
The Contract-driven Data Platform
What if there was a different way to build a data platform, one that is made up of consistent, interoperable, governed data products?

About Our Contributing Expert
Andrew Jones | Creator of Data Contracts, Principal Engineer & Author

Andrew Jones is a Principal Engineer and Author, specialising in modern data architecture and platform design. He is widely recognised as the creator of data contracts, an approach introduced in 2021 that redefines how organisations manage data quality, ownership, and governance by treating data as a product with explicit, enforceable interfaces. He is also part of the LinkedIn Top Voices recognition, an invitation-only group of experts across the professional world.
Andrew has spent over a decade building large-scale data platforms, including leading foundational data platform initiatives at GoCardless, where he pioneered the implementation of data contracts to enable reliable, revenue-generating data products. He currently serves as a Principal Data Engineer at Springer Nature.
In 2024, he authored a definitive book on data contracts, consolidating years of practical experience into a widely adopted industry reference. Beyond his technical work, Andrew is an active contributor to the data community, a member of Google Developer Experts, and part of the technical steering committee for Bitol, helping shape open standards for data contracts and data products. We’re honoured to feature his insights on Modern Data 101.
We actively collaborate with data experts to bring the best resources to a 20,000+ strong community of data leaders and practitioners. If you have something to share, reach out!
🫴🏻 Share your ideas and work: community@moderndata101.com
*Note: Opinions expressed in contributions are not our own and are only curated by us for broader access and discussion. All submissions are vetted for quality & relevance. We keep it information-first and do not support any promotions, paid or otherwise!
Let’s Dive In
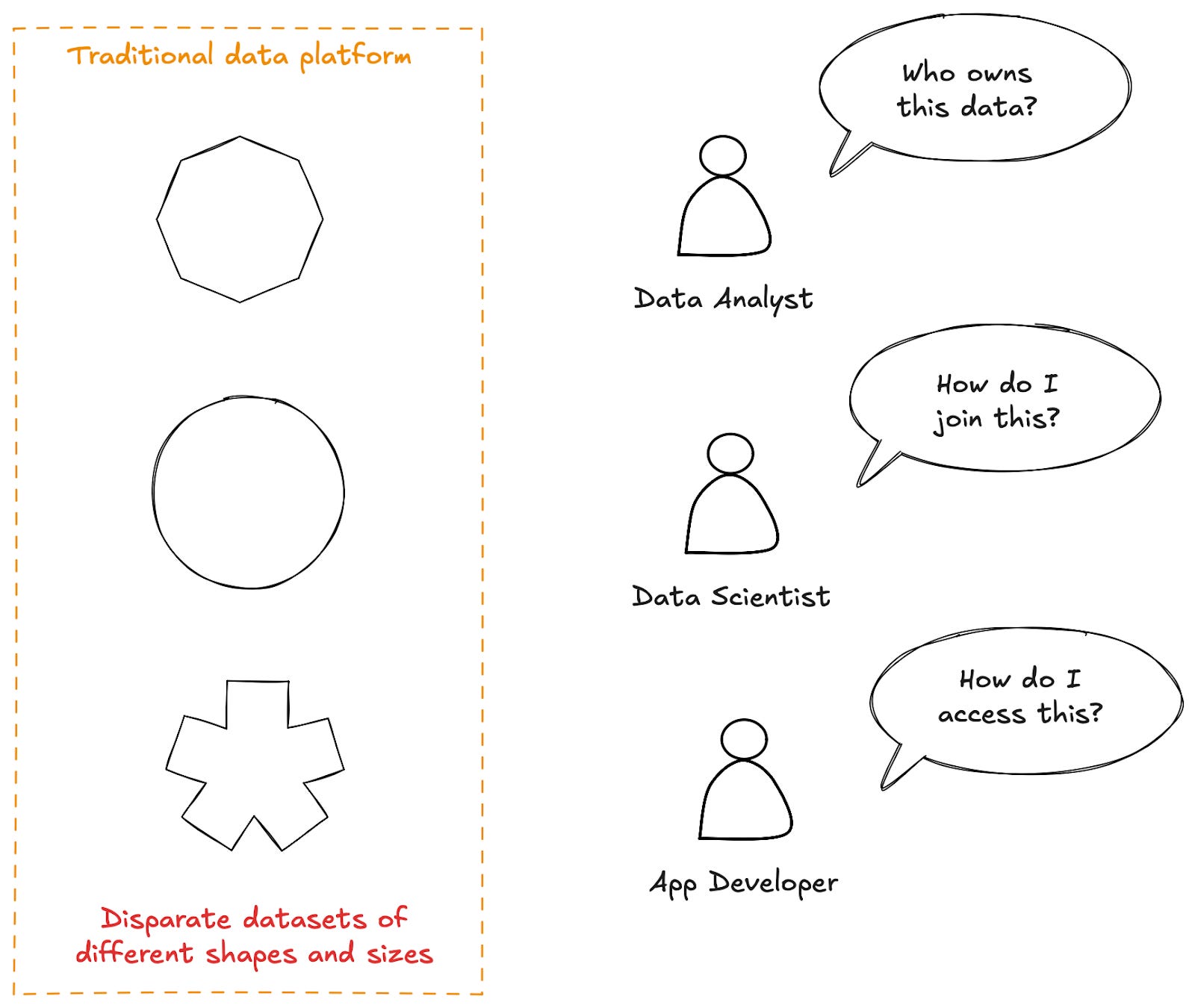
Traditional data platforms are a mix of disparate datasets with different attributes, different capabilities, and different levels of governance, each created and managed through complex custom workflows.
For data consumers, this results in data that is difficult to use. Every time someone wants to consume a dataset, they need to gather all the context required to do so, from scratch, often by tracking down and asking the right individual in the organisation. This increases the cost of using data, reducing its applicability.
Then, once they have found enough context to make use of the data, consumers often find it does not work well with other datasets.
There are no standard naming conventions, and no common keys to join on. If they want to join this data, they will have to create complex pipelines to do so first.
On the other side, data producers find publishing data is expensive and time-consuming. They need to learn how to make this data available and create all the workflows to do so. They then, as data owners, need to learn how to manage this data in accordance with a dozen internal data standards and take responsibility for doing so.
All of this disincentivizes the sharing of potentially valuable data.
What if there is a different way to build a data platform?
One that is made up of consistent, interoperable, governed data products that can be easily and confidently consumed to create valuable applications, either directly or through the use of AI, all built on a Unified Data Infrastructure?
There is, and it’s what I call the contract-driven data platform.
However, to build that, we need to apply more structure and discipline to the data, and in particular, its metadata.
It’s this metadata that gives consistency to the data, easing the use of data by data consumers, human or AI. It also gives the platform the context it needs to automate these management tasks, guaranteeing governance.
We capture this metadata in the data contract.
And so, it’s the data contract that enables the contract-driven data platform.
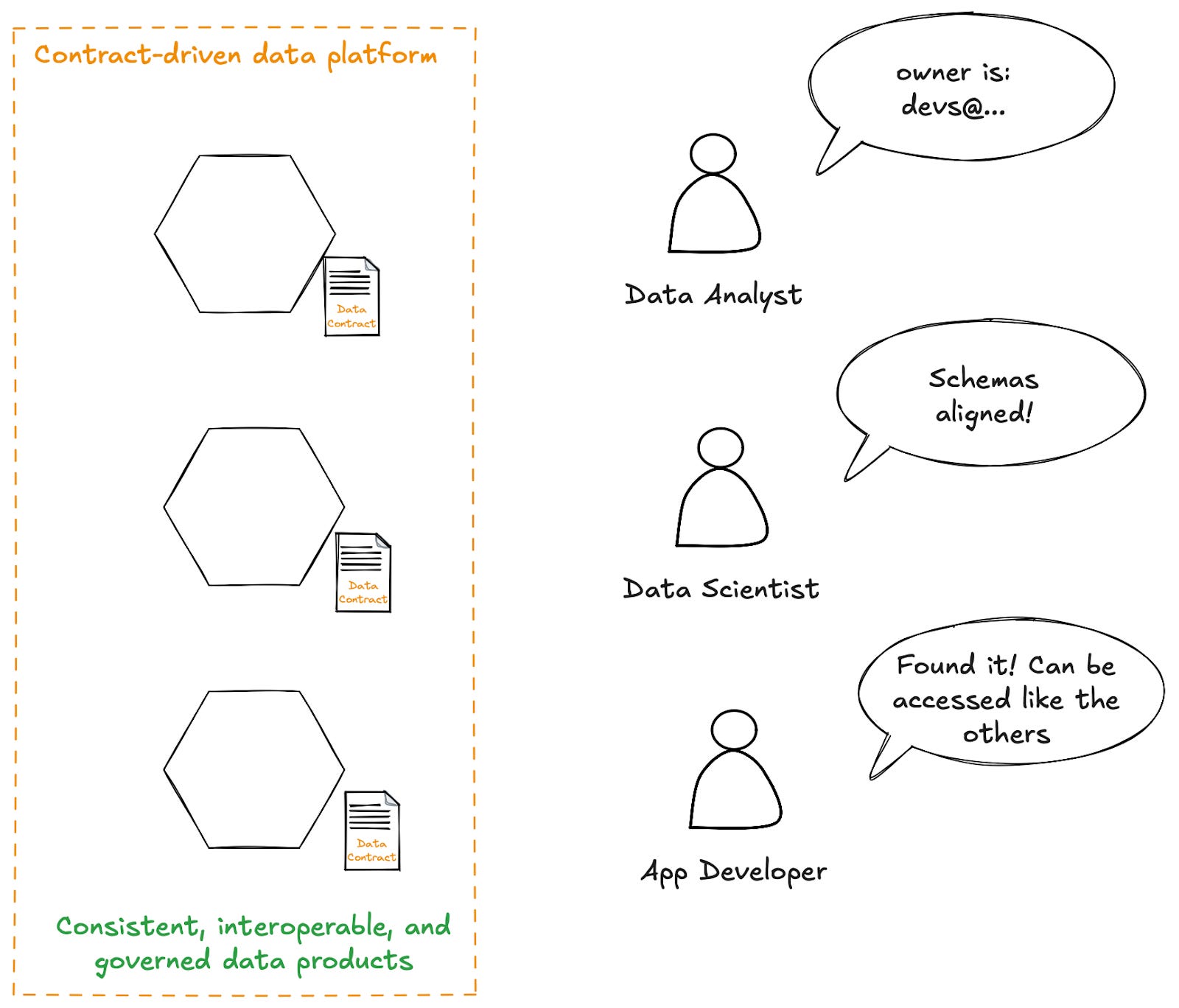
What is a contract-driven data platform?
A contract-driven data platform moves the focus of data engineering and platform teams away from building point solutions to building a platform of generic capabilities that allow them, and anyone else, to easily and cheaply build interoperable data products without having to think about:
How do I make this data available?
How will this data work with existing datasets?
How do I deploy this data pipeline and related workflows?
How do I implement data retention?
How do I manage access?
And so on.
It is a step-change in how we build data platforms that reduces the cognitive load for both data producers and data consumers, enabling the greater availability and applicability of data across the organisation.
As I wrote in my book, Driving Data Quality with Data Contracts, there are three principles to a contract-driven data platform.
Automation
Consistency
Governance
Automation
There are several common tasks that need to be carried out on the data and the resources we use to manage it, no matter what that data is and who owns it. These tasks are great candidates to automate, reducing the effort the data producers need to spend managing the data.
These include taking backups of the data, moving data to different storage engines based on its age, and anonymizing or deleting personally identifiable data as it exceeds its retention period.
Using the metadata defined in the data contract, we can easily build small services that automate these tasks. These services can be deployed alongside each contract and have sensible defaults, so most data producers never need to configure them.
We’ll be looking at some examples of these later in this article.
Consistency
By providing this standard tooling to all data generators through data contracts, we’re promoting greater consistency in how our data is managed, accessed, and consumed.
Every data consumer knows how to discover data that is managed through a contract-driven data platform. They know how to look up the expectations around that data, and how to find its owner. They know how the access controls are set up, and how to ask for the permissions they need.
Similarly, every data producer knows how their data and resources are being managed. They can switch between working on different datasets without losing context or having to learn new tools or a slightly different implementation of the same tools. When there is an incident, they know exactly where to look for their service configuration, to view their observability metrics, and recover data from their backups.
This contract-driven tooling becomes the golden path. It is the only supported tooling and the default choice for data producers across the organization.
Governance
We want to enable data producers across the organization, but we can’t expect everyone producing data to be experts in data management. Instead, we can provide them with the tooling that guides them and take care of as many of these concerns for them as we can.
That allows the data producers to focus on delivering the data to their consumers, without constant engagement and review from central data governance teams, which becomes a bottleneck and slows down development speed across the organization.
The reason why that review is no longer needed is that the governance is embedded in the tooling they are using. As long as data producers are using the tools provided by the contract-driven data platform, the data governance teams can be certain the data is managed in accordance with their governance standards.
We’ll see an example of this shortly.
Implementing the contract-driven data platform
Now that we understand the power of the contract-driven data platform, let’s look at how we would implement it. We will start by defining the data contract, then show how this data contract drives the data platform.
Defining the data contract
The first thing you need when building a contract-driven data platform is, of course, to define the data contract.
This data contract needs to be in a human- and machine-readable format. Being human-readable allows it to act as an artifact that can be discussed by different groups and teams across your organisation, while being machine-readable enables the automation and tooling described earlier.
There are many ways to define a data contract. Many choose a YAML file that follows the structure of the Open Data Contract Standard (ODCS), some define their data contracts in code, some use a custom UI, and some define them in spreadsheets!
The key is to choose a format your users will be happy to write and maintain, which ideally means meeting them where they already are. This reduces their friction to adopting data contracts and provides them with the best user experience.
If those users are software engineers, then it’s best to provide them with a data contract definition they can maintain as code, alongside other code artefacts within their git repository, alongside the code that generates the data. That’s why my first data contract implementation used Jsonnet to define the data contracts, because that’s exactly what our software engineers expected.
However, if your users are not software engineers but instead admins for CRMs or other data systems, then a spreadsheet or custom UI would be a better solution.
The next important consideration is to ensure the data contract is subject to change management. This is critical for providing data products that data consumers can build on with confidence, knowing the structure and semantics of the data will not change in a way that breaks your application without giving you a chance to migrate to a newer version of the data contracts.
In practice, this means your data contract is versioned, and there are checks in place to implement compatibility rules to prevent breaking changes without a new version being created and a migration path followed.
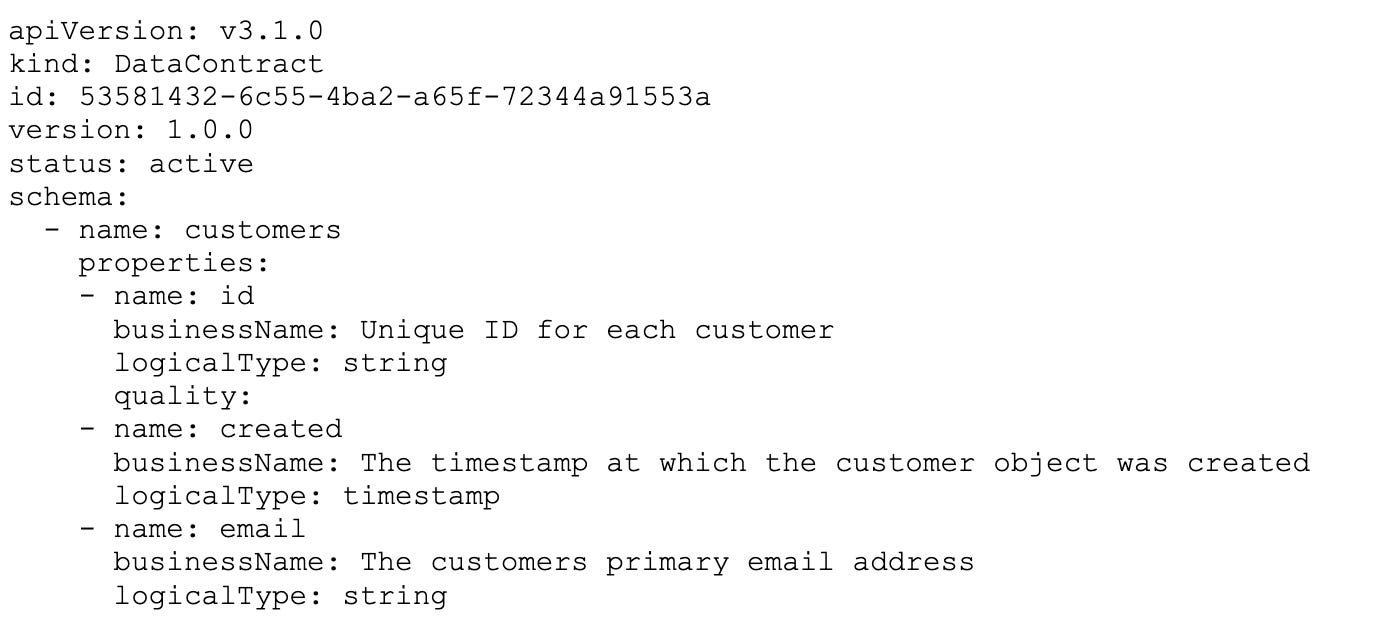
The final part every data contract needs to have is a description of the data - i.e., a schema. A data contract that doesn’t describe data would not be much use.
For the purposes of this example, here’s a minimal data contract defined in YAML following the ODCS:
Driving the data platform from the data contract
Now that we have our data contract, we can start to drive our data platform from it.
Firstly, we can use this data contract to provision a table in the data warehouse by simply taking the data contract, converting it into a format understood by our infrastructure as code platform (Terraform, Pulumi, etc), and having it manage this table.
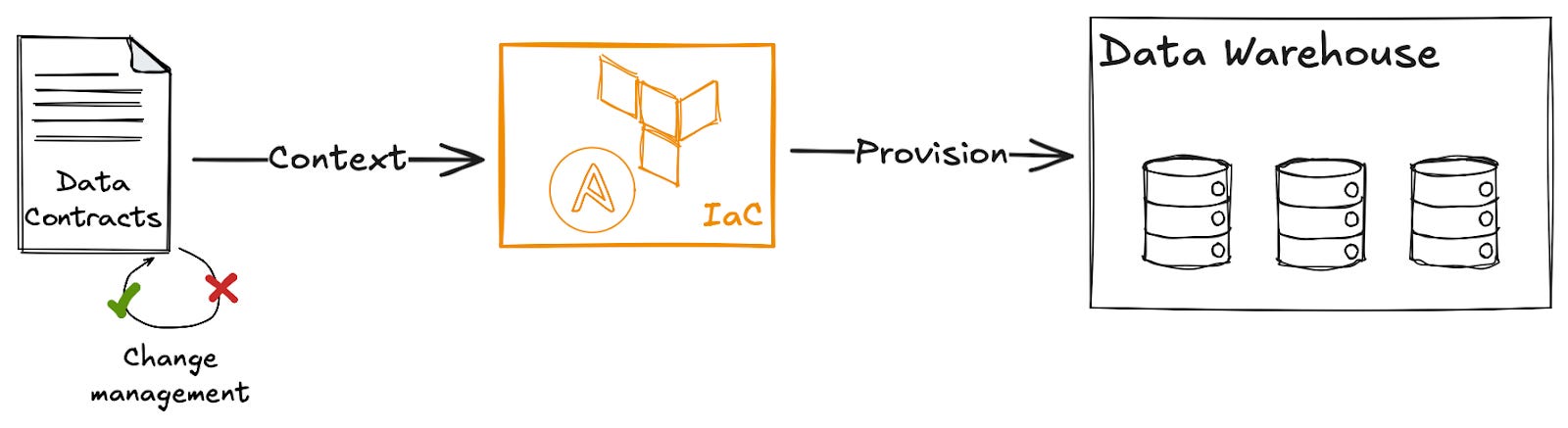
As the data contract is under change management, then by extension so is the table in the data warehouse. This gives our data consumers a stable interface they can build on with confidence, whether they are building reports, data-driven applications, or leveraging AI.
But with a little bit more context in the data contract, we can add more capabilities to the data platform. For example, we could add quality rules to some of the fields and a channel for alerts:
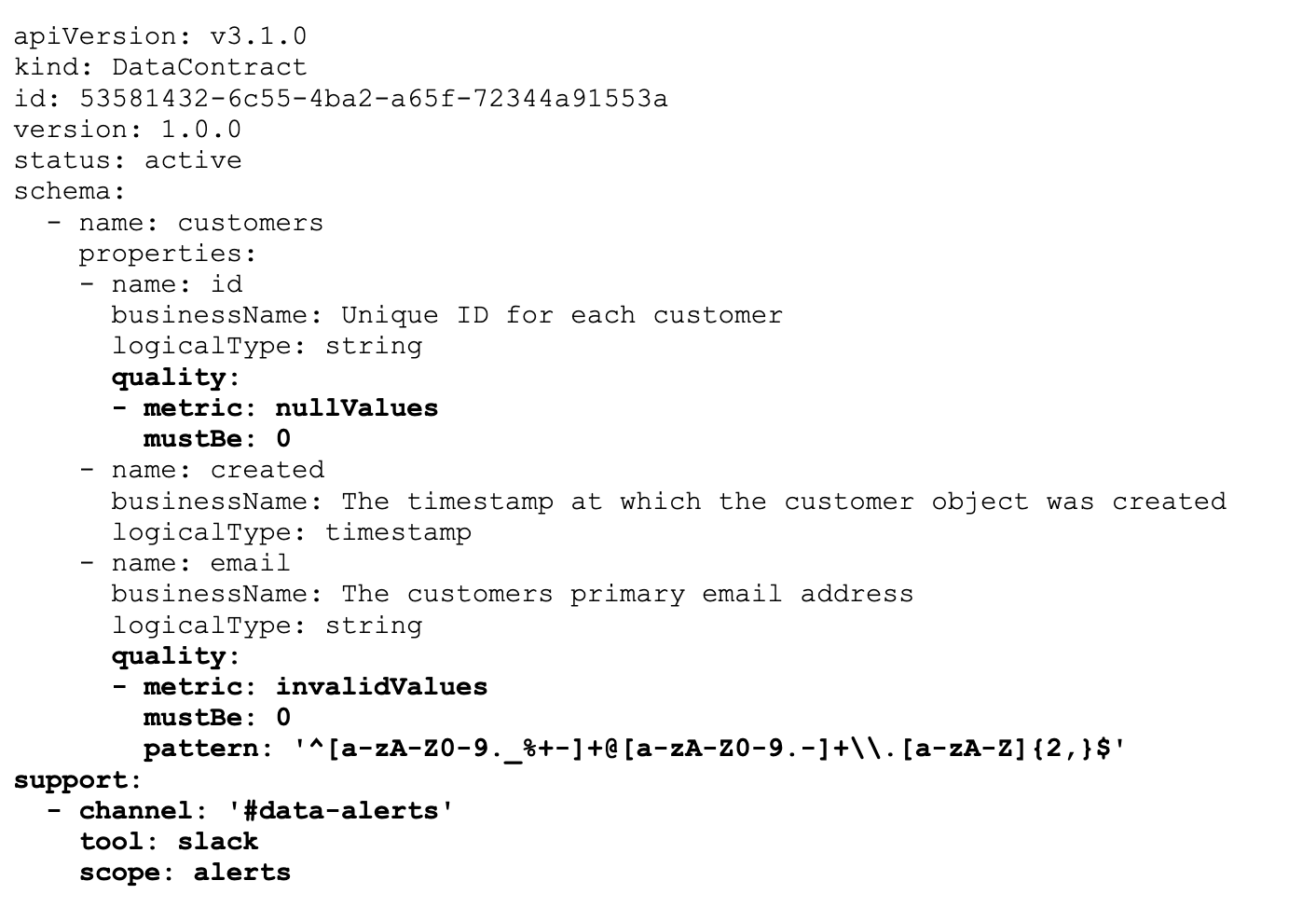
The data platform can now automatically deploy an observability service to run those rules and route the alerts to the right team.
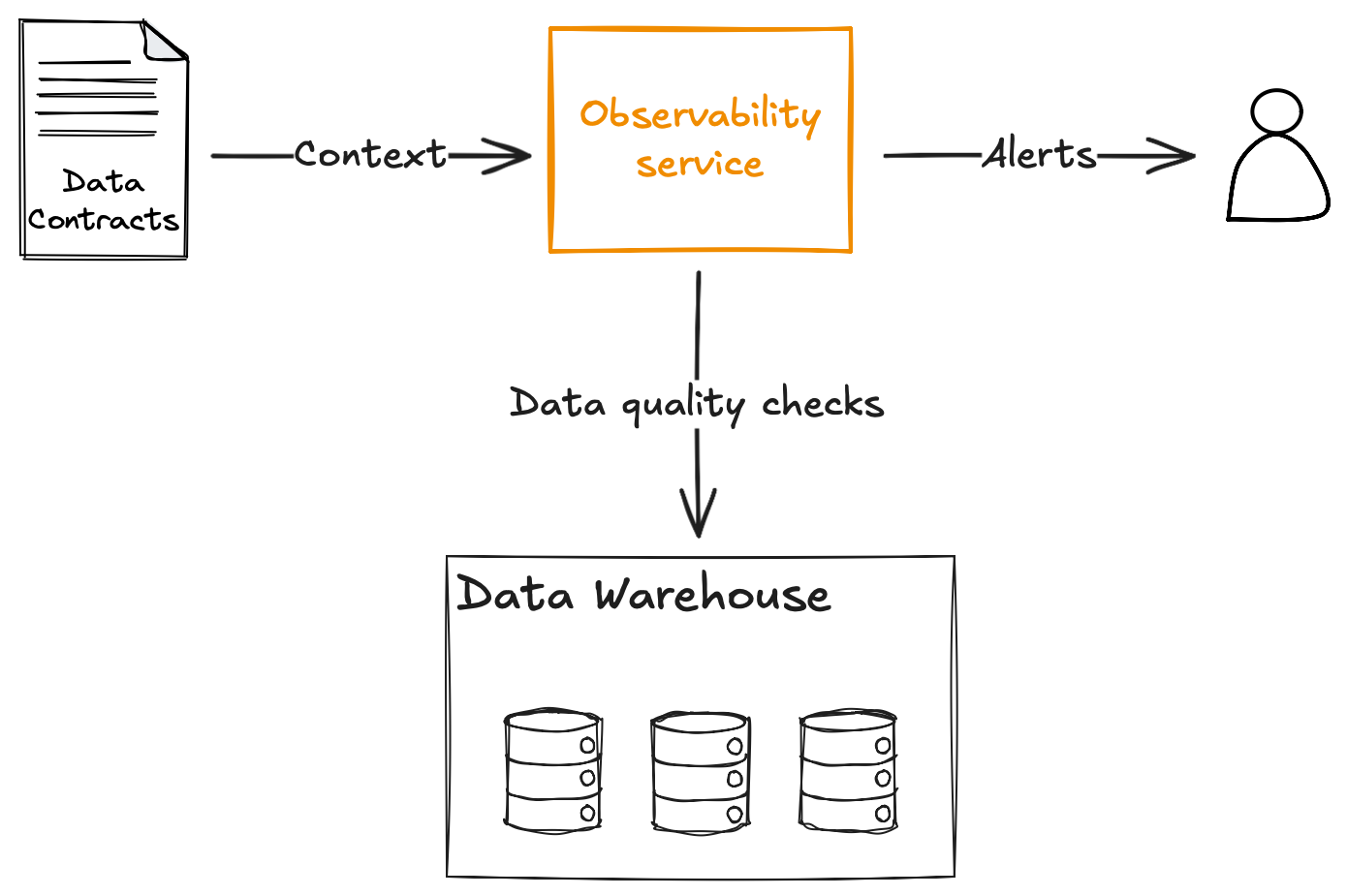
As a data producer, this is great! I no longer need to set up my own infrastructure to run data quality checks, manage my own orchestrator, and so on. I just describe what I want, and the platform automates it.
Similarly, one of our fields contains the email address of a customer. This is personally identifiable and needs to be managed correctly in line with our data governance policies and local regulations.
As a data owner, I’m responsible for the management of this field, but I’m not an expert in data governance, and I don’t want to have to build a process and automation to do this when I have delivery work to prioritise. Instead, I should be able to categorise it in the data contract:
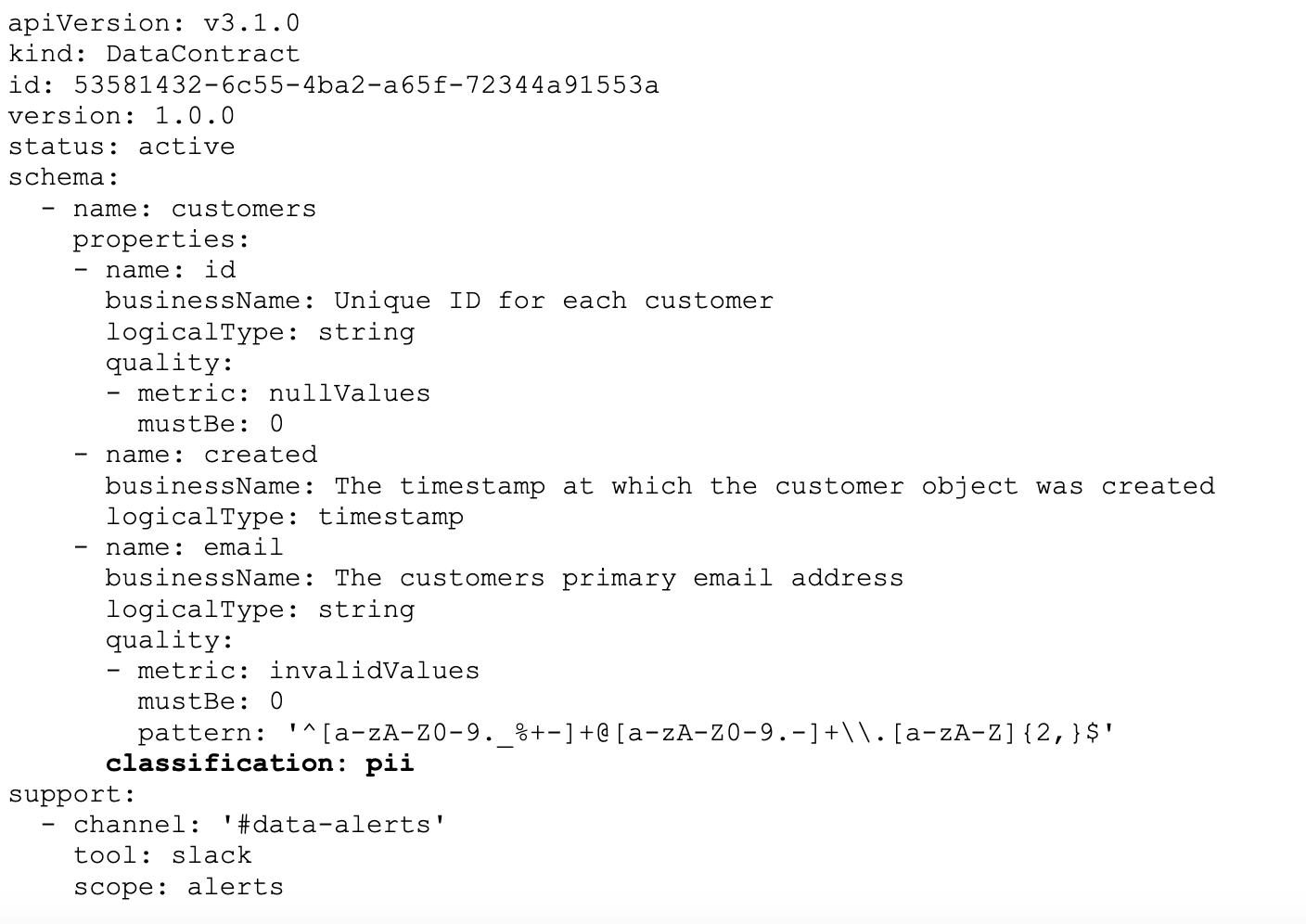
Then the data platform has all the context it needs to ensure this field is managed correctly, with access granted to those with legitimate need to access the raw data, and data retention policies applied when we should no longer be storing this data.
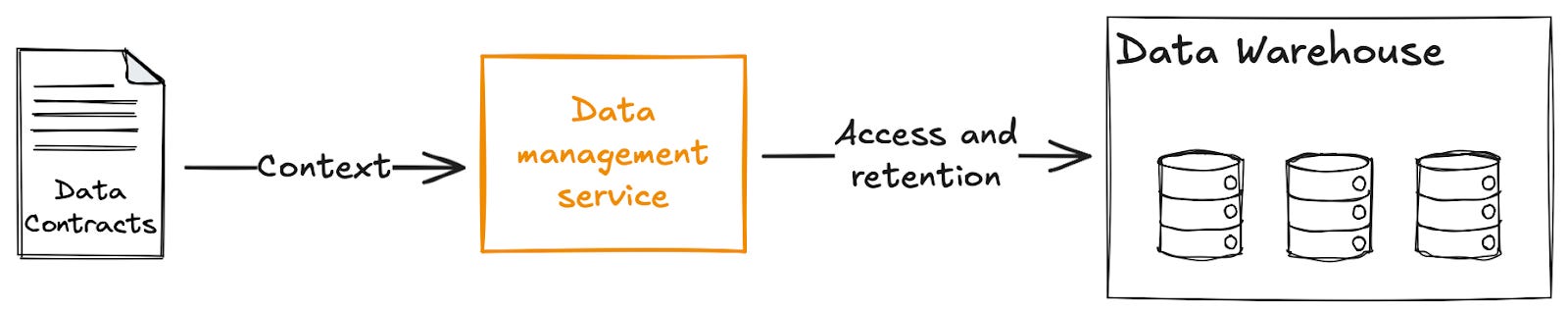
All of these services are relatively trivial to implement. They simply take the context from the data contract and apply the correct automations and rules to the data it describes.
Because we are building on the metadata, not the data, these tools and any future tools we provide are automatically available to all data associated with a data contract, no matter what domain the data belongs to, its owner, or its specific structure. All the required context is in the metadata, allowing the tools to be generic.
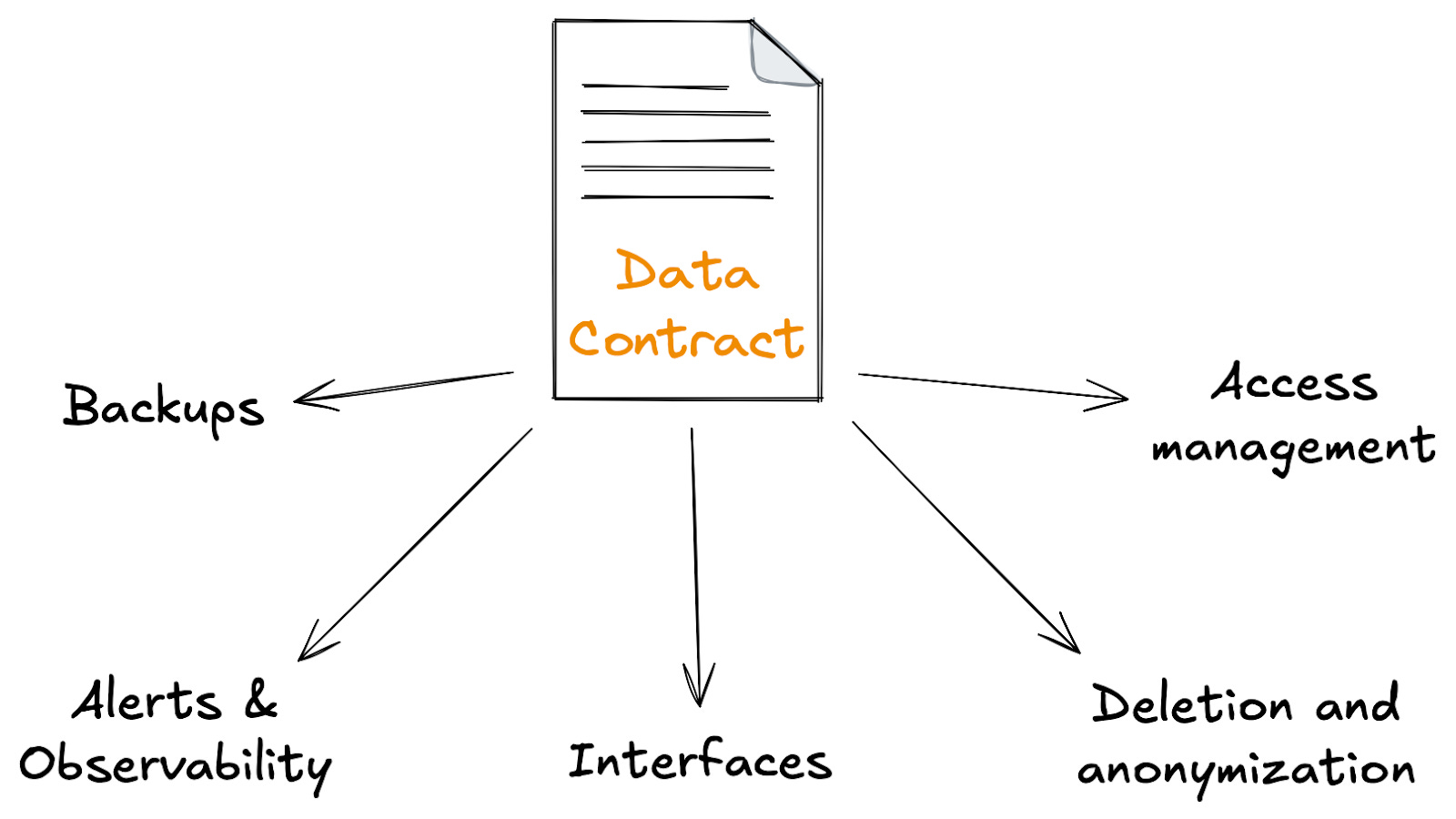
Since I started implementing data contracts over 6 years ago, this is how I’ve been building data platforms, and so far, I’ve yet to find a data platform capability that cannot be implemented in this way, from simple capabilities such as backups to role-based access management.
This is the power of the contract-driven data platform, a step-change in building a data platform that is made up of consistent, interoperable, governed data products.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 💬

Connect with Andrew on LinkedIn 🤝🏻
More from Andrew

From MD101 team 🧡
🌎 Global Modern Data Report 2026
The Modern Data Report 2026 is a first-principles examination of why AI adoptions are getting blocked inside otherwise data-rich enterprises. Grounded in direct signals from practitioners and leaders, it exposes the structural gaps between data availability and decision activation.
With hundreds of datapoints from 540+ data leaders and experts from across 64 countries, this report reframes AI readiness away from models and tooling, and toward the conditions required and/or desired for reliable action. Already downloaded 1000+ times, this report is enabling key insights for several industry practitioners this year. Join the discussions!

 | A guest post by
|