’t place your 2026 data bets in the dark. Discover how the best minds are leaning toward architectural resilience and trust: Read the Q1 Edition of the State of Data Products, The Catalyst.

Research sources
Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools — Stanford Law / Stanford HAI, 2024
Is Semantic Chunking Worth the Computational Cost? — Qu, Tu, Bao. NAACL Findings 2025, pp. 2155-2177
 | A guest post by
|