
The Modern Data Stack’s Final Act: Consolidation Masquerading as Unification
Why "tool" vendors are increasingly acquiring in adjacent spaces, the illusion of "unification", and how to identify true architectural unification.


Overview
The Illusion of Unification
Evidence of Illusion: Consolidations by Layer of the Data Stack
Analysis of the Evidence of Consolidation
How Users Avoid the Trap of False Unification
Understand Who is Truly Delivering Unified Platforms
Implications for Enterprises / Data Leaders
The Illusion of Unification
The Modern Data Stack is ending, but not because technology failed. It’s ending because vendors realised they can sell the illusion of unification while locking you in.
The ecosystem that birthed the Modern Data Stack has matured and vendors have begun to see the endgame. The promise of modularity, flexibility, and best-of-breed choices is giving way to a new narrative: unification, at any cost. The latest whispers of a $5–10 billion Fivetran-dbt merger make this reality undeniable.
Suddenly, the companies that once encouraged choice and composability are presenting themselves as the architects of a seamless, end-to-end stack.
But this “seamlessness” is not unification in the architectural sense; it is unification in the narrative. Users are drawn into the story: one contract, one workflow, one vendor to call. But the vendor is locking you in before the market fully stabilises.
Looks like simplification, but is actually enclosure. The illusion of a single platform conceals multiple stitched-together layers, each still bound by its own limitations, yet now difficult to escape. This is not just a vendor play, it is a structural shift, a reordering of the data ecosystem that forces practitioners to question what “unified” really means.
What a Modern Data Stack Was Supposed to Do
At its core, the Modern Data Stack (MDS) was an exercise in composability. Stripped of branding and hype, the MDS was a collection of layers, each solving a segment of the problem (in silos!): ingestion to bring in data, transformation to shape it, a semantic layer to define meaning, storage to persist it reliably, analytics to surface insight, activation to make it operational, and observability to maintain trust.
Each layer was meant to be modular, swappable, and independent: the user could pick the best tool for each need, confident it would integrate cleanly with the rest.
What made the stack compelling was not the individual tools themselves, but the freedom it afforded practitioners. Data teams could innovate in one layer without being constrained by another; engineers could optimise pipelines without dictating business logic; analytics teams could define metrics without touching the underlying storage. The Modern Data Stack pedalled the hope of agility, of choice, of the ability to orchestrate complexity without succumbing to it. It was the embodiment of first-principles thinking applied to organisational data: deconstruct the problem into its fundamental layers, solve each independently, and trust the interfaces to hold it together.
What’s Happening Now: The Consolidation Wave
The Modern Data Stack, once celebrated for its modularity, is undergoing a profound shift. Over the past year alone, a cascade of acquisitions has redrawn the landscape: Databricks absorbing Tabular and Neon, Fivetran expanding with Census and SQLMesh, dbt Labs integrating SDF, Coalesce bringing CastorDocs into its fold, Datadog acquiring Metaplane, Redis taking Decodable, Hex absorbing Hashboard, Qlik integrating Upsolver, and Arroyo joining Cloudflare.
Each move, on the surface, appears to fill gaps, smooth workflows, or enhance capabilities.
But viewed through first principles, a pattern emerges. These acquisitions are less about functional synergy and more about control: control of the “real estate” of the stack, control of the narrative, and ultimately, control of the user.
Vendors are building defensive moats (fences around their ecosystems) to prevent commoditisation and preempt irrelevance in a market that increasingly favours unified workflows. What is being sold as unification is often only a stitched-together façade, a narrative unification rather than architectural. True unification, where layers share metadata, governance, and semantics seamlessly, is rare. Most of the market is converging not to simplify, but to enclose.
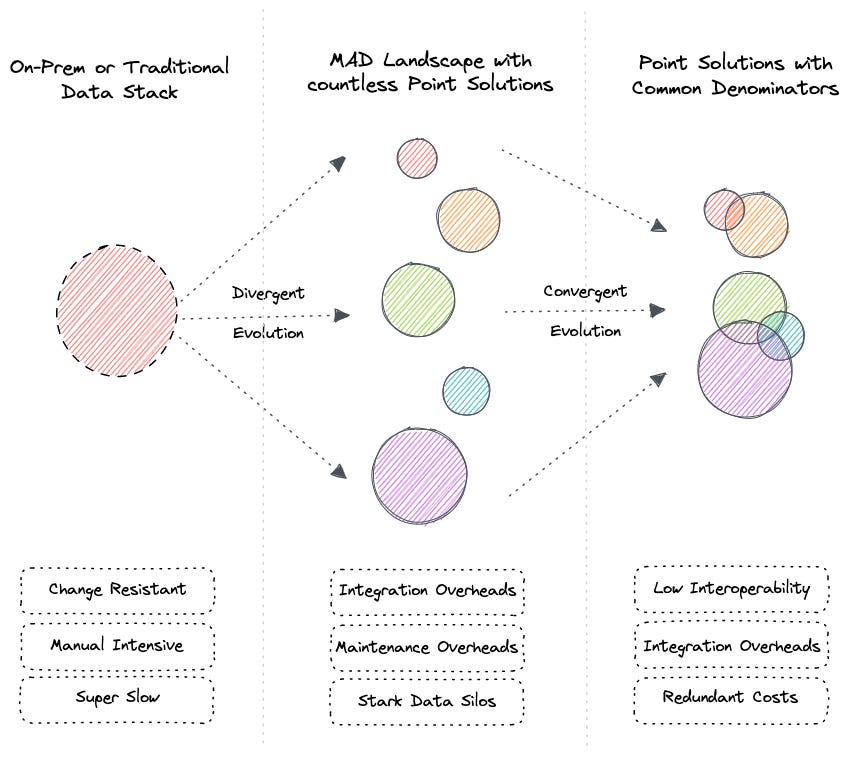
Learn more about this dilemma here ⬇️
Progressive overlap in assembled systems
The Defensive Moat: Vendors Locking You In
These mergers are rarely about creating a perfectly seamless workflow. At their core, they are survival plays. Both companies face a world where warehouses and cloud-native platforms are expanding upward and downward, swallowing ingestion, transformation, semantics, and activation. Alone, each risks commoditisation: Risk of being just another pipeline, or just another modelling layer. Together, they create a defensive perimeter, a moat designed to enclose users before the hyperscalers do.
For users, of course, it’s tempting: a single workflow, one contract, fewer tools to manage. But this perceived simplification is a carefully constructed illusion for the enterprise. Portability, flexibility, and independence (the very principles that made the Modern Data Stack compelling) start to deteriorate in such convergence. Switching costs escalate, experimentation slows, and decision-making subtly shifts to align with the constraints of the combined vendor. The “unified stack” is not unification in the architectural sense; it is a lock-in ecosystem masquerading as freedom, a moat whose walls are invisible until you try to leave.
Evidence for the Above Meta: Consolidations by Layer of the Data Stack
1. The Latest: Ingestion + Transformation
The talked about Fivetran + dbt Labs merger, if it happens, marks a seismic consolidation in the Modern Data Stack, combining two of its most recognisable brands into one platform. Fivetran, once focused on data movement (ELT and reverse ETL), has expanded into activation with Census and transformation with SQLMesh, while dbt Labs has long led transformation and analytics engineering, recently acquiring SDF to strengthen its semantic layer.
Together, they collapse the pipeline: from source extraction through transformation, semantics, and activation, erasing the “thin dbt in the middle” and ending the best-of-breed narrative in favour of one vendor, one workflow. The acquirers’ aims are clear: control of the full pipeline with no external dependencies, narrative dominance in a fragmented stack, and a defensive moat against commoditisation pressures from Rivery, Meltano, Airbyte, SQLMesh, Coalesce, and even Snowflake or Databricks’ built-in transformations. By merging, they shield each other and remain the last independent giant capable of resisting hyperscalers like Snowflake, Databricks, or Google.
For users, the promise of simplification hides deeper risks. A single contract and integrated workflow come at the cost of lock-in: Fivetran pricing on ingestion, dbt semantics and modelling, and shrinking portability as dbt shifts from a neutral open-source layer into a commercial control plane. This merger accelerates the collapse of modular architectures into full-stack vs full-stack, threatening semantic, catalog, and orchestration vendors like Coalesce, Atlan, Transform, Castor, and Metaphor with extinction or forced exits while warehouses retaliate with acquisitions of their own.
The broader trend is one of defensive enclosure disguised as unification, raising switching costs, eroding choice, and concentrating power in vendor-controlled ecosystems. Fivetran’s climb up the stack, from pipes in, to activation, to transformation, is less about meeting user need than about survival, as pure-play ELT commoditises and vendors race to build “mini-monopolies” before hyperscalers and AI-native platforms swallow the stack whole.
2. Storage + Table Formats
Databricks’ acquisitions of Tabular and Neon hint at a deliberate move to consolidate foundations of data storage and table formats. With Tabular, Databricks gains influence over open table formats like Iceberg, positioning itself well in the soft battle over standardisation versus vendor control: a governance play that seems like as technical choice.
Neon, a cloud-native Postgres, brings transactional workloads directly into the Databricks ecosystem, eroding the historical boundaries between OLTP and OLAP and signalling that lakehouse vendors are no longer content with analytical workloads alone. Snowflake is playing the same game with its acquisition of Crunchy Data, embedding enterprise-grade Postgres natively and setting up a direct competition with Databricks–Neon. Postgres, long treated as peripheral in cloud architectures, is now being elevated to a first-class citizen across the major cloud data platforms.
Taken together, these moves consolidate storage, table formats, and transactional-analytical boundaries under vendor control. The underlying intent is clear: vendors are racing to own the layer where data naturally gravitates, collapsing Postgres, OLAP warehouses, and open table formats into a single, tightly governed platform. The “freedom to choose” that once characterised the Modern Data Stack is quietly giving way to a controlled substrate that vendors can both standardise and monetise.
3. Orchestration + Semantics
Orchestration and semantic layers are undergoing similar consolidation. Coalesce.io’s acquisition of CastorDocs brings data modelling, cataloguing, lineage, and governance together. This creates a platform that aspires to be a one-stop hub for semantic management. On the other hand, dbt’s own launch of a semantic layer, though not an acquisition, represents a strategic consolidation within the ecosystem.
Together, these moves highlight the intensifying competition among vendors to control not just transformation, but also governance and metadata. The emerging reality is that transformation, governance, and semantic layers are merging into unified orchestration and modelling hubs, simplifying user workflows at the cost of deeper vendor lock-in.
4. Observability + Monitoring
Observability and monitoring are consolidating under a similar logic. Datadog’s acquisition of Metaplane merges application monitoring and data observability -> implies convergence of infrastructure and data monitoring into a single platform. Soda’s acquisition of nannyML bridges classical data quality monitoring with model drift detection, integrating traditional observability with AI and ML workflows. The net effect is that data observability is being absorbed into larger monitoring ecosystems, reducing fragmentation but also concentrating control over how data reliability and model trust are measured and enforced.
5. Real-time Streaming & Processing
Real-time data platforms are also consolidating. Arroyo joining Cloudflare sets up stream processing within an infra giant, moving toward edge-native data workflows. Redis acquiring Decodable merges in-memory databases with real-time streaming pipelines, collapsing OLTP, streaming, and caching layers into a single low-latency platform. Confluent’s expansion beyond Kafka with Flink follows the same pattern: integrating messaging with stream processing. Vendors are trying to converge real-time OLTP, streaming, and in-memory processing, in the hopes of creating unified platforms designed for speed and immediacy.
6. Analytics + Collaboration
Analytics and collaboration tools are merging into unified experiences. Hex’s acquisition of Hashboard consolidates notebook-based exploration with dashboarding, creating a single workflow from data exploration to visualisation to team collaboration. Qlik acquiring Upsolver brings BI platforms deeper into data engineering, integrating streaming ingestion and transformation into the analytics layer. The emerging pattern is clear: BI and analytics tooling is converging with upstream data preparation and collaborative workflows, simplifying user interfaces while concentrating control over analytics UX.
7. AI + Developer Tools
AI platforms are starting to consolidate developer workflows as well. OpenAI’s acquisition of Codeium exemplifies a push to own the space where developers interact with AI-enhanced coding tools. The consolidation here is softly strategic: developer workflows are being absorbed into AI-native IDEs, setting up AI platforms as the environment where innovation happens.
Analysis of the Evidence of Consolidation
Projections of Future Consolidations
Semantic Layer Wars Intensify
dbt, Coalesce, Atlan, and warehouse-native layers (Snowflake Native Apps, Databricks Unity Catalog) will converge. Expect acquisitions of data catalogs / lineage players (like Atlan, DataHub, Amundsen-like tools) by warehouses or dbt.
LLM/AI + Data Stack Merge
Expect Snowflake, Databricks, or Fivetran to buy an AI data agent company (like Gretel, LangChain infra players, or even a lightweight RAG orchestration startup). ML monitoring + Data observability fully merge.
Streaming + OLTP Collapse
Redis, Confluent, SingleStore, Materialize, TimescaleDB → heading toward consolidation. Likely buyers: Cloudflare, AWS, GCP, Azure.
End-to-End Workflow Tools
Expect BI vendors (Looker, ThoughtSpot, Mode, even PowerBI) to acquire data activation / reverse ETL / catalog tools to stay relevant.
Open Table Format Alignment
Iceberg, Delta, Hudi won’t all survive. Expect one format to dominate (likely Iceberg with Tabular, Snowflake, AWS backing). Vendors may consolidate around a single standard.
Why These Acquisitions Are Happening
Vendors aren’t just “filling gaps.” The underlying game is about controlling gravity in the data stack. This is not genuine unification; it’s enclosure. Layers are stitched together just enough to tell the story of a unified stack, but interoperability across ecosystems is missing.
Users see fewer tools, fewer contracts, and a seemingly simpler stack. Underneath, choice has been ceded, and the cost of leaving is exponentially higher.
Why Now?
From 2020–2023, the data stack exploded into dozens of tools. Buyer fatigue is real. Vendors smell consolidation as the winning narrative. AI accelerates the urgency: semantic layers, observability, and governance all need to feed models. Platforms must look unified to capture AI workflows, even if true architectural unification remains elusive.
Databricks & Snowflake (Storage + Formats + Postgres)
Databricks and Snowflake know that open formats like Iceberg, Delta, and Hudi are the future. By acquiring Tabular (Iceberg governance) and Crunchy Data (enterprise Postgres), they are suggesting: “Don’t worry about open, we’ll give you a managed, enterprise-safe version inside our walls.” For users, it feels like betting on openness, but in reality, it’s open through a vendor-shaped lens. Convenience comes with entanglement: Iceberg managed by Databricks isn’t truly open anymore. These acquisitions aren’t product synergies, they are defensive plays. Both Snowflake and Databricks fear irrelevance if Postgres and Iceberg ecosystems flourish independently, so they are pulling them inside.
Fivetran & dbt (+ Census + SQLMesh)
Fivetran has always been “pipes in.” But as pure-play ELT commoditised, it climbed the stack: acquiring Census (pipes out) and SQLMesh (transformation) to claim the full activation loop. Enter dbt Labs: the neutral modelling layer that became the de facto standard for analytics engineering. Together, the merger erases the “thin dbt in the middle” and reframes the workflow as ingestion, modelling, semantics, and activation all under one roof. For customers, it looks like simplification. In reality, it’s enclosure: Fivetran’s billing, dbt’s semantics, and proprietary connectors intertwine to create lock-in. This isn’t just about user need, it’s survival: both vendors shielding themselves from commoditisation below and hyperscaler encroachment above.
dbt Labs (SDF) & Coalesce (CastorDocs)
dbt is aiming to become the control plane for analytics engineering, not just a thin modelling tool. Acquiring SDF (semantics, metrics) and expanding orchestration is a strategic land grab. Coalesce buying CastorDocs mirrors this logic, folding governance and lineage into transformation. For users, this feels like a single pane of glass: model, orchestrate, govern. But interoperability is missing, each vendor enforces its own semantic layer, splitting the market further before anyone achieves true unification. The power struggle is over semantics: whoever controls it controls the “truth” in the enterprise.
Observability (Datadog → Metaplane, Soda → nannyML)
Datadog blurs the line between application monitoring and data monitoring, preventing a “New Relic for data” from thriving independently. For users already in the Datadog ecosystem, workflows feel smoother, but teams are now tethered to a specific lens of observability. Soda acquiring nannyML extends this to data quality and model drift, bridging classical monitoring with ML observability. Observability as a standalone category is shrinking, being absorbed by larger monitoring and infra vendors.
Real-Time & Edge (Cloudflare → Arroyo, Redis → Decodable, Confluent → Flink)
Latency is the next battleground. Cloudflare incorporating Arroyo brings stream processing to the edge; Redis acquiring Decodable merges OLTP, streaming, and in-memory processing; Confluent’s Flink expansion integrates both messaging with stream processing. For users, the stack appears simpler, but complexity is hidden beneath vendor abstractions. True unification here is weakest: real-time, OLTP, and streaming cannot be cleanly merged yet. A strong narrative to lock in users before the tech matures.
Analytics UX (Hex → Hashboard, Qlik → Upsolver)
Notebook exploration, dashboards, ingestion, and transformation are collapsing into single collaborative surfaces. BI alone is losing relevance, so vendors buy upstream layers. Analysts experience fewer tool switches, but portability vanishes. This is the “Slack-ification” of analytics: the UI vendor aims to become the default operating system for data consumption.
AI + Developer Tools (OpenAI → Codeium)
OpenAI acquiring Codeium illustrates a strategic consolidation: owning the IDE means owning the developer. Users gain supercharged productivity, but at the cost of total reliance on OpenAI’s ecosystem. The IDE itself becomes a moat, enclosing workflows rather than integrating them universally.
How can we, as Users, avoid the Trap of False Unification
As users, we are caught in a push and pull system, which is also the reason the system keeps breathing somehow. Vendors are racing to acquire, consolidate, and stitch together the Modern Data Stack. From Fivetran absorbing dbt-adjacent tools to Databricks folding in transactional engines, the message is clear: “Trust us to unify everything.”
But underneath this narrative is a catch: one that encourages iterative investment in systems that promise cohesion but deliver only enclosure and lock-in. Every acquisition, every “integration,” is designed to expand the vendor’s control over the stack before the market stabilises, leaving users shuttling between platforms, rebuilding pipelines, or re-educating teams. While the underlying architecture remains stitched rather than unified.
The question for practitioners and data leaders is simple: do we want to play the vendors’ game, investing repeatedly in incremental layers of false unity, or do we recognise where true unification lives? Avoiding the trap requires discipline:
identify platforms WHERE INTEGRATION IS ARCHITECTURAL, not narrative;
insist on a shared metadata and governance layer that spans all workflows;
and resist the allure of “one-click” unification that is, in reality, a series of acquisitions disguised as a platform.
The objective is not to reject innovation or consolidation outright, but to anchor investments in systems that advance genuine architectural unification, so that every addition to the stack compounds value rather than creating new points of friction.
The Risks of False Unification
What we’re seeing in the market is not unification, but its simulation. Vendors are stitching layers together just enough to market the story of simplification, while structurally increasing dependence on their ecosystem. The pattern repeats across the stack:
Bolt-on acquisitions dressed up as platforms. A connector here, a catalog there, suddenly branded as “one unified workflow.” But under the hood, these are still disparate tools, only now enclosed inside a single vendor contract.
Lock-in disguised as end-to-end simplicity. Fewer tools to buy, yes. But at the cost of choice, portability, and negotiating leverage. Your entire data workflow becomes entangled with one vendor’s roadmap and pricing power.
The illusion of manageable switching costs. Vendors downplay exit barriers, but once ingestion, transformation, semantics, and activation are all encoded in one ecosystem, leaving is practically impossible without rebuilding from scratch.
Each move is positioned as simplification; each, in practice, deepens enclosure.
The risk goes beyond vendor lock-in, something that most enterprises are already used to. The furthered risk is the misallocation of user investment, spending years and millions migrating into a platform that sells unification but delivers fragmentation with higher switching costs.
What users actually need is not illusory integration but architectural unification: open standards, interoperable semantics, and composable contracts between layers. Until then, every wave of consolidation is just another enclosure disguised as progress.
Understand Who is Truly Delivering Unified Platforms
If we strip away vendor narratives and return to first principles, genuine unification has a clear definition. It isn’t “more features under one logo.” It is:
A single substrate for metadata, security, and semantics that flows seamlessly across ingestion, storage, transformation, analytics, activation, and AI.
Architectural integration, not bolt-on bundling. The layers don’t just sit side by side; they share the same governance model, lineage, and operational backbone.
Portability over enclosure. True unification lowers switching costs by aligning with open standards, not raising them by manufacturing proprietary lock-in.
By that definition, only a handful of platforms can be called genuinely unified today:
1. Palantir Foundry
Palantir Foundry is often dismissed as too closed or proprietary, but it remains one of the rare platforms where integration is genuinely native. Data integration, modelling, governance, and application-building don’t exist as separate add-ons: they are part of the fabric. Its strength lies in vertical integration: the same governance, semantics, and security posture extend seamlessly across analytics, applications, and AI. In practice, this makes Foundry one of the few platforms where “single pane of glass” isn’t just a sales phrase but a lived user experience.
2. Data Operating System: DataOS
DataOS is built on the principle of a true data operating system. Instead of treating ingestion, transformation, governance, observability, semantics, and activation as disconnected modules stitched together by APIs, it runs them all as services on a common substrate. The critical difference is that everything flows through the same metadata and policy layer. This creates not just functional coverage but actual architectural unity: every action, every query, every permission governed by the same backbone. That’s why it feels truly unified, not just “integrated.”
4. Google’s BigLake + Vertex AI (Cloud-Native Unification)
Google is quietly assembling a genuinely unified fabric across OLAP (BigQuery), OLTP-like storage (Spanner, AlloyDB), unstructured data (BigLake), and machine learning (Vertex AI). What makes this credible is that unification isn’t happening at the UI or product marketing layer: it’s enforced deep in the substrate: IAM, metadata, and query engines. For organisations deeply invested in GCP, the experience is structurally closer to true unification than the patchwork efforts coming from Snowflake or Databricks. It’s cloud-bound, yes, but within that boundary, it represents a more authentic step toward fabric-level unification.
Implications for Enterprises / Data Leaders
Be wary about “unification” offerings, even though that’s what you want to adopt. Double question if the “unification” is truly architectural or just a narrative with a collection of tools and acquisitions. Most vendor pitches today conflate bundling with true architectural simplification. Strategic evaluation requires separating the narrative of unification from substrate-level integration.
Understand if metadata, security, and semantics are actually shared across the stack and can truly interoperate, or if it’s only orchestrated at the edges. Most importantly, you need to assess whether the “unified” experience expands or disrupts your long-term flexibility. The critical question isn’t “how simple does this look today?” but “how portable will this be five years from now?”
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect

Find me on LinkedIn 🙌🏻

Find me on LinkedIn 🤝🏻
From MD101 team 🧡
The Modern Data Masterclass: Learn from 5 Masters in Data Products, Agentic Ecosystems, and Data Adoption!
With our latest 10,000 subscribers milestone, we opened up The Modern Data Masterclass for all to tune in and find countless insights from top data experts in the field. We are extremely appreciative of the time and effort they’ve dedicatedly shared with us to make this happen for the data community.
