
Semantic Foundations for Reliable Enterprise AI
Why Your LLM is Only as Smart as Your Data Contract

About Our Contributing Expert
Anvar Atash | Data & Product Leader

Anvar Atash is the founder of SirDash and a product and data leader with more than a decade of experience building data platforms, AI-powered products, and analytics solutions across automotive, IoT, and enterprise data sectors. He has led high-impact initiatives at organisations including Mercedes-Benz, CARIAD, IOMETE, and SirDash, helping teams improve forecasting, operational efficiency, observability, and data-driven decision-making.
Throughout his career, Anvar has focused on simplifying complex data ecosystems, transforming fragmented data assets into accessible, governed, and actionable business intelligence. His work spans data platforms, semantic technologies, machine learning applications, and product strategy, with a particular interest in making data more intuitive and useful for business users.
Today, he continues to advance the field of data products and semantic intelligence, exploring new ways to bridge the gap between business questions and the underlying data that powers modern organisations. We’re thrilled to feature his insights on Modern Data 101.
We actively collaborate with data experts to bring the best resources to a 20,000+ strong community of data leaders and practitioners. If you have something to share, reach out!
🫴🏻 Share your ideas and work: community@moderndata101.com
*Note: Opinions expressed in contributions are not our own and are only curated by us for broader access and discussion. All submissions are vetted for quality & relevance. We keep it information-first and do not support any promotions, paid or otherwise!
Let’s Dive In
Last quarter, I dedicated three weeks to diagnosing why a purportedly “enterprise-ready” large language model (LLM) consistently generated inaccurate Q3 revenue figures. The issue was neither the prompt nor the context window.
The root cause was a semantic mismatch: in the marketing database, the ‘revenue’ field referred to gross revenue before discounts, whereas in the finance database, it denoted net revenue after returns.
The LLM averaged these values, producing a result that was linguistically correct but financially misleading.
Currently, there is significant focus on retrieval-augmented generation (RAG) pipelines and vector databases. However, in most cases, LLM performance is constrained not by model architecture but by disorganized and inconsistent data [1].
The problem staring at us
A common misconception is that simply aggregating large volumes of data into an index will enable artificial intelligence to derive accurate insights. This assumption is incorrect.
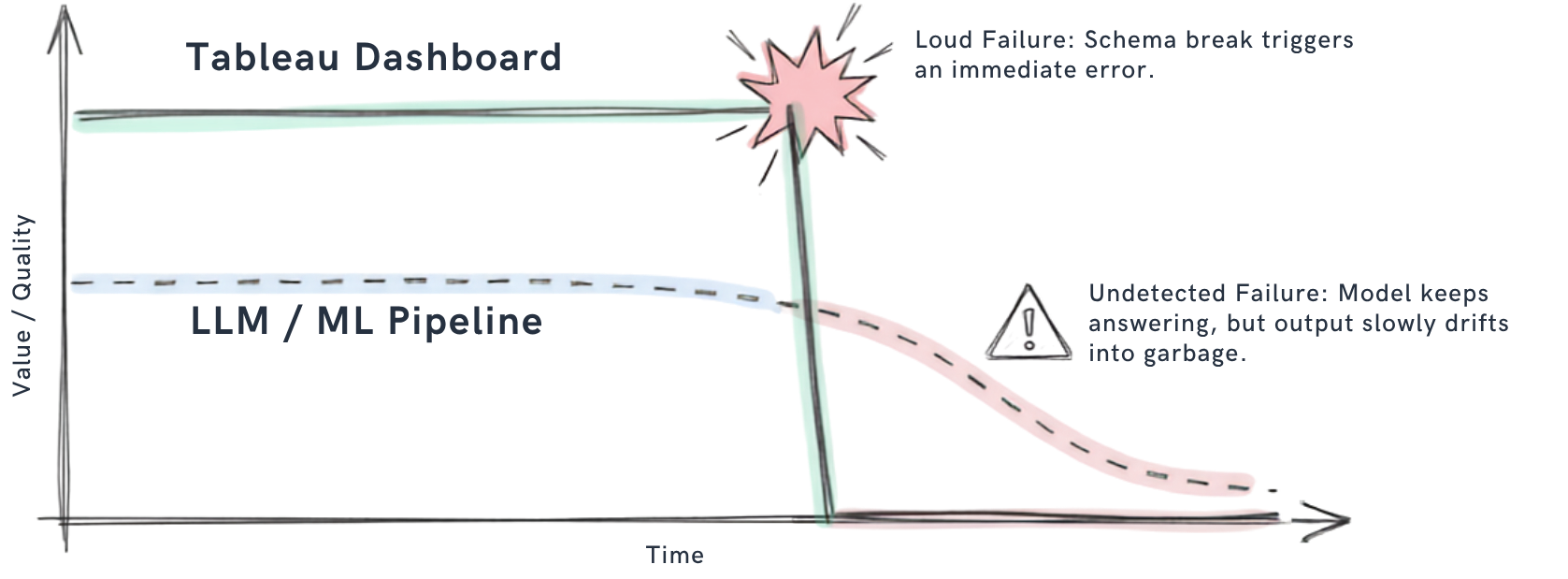
When a schema change disrupts a Tableau dashboard, the resulting error is immediately apparent. In contrast, when the same schema change affects a machine learning pipeline or an LLM, the failure is undetected. The model continues to provide responses, but the quality of its outputs gradually deteriorates [3].
Solution: High-trust relationships between producers and consumers
A data contract is intended as a formal agreement between data producers and data consumers. It specifies the schema, service-level agreements (SLAs), and the underlying semantics [1].
In practice, however, most data contracts are limited to JSON schemas that merely validate data types and nullability, offering little substantive value beyond basic structural checks.
These contracts often neglect semantic definitions. Without explicit semantics, a data contract provides limited utility for AI applications. If the contract does not clearly define terms such as “active user” within the specific business context, the LLM will infer its own meaning, often incorrectly.
The Ontology Pipeline
Several data leaders and decision makers lack a comprehensive understanding of ontologies, yet may not acknowledge this gap. They often assume that simply applying an existing taxonomy, such as the Google Product Taxonomy, to their data warehouse is sufficient.
This approach is inadequate. Achieving true machine understanding of data requires a systematic, layered construction. Information science has provided a framework for this process for decades, known as the Ontology Pipeline, introduced by Jessica Talisman.
The Root Cause: A Lack of Visibility
The inevitability of data contracts arises from a fundamental challenge: data producers often lack awareness of downstream use cases for their data, primarily due to insufficient visibility.
Software engineers responsible for upstream systems are seldom tasked with maintaining data dependencies. Consequently, when they implement updates that alter the schema, tightly coupled downstream data systems may fail.
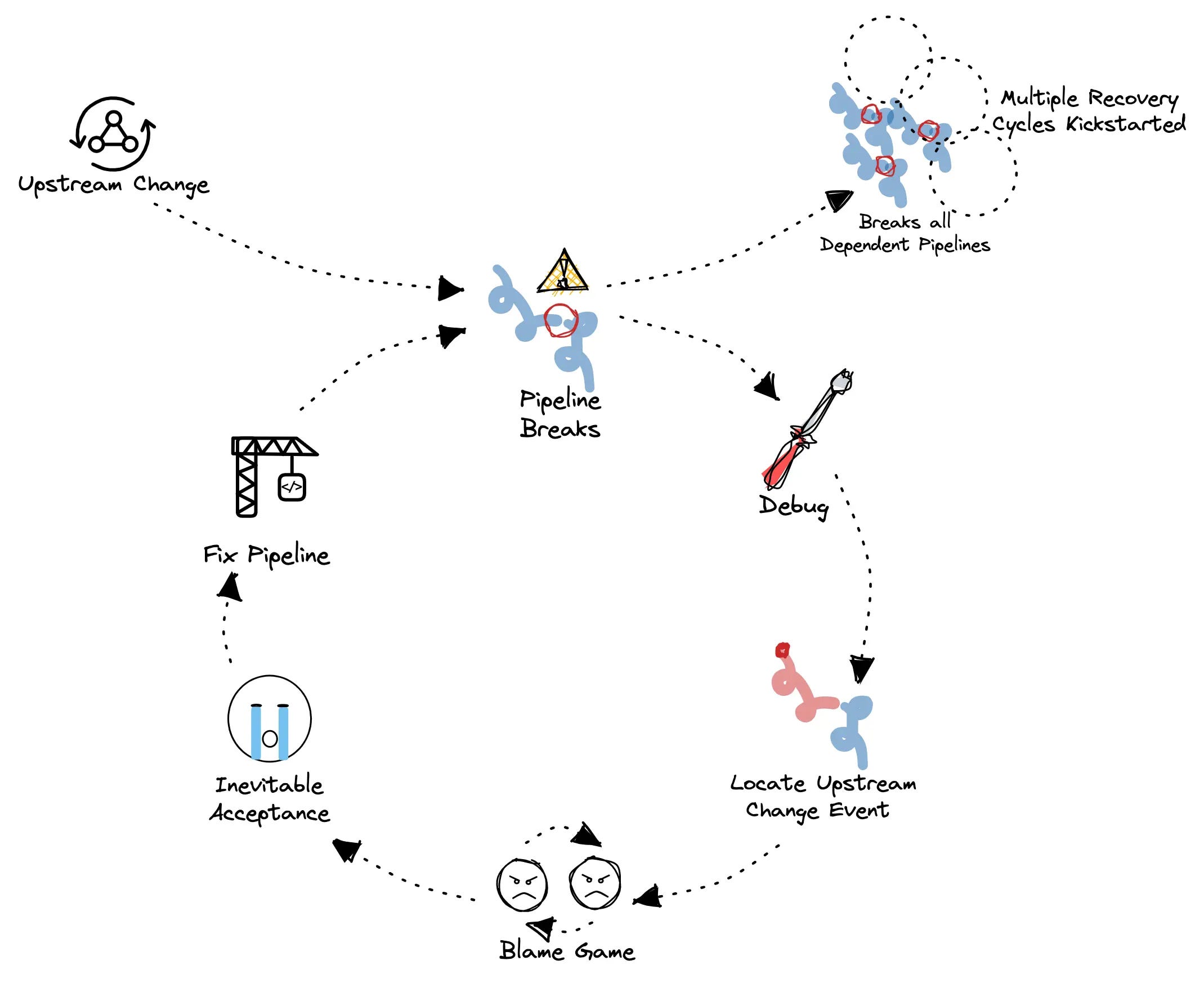
Efforts to increase visibility and expand data usage for machine learning and production-level consumer applications necessitate higher data standards. Data teams pursue data contracts to establish a clearer understanding and explicit requirements regarding data production and its evolution over time.
At a basic level, this process may begin with informal documentation. However, effective implementation typically involves structured formats such as JSON, Avro, or Protobuf, maintained consistently across teams and integrated with a schema registry to track contract modifications.
Consolidating Meaning with the Ontology Pipeline
If the goal is for machines to achieve genuine understanding, rather than mere pattern recognition, it is instructive to adopt methodologies from librarianship. The field of Library and Information Science provides principled and logical approaches for transforming data into information and subsequently into knowledge.
This discipline led to a progression into the Ontology Pipeline, an extensively documented and organized methodology by Jessica Talisman, MLS, for constructing semantic knowledge management systems. It comprises a sequence of iterative building blocks, with each phase establishing the foundation for the subsequent stage.
Here’s how it works and why each layer matters for your LLM:
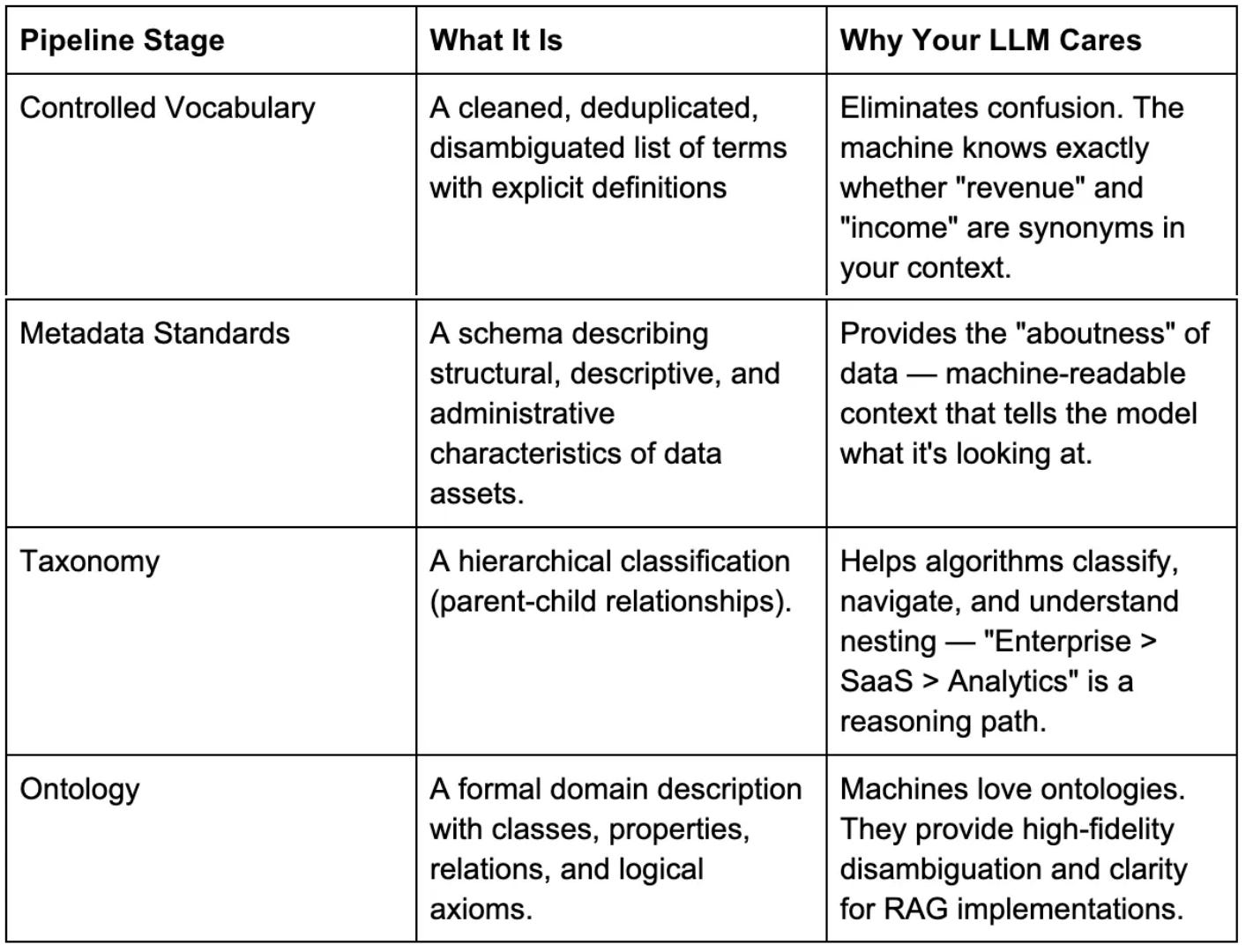
Attempting to construct an ontology without first establishing a controlled vocabulary results in a costly and confusing network of synonyms.
Knowledge Graphs: The Rosetta Stone
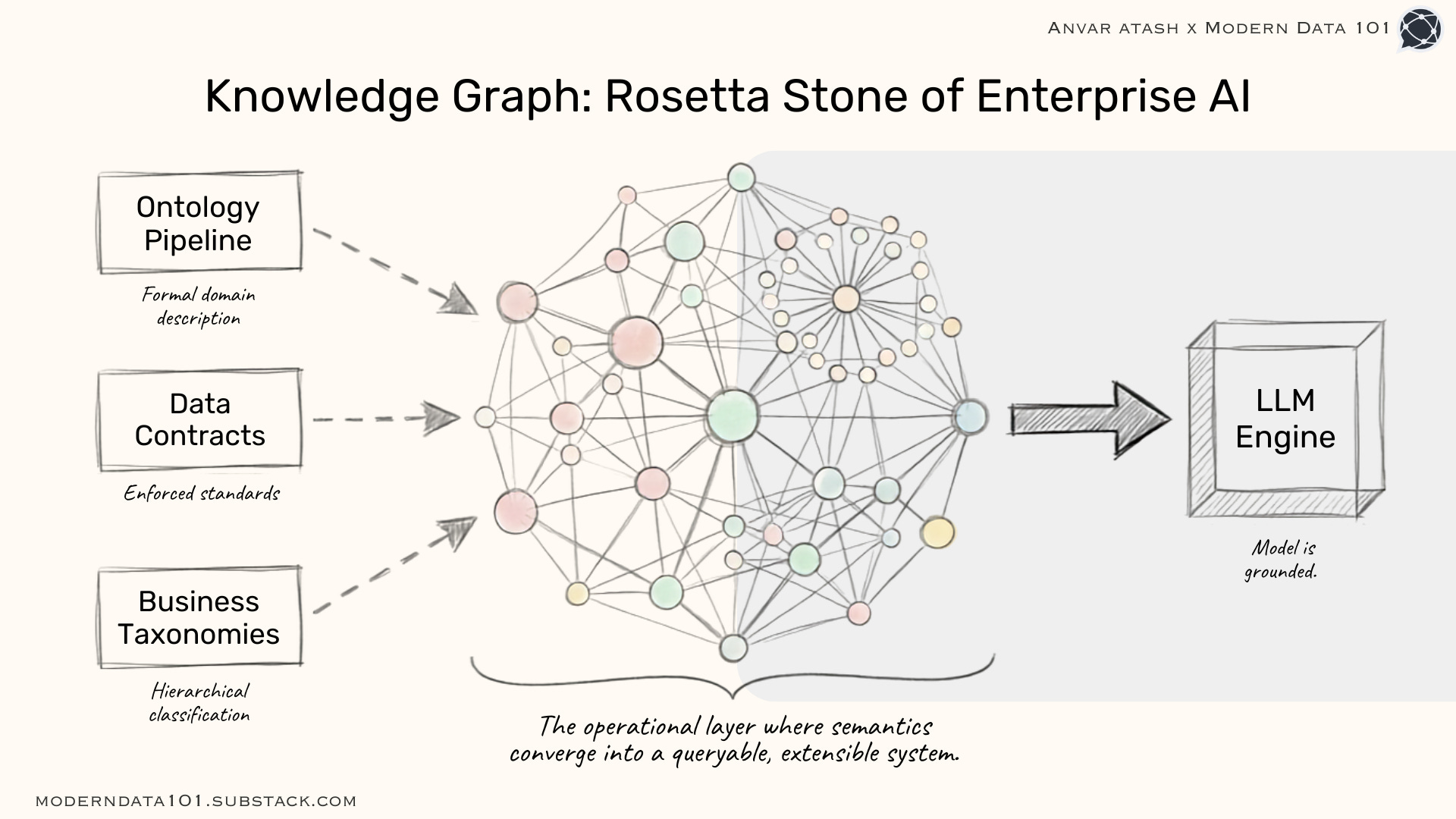
The integration of these layers culminates in a knowledge graph, which serves as a foundational tool for semantic knowledge management. A knowledge graph functions as the operational layer where controlled vocabularies, taxonomies, thesauri, and ontologies converge into a queryable, extensible, and machine-readable system.
When an LLM is grounded in a knowledge graph developed through a rigorous ontology pipeline, it transitions from inference to precise understanding. The model recognizes, for example, that Product X belongs to Category Y, is sold in Region Z, and that the metric ‘active users’ is calculated according to a strictly defined formula, as specified in the data contract and semantically anchored in the ontology.
This distinction differentiates a chatbot that provides approximate figures, such as ‘I think revenue was around $2M,’ from a system that delivers precise statements: ‘Net revenue for Q3, excluding returns and calculated per the IFRS definition in your finance ontology, was $2.14M.’
The Cultural Nightmare
One critical aspect often omitted from vendor presentations is the significant organizational and political challenges associated with implementation.
Software engineers are typically focused on delivering new features and may not consider the impact of their changes on downstream machine learning models. For instance, altering a column name can inadvertently disrupt the retrieval-augmented generation (RAG) pipeline [1].
Encouraging adherence to data contracts necessitates a substantial cultural transformation, often requiring intervention from both the Chief Technology Officer (CTO) and Chief Data Officer (CDO).
It is advisable not to attempt comprehensive data contracting immediately. Instead, prioritize areas of highest impact, such as financial data requiring precise accuracy or core machine learning models that directly influence revenue.
Failure to address semantic issues at the source will result in ongoing efforts to compensate through prompt engineering, attempting to guide a billion-parameter model to interpret data that lacks internal consistency.
Why Semantic Management Isn’t Optional Anymore
As artificial intelligence continues to advance, the need for structured and semantically enriched data will increase. LLMs amplify the characteristics of the data they receive; without robust data contracts, they perpetuate existing semantic inconsistencies and errors.
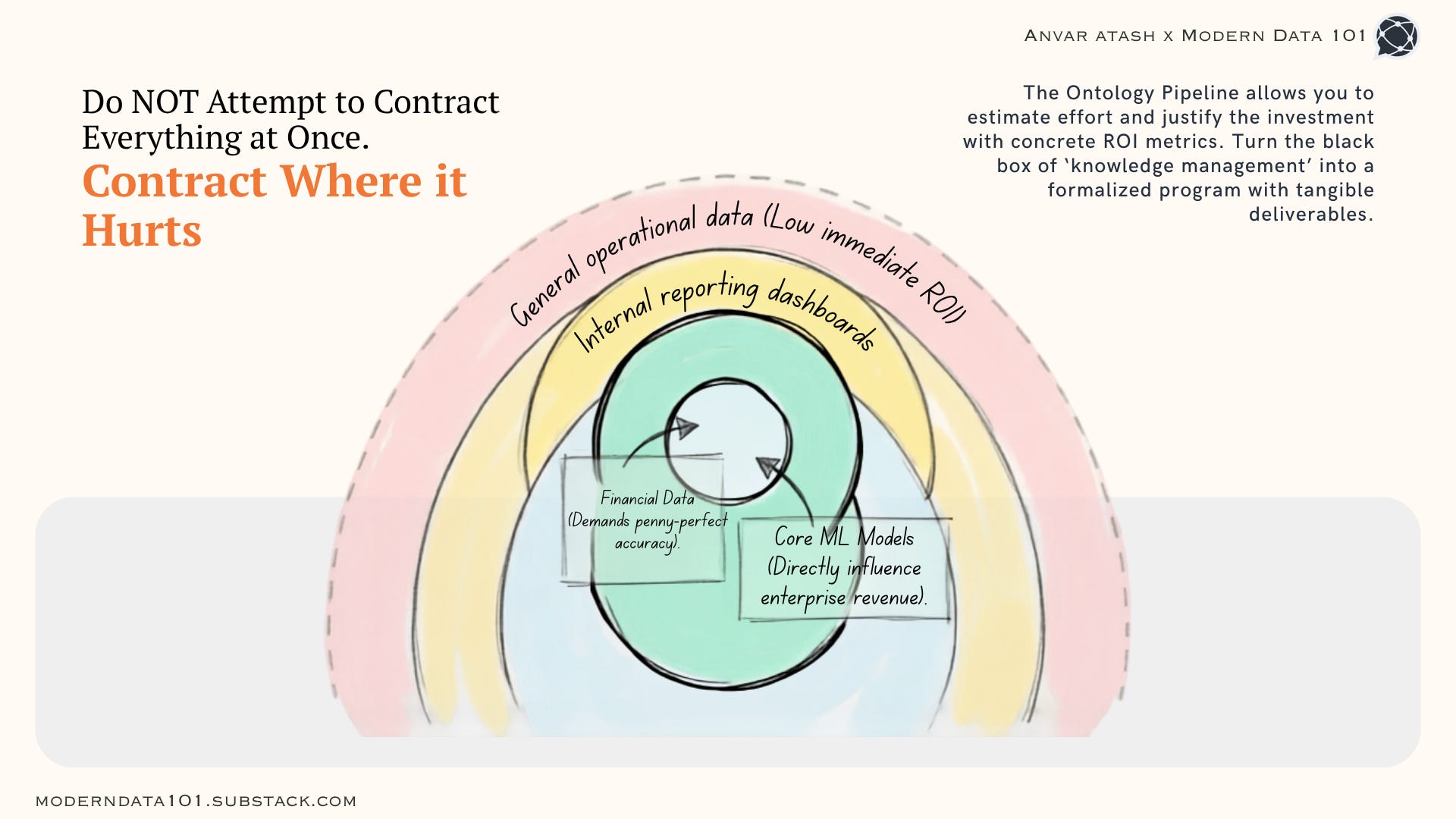
The Ontology Pipeline provides a repeatable and validated framework. It allows organizations to estimate required effort, justify investments using concrete return-on-investment (ROI) metrics, and establish a robust foundation for reliable AI systems.
This approach transforms the ambiguous concept of ‘knowledge management’ into a formalized program with defined phases, measurable outcomes, and tangible deliverables.
When a language model produces inaccurate outputs, it is important to examine underlying data practices rather than attributing fault solely to the algorithm. Key questions include whether data contracts encode semantic meaning or merely structure, and whether a controlled vocabulary exists or if multiple spreadsheets contain inconsistent terminology.
If these questions reveal deficiencies, investment in a semantic layer becomes essential. This is not a matter of following trends, but of ensuring that AI systems are as effective as the semantic clarity embedded in organizational data. Currently, many organizations expect advanced models to interpret data that lacks internal coherence.
Effective artificial intelligence begins with well-defined semantics; without this foundation, even advanced models function as little more than costly autocomplete systems.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 💬

Got questions? Find Anvar on LinkedIn or drop a comment below. 💬
References
[1] Data Contracts: How They Work, Importance, & Best Practices
[2] The Rise of Data Contracts
[3] Chad Sanderson (LinkedIn): “How data contracts can ensure high quality data for ML models”
[4] Tech Guide: Data Contracts & Data Tests
[5] Preventing Issues with Data Contracts & Testing
[6] The Ontology Pipeline by Jessica Talisman
[7] AI-Driven Generation of Data Contracts in Modern Data Platforms
[8] Data Quality and AI: Why Your AI Needs a DBA
[9] Automatic Data Contracts with LLMs
[10] How to Mitigate AI Biases Using Data Contracts
[11] Using Data Contracts as a Value Assessment Framework for Data or AI Initiatives
[12] Arjen van Berkum (LinkedIn): “Training your LLM on contracts: friend or future risk?”
[13] Data contracts: What are they and why do they matter?
[14] The Solution to Data Management’s GenAI Problem
 | A guest post by
|