
The Current Data Stack is Too Complex: 70% Data Leaders & Practitioners Agree
The Utility Plane, Modular Architecture, and Non-Disruptive Approach to Improve the Experience of Data Users



This one’s a detailed dive, so here’s a quick overview of the piece at a glance:

TLDR
CEOs now recognize that AI's transformative potential hinges directly on having a well-executed data strategy. Without a comprehensive data strategy that has executive support, their ambitions to "do something" with GenAI/General AI will struggle and have a high probability of failing (Forbes cites why 85% of AI Projects fail ↗️). They need to apply their influence, through budgets and top-down support, towards elevating the way their companies manage their data to meet AI needs.
It may seem intuitive to simply make the existing tools and solutions work better, but this survey highlights a problem with that thinking. Many respondents shared the struggles they're facing with too many tools, resulting in overly complex solutions. It fundamentally limits which AI use cases can be pursued. The old solutions aren't suitable for ever-increasing data volumes and this fast-growing, high-expectations data consumption category of AI.
Forward-thinking organizations are restructuring teams around business domains rather than technology specializations. Tool proliferation leads to the specialization needed to integrate them together, which leads to knowledge fragmentation, which results in slower and more complex decision-making. It’s self-reinforcing and becomes more entrenched when not addressed head-on. Companies focused on cultivating T-shaped professionals (aka Generalists) with deep expertise in core platforms combined with broader knowledge develop institutional problem-solving capabilities that specialized teams cannot match. Tackling tool overload is a key action towards that objective.
Introduction
Recently, in 2024, The Modern Data Company conducted a survey in collaboration with the MD101 community. The responses came from 230+ voices from across 48 countries with an average of 15+ years of experience in the data space.
One particular finding that validated our concerns was the overflow of tools across a majority of the data stacks used by the respondents and the associated cognitive overload and cost implications of the same.
Over 70% of respondents are driven to use more than 5-7 different tools or work with 3-5 vendors for different tasks, such as data quality and dashboarding. About 10% use more than 10 tools, showing the increasing complexity of the Data Landscape.
How Did We Get Here: To The Point of Overflowing Tools In the Data Management & Analytics Stack?
It’s getting progressively challenging for non-expert end users as data ecosystems progressively develop into complex and siloed systems with a continuous stream of point solutions added to the mix. Complex infrastructures requiring consistent maintenance deflect most of the engineering talent from high-value operations, such as developing data applications that directly impact the business and ultimately enhance the ROI of data teams. ~ datadeveloperplatform.org
The Modern Data Stack (MDS) brought around a lot of positive momentum, one noticeable impact being the shift to cloud ecosystems, which reduced barriers to entry and made data not just more accessible but also recoverable.
But with MDS, vendors and providers were overcome with solving small bytes of the big-picture problem, which was indeed the need of the hour. This tooling proliferation, especially from vendors, was catalyzed by some (among many) of these factors:
Specialization over generalization: Specialized tools solved niche data challenges and created silos.
Lower barriers to entry: Cloud and SaaS reduced costs and accelerated tool adoption.
Different vendor-champion partnerships across domains: Changing leadership with differing tool preferences and independent team decisions led to an uncoordinated tool stack.
Lack of an end-to-end organizational data strategy: Immediate fixes took priority. Tools were adopted to solve immediate problems without considering long-term scalability or integration.
The Outcome of Integrating Data Tools
While the intention of siloed tools was to become a modular network of solutions that users could interoperate to solve larger problems, the Modern Data Stack soon became a double-edged sword. It led to a maze of integration pipelines, only a few star engineers who spent years in the organization understand - implying both a technical as well as cultural centralization of key data assets and solutions.
Huge Time Drain 🔺
High Hidden Costs🔺
ROI of Data Teams🔻
Data Team Becomes an Ops-Function🔺
Credibility🔻
Overwhelm🔺
Tool Inflation🔺
Inflated Wants🔺
Huge Time Drain 🔺: Integrating & Maintaining Integrations of 5+ Tools
Users spend 1/3rd of their time jumping between tools.
About 40% of the respondents spend more than 30% of their time jumping from one tool to another, ensuring they work well together.
Consider the amount of time teams spend just to stay afloat in a fragmented tooling landscape. Each new tool requires onboarding, training, and adaptation to its unique design and workflows. Users must learn not only how to operate the tool but also how it fits—or often doesn’t fit—into their existing processes.
Switching between tools adds another layer of inefficiency, with users frequently losing context as they jump from one interface to another. This constant toggling not only slows down work but also increases the likelihood of errors.
Integration challenges further compound the problem. Teams spend hours troubleshooting integration bugs and patching up connections between tools that were never designed to work seamlessly together. Even after solving these issues, ongoing maintenance becomes a necessary burden to ensure integrations remain functional for day-to-day operations.
Also, validating the accuracy and consistency of outcomes equals a laborious task. Teams are forced to perform detailed lineage tracking, manually following the trail of data across multiple systems to confirm its validity. This process is not only time-intensive but also prone to oversight, creating a recurring cycle of frustration and inefficiency. The result? Valuable time and resources are drained on overhead tasks rather than focusing on the insights and actions that drive value.
High Hidden Costs🔺: Overheads of Integrations
Licensing, training, and support for multiple tools significantly increased costs.
Operational Costs
Cost of dedicated platform teams to keep the infrastructure up and running
Cost of continuous maintenance of integrations and consequently flooding pipelines
Cost of de-complexing dependencies during frequent project handoffs
Infrastructure & Migration Costs
Cost of migrating huge data assets
Cost of setting up data design infrastructures to operationalize the point solutions
Cost of storing, moving, and computation for 100% of the data in data swamps
Licensing & Tooling Costs
Cost of individual licenses for point solutions required to operationalize the cloud
Cost of common or redundant denominators across point solutions (overlaps)
Integration & Ecosystem Costs
Cost of continuous integration whenever a new tool joins the ecosystem
Cost of isolated governance for every point of exposure or integration point
Cognitive & Risk Costs
Cost of cognitive load and niche expertise to understand varying philosophies of every tool
Cost of frequent data risks due to multiple points of exposure
As you can guess, the list is quite far from exhaustive. (Source)
ROI🔻: The Proliferation of Tools with Less Return on Investments
Decisions take time to take effect. Each tool meant patience and investment of not just resources but, more importantly, time. Decisions take time to take effect. Each tool meant resource investments, patience, and, most importantly, time.
But given the fundamental design flaw of “adding one more tool”, what follows is overheads around maintenance, integration, licensing, and opportunity costs specifically due to the investment of time.
Ultimately, the end objective of getting closer to business value is pushed further away when maintenance and integration precede core data development. More data integration tools are added to the equation to solve the gaps, and the cycle continues.
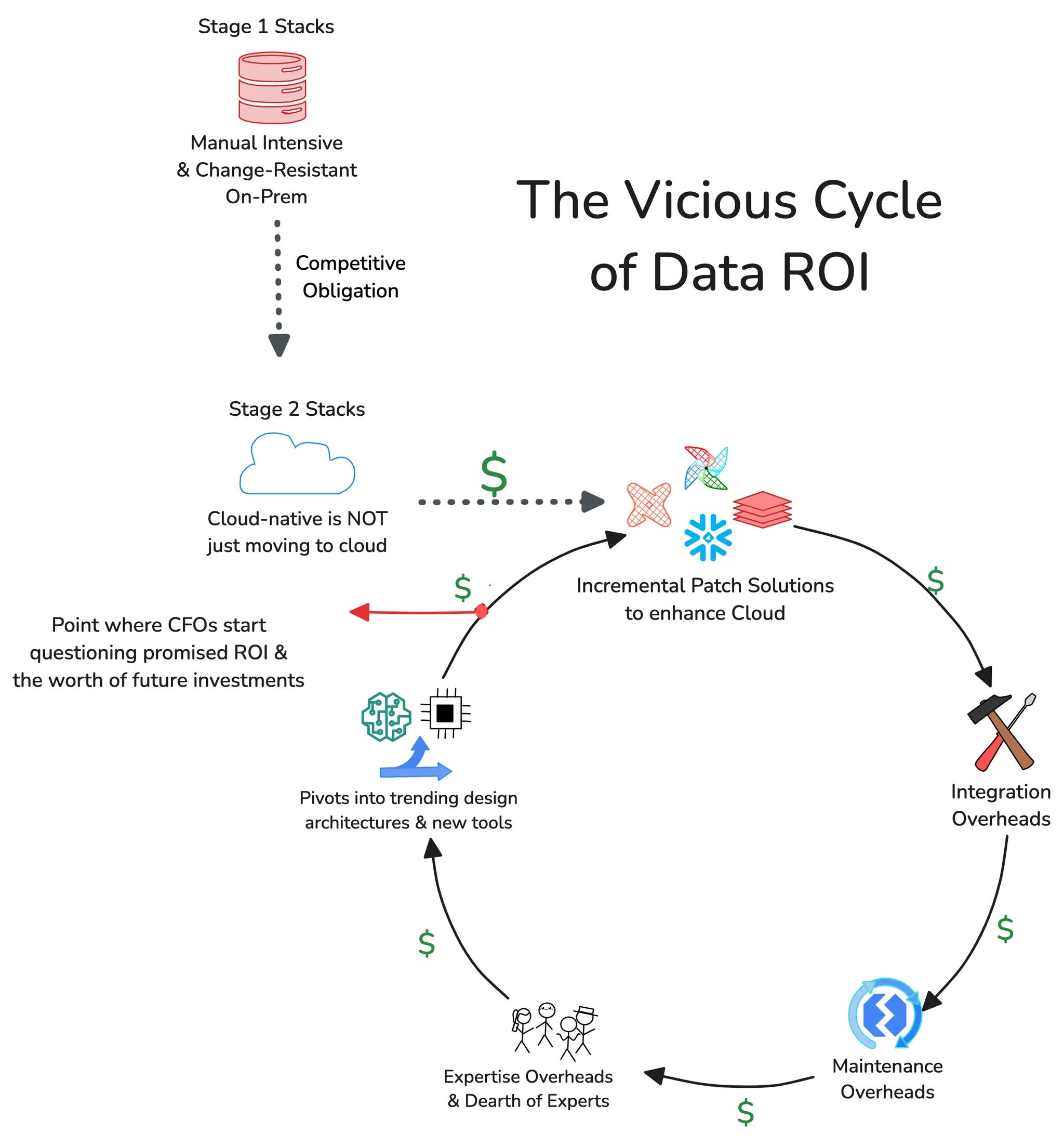
And picture this—with every iteration of new niche tooling, in addition to licensing costs for every tool, there are also additional hidden (huge) costs of premium in-app feature purchases. But much more problematic is the added maintenance cost that each tool incurs.
The cost of owning the tool significantly increases when, on top of licensing and service, an additional 15-18% is maintenance cost. If you’re spending $2M on a contract and then spending $300K in additional maintenance costs, the negative impact on ROI is huge.
About 40% say maintaining integrations between various data tools leads to the highest costs. ~Modern Data Survey (A collaborative initiative between Modern Data 101 & The Modern Data Company)
Data Team Becomes an Ops-Function🔺: Maintenance Primary, Value-from-Data Secondary.
With abundant tooling, as demonstrated by the MAD Landscape or MDS, it is becoming increasingly difficult for organizations to focus on solution development that actually brings in business results due to consistent attention drawn by maintenance tickets. Data and analytics engineers are stuck in a maintenance-first, integration-second, and data-last culture. This involves countless hours spent on solving infrastructure drawbacks and maintaining debt-ridden data pipelines. And the infrastructure required to host and integrate multiple tooling is no less painful.

Credibility🔻: Exponential Increase in Volume of Data Makes Trust & Usability Challenging
I think a lot of data teams run into the problem of, you know, creating metrics within their BI tool, creating metrics within something like HubSpot, or maybe another growth or marketing tool like Google Analytics. And then, you have three different answers for the same question.
It just makes stakeholders lose trust in the data because they don't understand why there are three different answers to the same question. They don't know what to depend on.
~ Madison Schott, Sr. Engineer at Convertkit (Source)
With data flowing (read: duplicated) between multiple tools across different domains (preferred native stacks), there is unchecked corruption, and it is increasingly difficult to track the lineage and root cause as the proliferation of tools continues. More often than not, to make their lives easier, business users often prefer to simply duplicate the data instead of spending hours or weeks waiting for the integration bridge to get fixed or renewed. This comes from a deficit in awareness of the implications of data duplication or corruption and also the frustration from time lags and inefficient data supply to business use cases.
And without proper integration bridges, there’s no stable model that data developers and business users can rely on. Instead, a legacy model at best with incomprehensible branches - branched out every time a new requirement came in, facilitating the immediate need for facilitating a new tool pipeline or answering a new business query/request.
Overwhelm🔺: Enforced Submission to Different Learning Curves of Different Tools
Every tool has its own design language based on its own design philosophy and approach. This implies different languages, formats, frameworks, or lifecycles. Making interoperability much more complex and selective as well as enforcing steep learning curves to make things work consistently.
End-users who expect value from the tools or data engineers responsible for making the tools talk to each other are expected to learn the design approach of each. Which are often not simple. Even if they were, the need to learn the workarounds for 5-7 tools and integrate them in a user-friendly way disrupts all laws of simplicity and adds to the cognitive overload.
Interoperability challenges force businesses to adopt more tools to fill gaps.
Operational complexity due to the management overhead of integrating, maintaining, and optimizing these tools grows exponentially.
Visibility challenges due to the wide sprawl of tools often led to fragmented data visibility, complicating governance and decision-making.
Tool Inflation🔺: Fragmented Vendor Landscape and Progressive Overlap in Assembled Systems
There was also a socio-political driver of competing with each other that led to similar features popping up across the vendor landscape—claiming to one-up the other. Also, organically, as more tools popped in, they increasingly developed the need to become independently operable, often based on user feedback.
POV: Technical inevitability of a fragmented stack
For instance, two different point tools, say one for cataloguing and another for governance, are plugged into your data stacks. This incites the need not just to learn the tools’ different philosophies, integrate, and maintain each one from scratch but eventually pop up completely parallel tracks. The governance tool starts requiring a native catalog, and the cataloguing tool requires policies manageable within its system.
POV: Inevitability of the business strategy of niche vendor solutions
Vendors began to overlap in features as they competed for market share, making it harder for organizations to consolidate their stacks. For example, a vendor that started with data storage offerings started providing options for cataloguing, data quality, transformation, and so on.
Now consider the same problem at scale, beyond just two point solutions. Even if we consider the cost of these parallel tracks as secondary, it is essentially a significantly disruptive design flaw that keeps splitting the topology of one unique capability into unmanageable duplicates.
Moreover, a lot of capabilities of niche tooling went unused due to overlaps or simply from a lack of requirement (too niche for 80% of the use cases). Unfortunately, that also meant that users/adopters had to keep paying for, say, 100 features of the tool while they were only using 5.
Inflated Wants🔺: Consistent and Increasing Desire to Decentralize!
When systems are pieced together without a cohesive strategy, managing their many moving parts becomes overwhelming. This complexity spills over, making it harder for end users to access the data they need.
Teams like marketing, sales, and support often have to jump through hoops to retrieve even basic insights. Meanwhile, the central data team becomes overloaded with requests, leaving the organization struggling to clear bottlenecks and share the workload across domains.
This is where the early Data Mesh movement put the spotlight on domain ownership—a shift toward decentralization. The idea is appealing: let individual teams manage their own data. But how practical is this approach in the real world? When applied to a functioning business, a few key challenges start to emerge:
Not enough skilled professionals to allocate to each individual domain. Practically, how economically viable is the idea of having data teams and isolated data stacks for each domain?
Not enough professionals or budget to disrupt existing processes, detangle pipelines, and embed brand-new infrastructures.
There are not enough experts to help train and onboard during the process and cultural migration.
It’s both a skill- and resource-deficit issue. Moreover, with decades spent on evolving data stacks with not much value to show, organizations are not ideally inclined to pour in more investments and efforts to rip and replace their work. In essence, Autonomy is of higher priority than Decentralization if a domain’s self-dependence is the ultimate objective.
Solving the Tool Overwhelm: Fix Approach to Modularity Instead of Adding Another Tool.
The intention of siloed tools that targeted specific problems was to become a modular network of solutions that users could interoperate to solve larger problems…
Why is this approach flawed?
Modularity comes from having the simplest form of solutions available as independent building blocks that could be put together in a desirable combination to act as larger solutions. Just like the modular approach to coding, the simplest functions are reusable across the project as classes or even other projects as libraries.
The tools that target specific problems do not act as the simplest unit of solutions but are, in fact, large solutions themselves, directly targeting big chunks of the problem, e.g., Data Quality or ETL.
Each component of this already large solution (tool) does not know how to talk directly to other large solutions (base components of one tool cannot be reused in other applications or solutions). Instead, the whole tool needs to be used through a complex integration with all its very specific design and workflow nuances.
The Right Approach: Non-Disruptive Modularization of the Data Stack
There are two keys to this solution:
Non-disruptive: How do we cut our losses from tooling overwhelm by not adding more disruption to the data team’s or the domain team’s plate? In other words, how can we enhance the experience of existing native stacks?
Modularization: How to enable cross-domain reusability and cut down integration overheads. In other words, how do we unify the approach to work and tools?
Interestingly, modularization, which means splitting a large problem into the lowest forms of independent solutions, enables the unification of the data stack. Note that “Splitting” and “Unification” are in the same sentence. On the other hand, large solutions (niche tools) contribute to more siloes by withholding data and base components within stricter boundaries.
By careful analysis of many implementations, we’ve found that lego-like modularity, enabled by unified data platforms like the Data Developer Platform standard, leads to:

This is in huge contrast to traditional data stacks, which are a collection of tools forced to talk to each other through complex and highly time-consuming integrations. Leading to the following experience of data practitioners in the industry:
70% of respondents are driven to use more than 5-7 different tools or work with 3-5 vendors for different tasks, such as data quality and dashboarding.
About 10% use more than 10 tools, showing the increasing complexity of the Data Landscape.
About 40% of the respondents spend more than 30% of their time jumping from one tool to another to ensure they work well together.
Setting Up a Utility Plane to Facilitate a Modular Architecture
A Utility Plane acts as the foundation for enabling modularity by providing a set of core utilities and services that are lightweight, reusable, and interoperable across the data stack.
Unlike traditional tools designed for specific niches, the utility plane focuses on delivering atomic, building-block capabilities that can be composed and orchestrated to address diverse use cases.
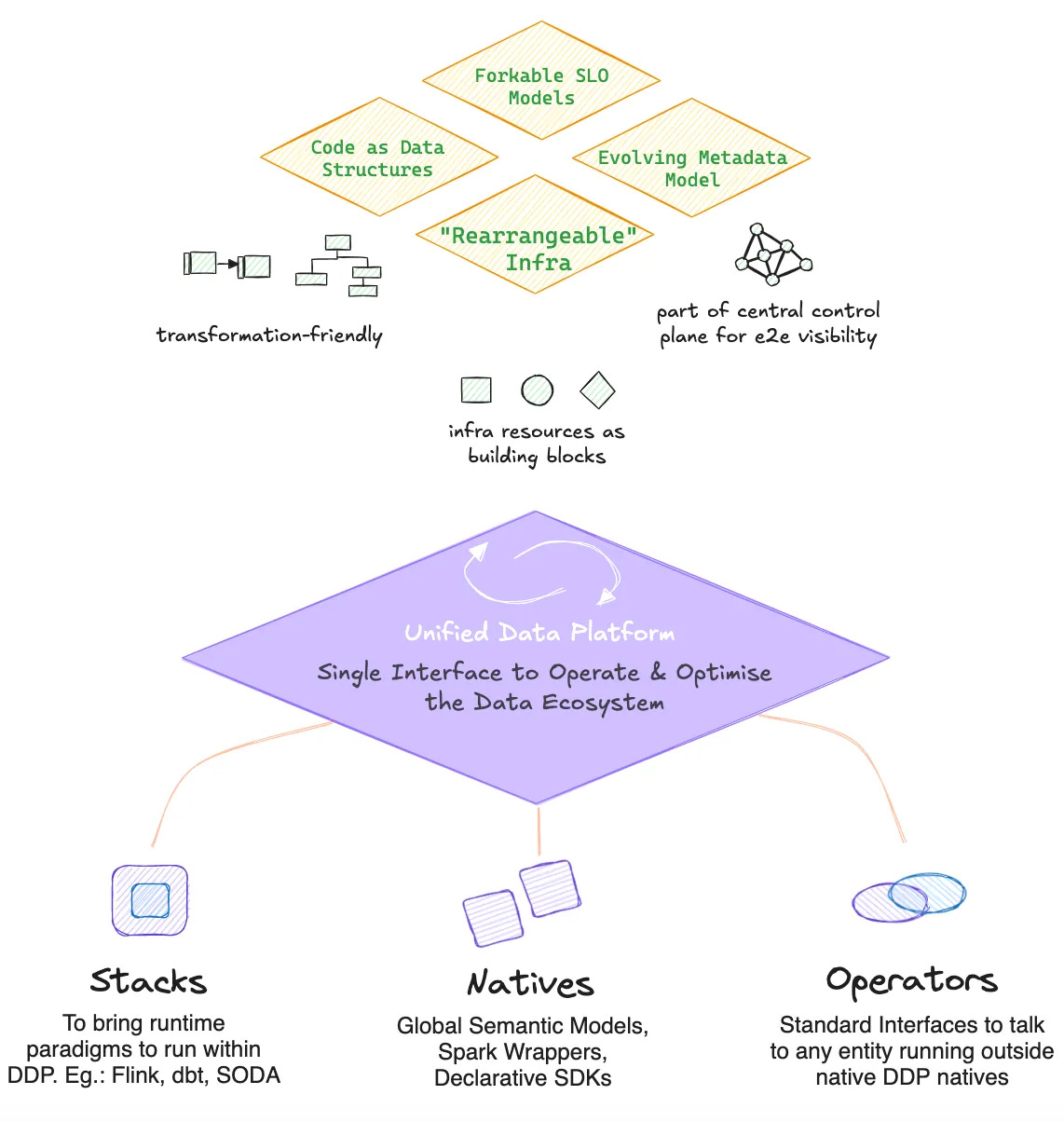
Core Principles of a Utility Plane
Atomicity and Granularity
The utility plane offers the smallest possible units of functionality—think of these as “functions” in software development. Examples might include data validation rules, transformation functions, or metadata retrieval mechanisms. These are designed to solve micro-problems and be stitched together into larger workflows as needed.Interoperability
All components within the utility plane are designed to communicate seamlessly through standardized protocols or APIs, avoiding the rigid boundaries often imposed by monolithic tools. This enables tools and teams to work together without needing heavy custom integration efforts.Neutral Layer
It serves as a neutral foundation, sitting below domain-specific solutions and allowing teams to build their custom logic or workflows without vendor lock-in or tool-specific dependencies.Incremental Adoption
The utility plane does not disrupt existing systems; rather, it enhances them. Teams can adopt individual utilities incrementally based on their immediate needs without needing to replace or overhaul their current tools or workflows.
Benefits of a Unified Utility Plane
Flexibility: Teams can use only the utilities they need, reducing overhead and complexity.
Reusability: Utilities designed once can be reused across teams, domains, or even organizations.
Reduced Tooling Overlap: By focusing on modular capabilities, the need for niche tools that address overlapping challenges diminishes.
Scalability: The utility plane scales both horizontally (by adding more utilities) and vertically (by composing complex solutions from simple building blocks).
📝 Related Reads
Beyond the Data Complexity: Building Agile, Reusable Data Architectures Why Evolutionary Architecture is Important in a Data-Driven World
Expanding on “Reduced Tooling Overwhelm & Overlap”
By establishing a utility plane, we cut down tool-centric siloes with a modular and unified architecture. This is especially enabled through three design paradigms of a Utility Plane:

Native resources as building blocks
Resources, such as storage, compute, workflows, services, policies, clusters, and models, are available as modular solutions that developers can instantiate and reuse across solutions and data products.External resources a building blocks: Operators
Operators act as modular interfaces that communicate with tools running outside the unified platform. The operator registers resources that are not native to the platform and enables the (external or native) orchestrator in control to identify and orchestrate these resources. The operator resources make the platform truly extensible and customizable.External resources a building blocks: Stacks
The utility plane enables the modularity of existing tool stacks such as dbt, Flink, or SODA. It enables ring diverse runtime paradigms like dbt, Flink, and SODA into the ecosystem without requiring them to be rewritten.
How does this help? One-time integration development and continuous health management are delegated to the platform through declarative means. Moreover, these foreign paradigms are encapsulated in a way that aligns with the platform’s unified standards, enabling users to access and operate different stacks through a common interface and pattern (cutting down the cognitive overload and learning curves that come with different tools).
Over time, having a common operating interface helps the organization come up with a more unified data strategy to condense not just tooling options but the approach to work as a whole. The ability to clearly bundle “building blocks” to specific solutions under domains gives organizations the sheer ability to attribute costs to domains as well as understand the implications of different existing tools on the overall cost-time efficiency.
For instance, the out-of-the-box ability of unified platforms to manage data product lifecycles and optimize data product value and performance by:
Monitoring usage and adoption across data products.
Tracking performance and costs for each data product (which includes tooling & resource costs)
Measuring business impact and ROI.
Implementing a Unified Utility Plane with Data Developer Platforms
Data Platforms modelled after the Data Developer Platform (DDP) standard serve as a non-disruptive utility layer seamlessly integrated into existing data infrastructure. Acting as a critical enabler, this utility layer ensures modularity and alignment with specific business goals while maintaining the integrity of current operations. The architecture cultivates a unified approach to managing data workflows across the end-to-end Data Product Stack.
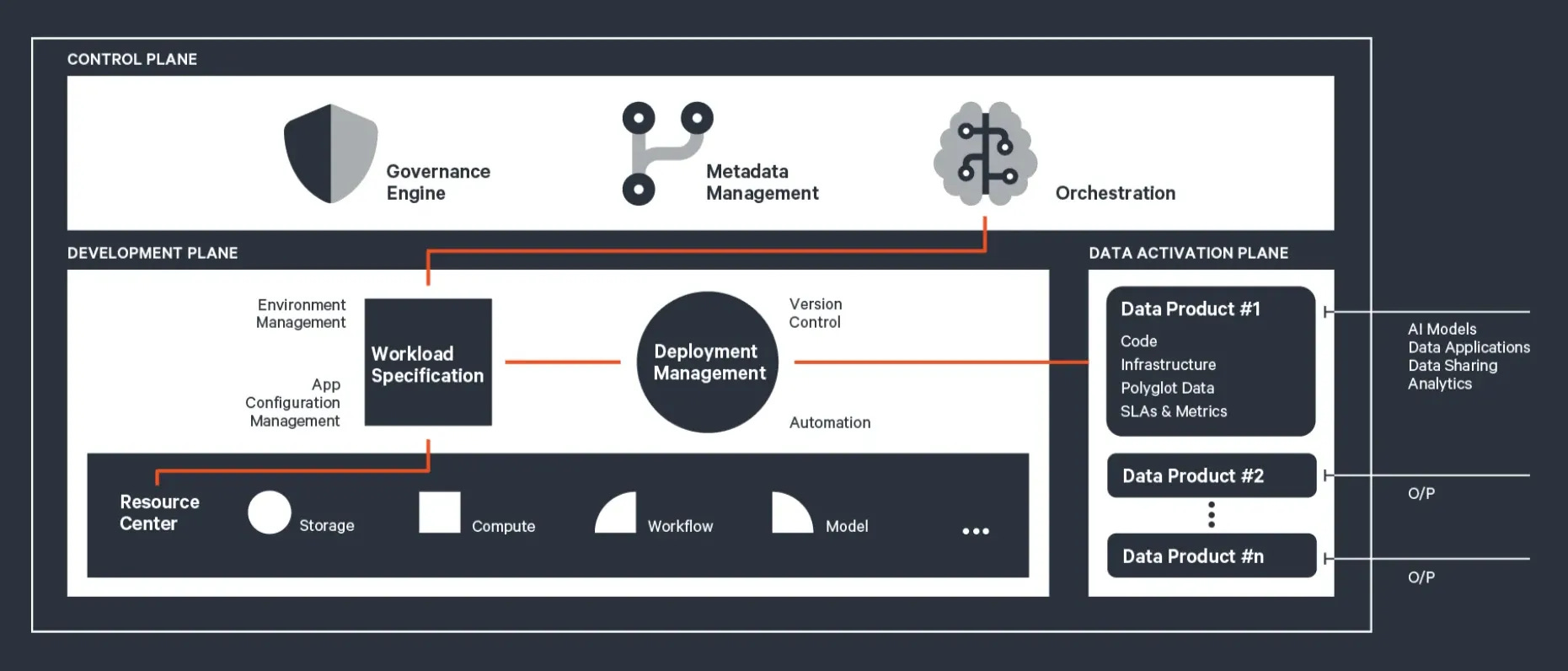
Central Control Plane: Unifying Visibility, Access, and Governance
When any tool or stack is plugged into the platform, the Central Control Plane gets complete visibility and anchors the system by providing end-to-end visibility to other integrated tools and standardization through its three core engines:
Unified Orchestration: Automates workflows, ensuring seamless task execution across pipelines.
Unified Metadata: Establishes a clear lineage, context, and discovery layer for data assets, enhancing efficiency and compliance.
Unified Governance: Reusable modular policy models that can be applied to different use cases or data products depending on standard domain requirements completely or partially.
This model is based on the principles of Hybrid Decentralization, which strives to enable domain-driven decentralization within feasible boundaries. You can learn more about our approach to hybrid decentralization here and here.
Development Plane: Modular Design with Building Blocks
The Development Plane is designed to modularize code, workflows, and resources, presenting them as reusable building blocks. These building blocks can be tailored to specific use cases, enabling a composable architecture. This is where data developers can utilize the three design paradigms (native resources, stacks, and operators) to build modular solutions for data products, specific business queries, global metric models, and so much more.
Targeted Use Case Enablement: Right-to-Left Approach
The platform's design emphasizes a right-to-left flow, starting with the business outcome and tracing backward to define the technical execution. For example:
Identify a business problem or use case, such as enhancing customer segmentation or improving operational efficiency.
Align specific data products, infrastructure, and processes to solve the challenge.
Utilize modular resources and configurations in the Development Plane to deploy solutions quickly.
This reverse-engineered methodology ensures that every technical effort is laser-focused on driving measurable business impact.
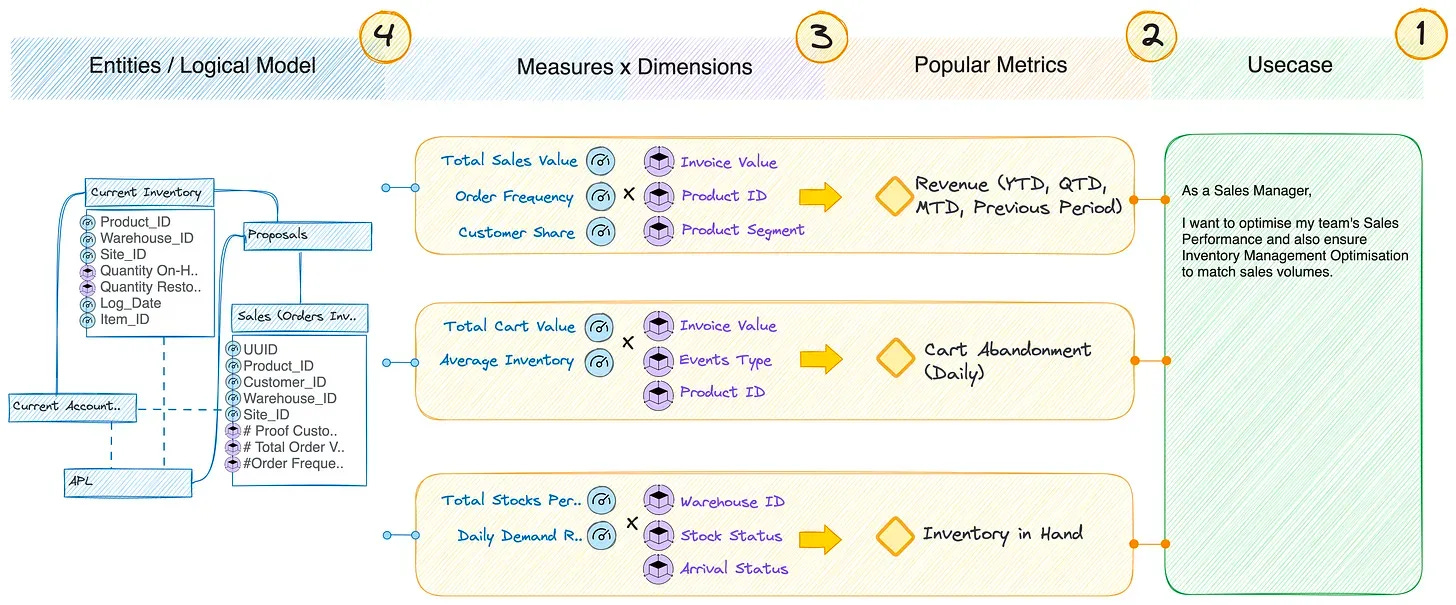
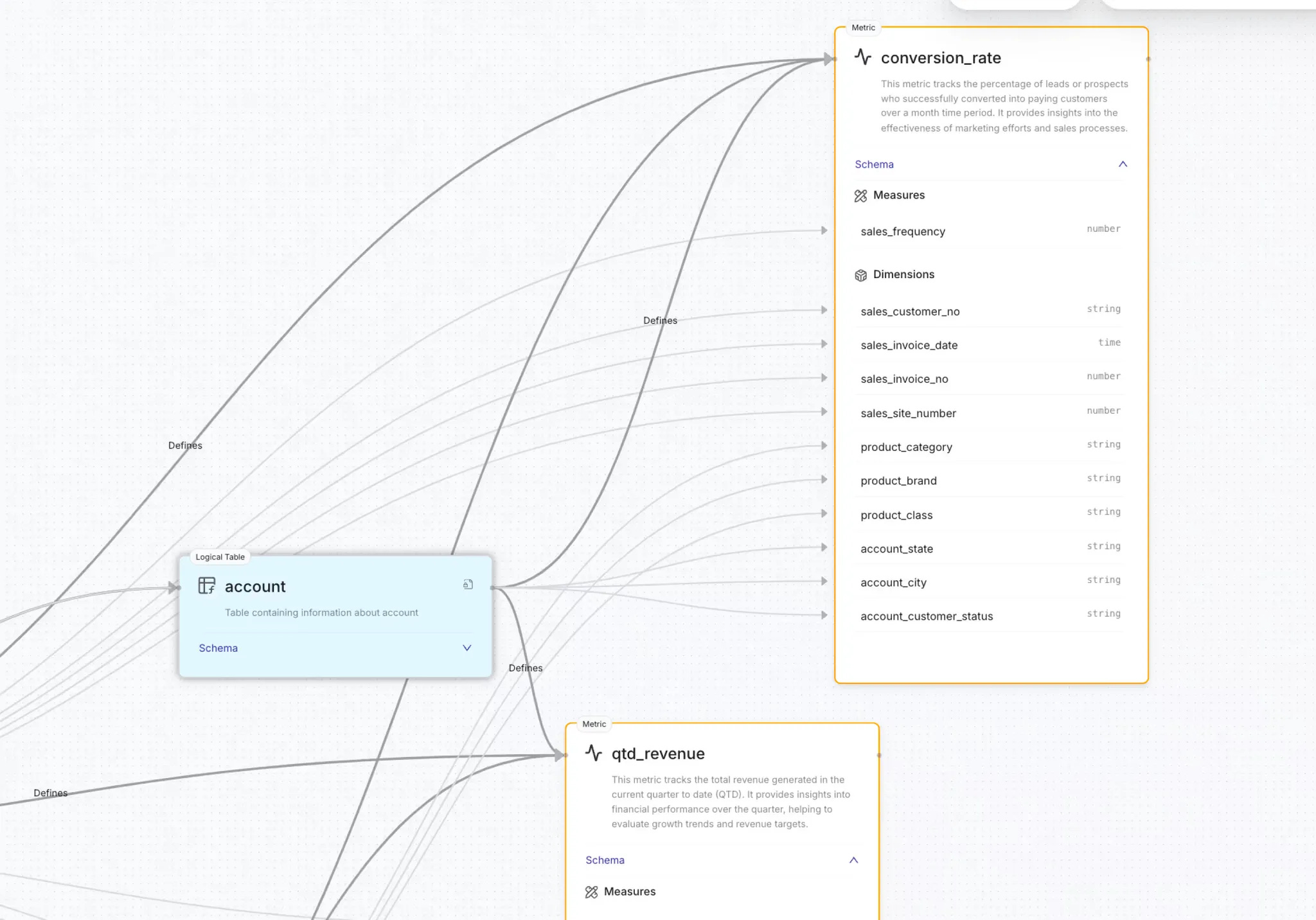
Semantic Models: Unlocking Interoperability and Reusability
Semantic models play a pivotal role in bridging the gap between technical layers and business outcomes. Acting as a shared vocabulary across stakeholders, these models:
Enable interoperability between data products by standardizing how information is structured and accessed.
Enhance reusability, allowing data assets and workflows to be applied across multiple contexts without duplication.
Simplify collaboration, providing clarity for both technical teams and business users.
By integrating semantic models into the architecture, the DDP transforms raw data into actionable insights while ensuring alignment with business objectives.
📝 Learn More About Data Developer Platforms
datadeveloperplatform.org
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 🖋️

Connect with me on LinkedIn 🤝🏻

Connect with me on LinkedIn 🙌🏻

Connect with me on LinkedIn 🤜🏻🤛🏻
 | A guest post by
|
 | A guest post by
|
Yesssss