
How Long Until We Call AI Agents Data Products
Most teams treat agents like experiments. The ones that survive production treat them like data products with users, feedback loops, and a roadmap.

About Our Contributing Expert
Alejandro Aboy | Senior Data & AI Engineer, Writer

Alejandro is a Senior Data & AI Engineer and the voice behind The Pipe & The Line, a technical newsletter where pipelines meet product thinking. With a career that began in marketing and web analytics, he transitioned into modern data engineering, bringing with him a sharp instinct for business context, experimentation, and stakeholder alignment.
At Workpath, Alejandro serves as the main owner of the Data Platform & AI stack. He builds AI agents with RAG architectures (Pgvector on Aurora), designs MCP-based tool ecosystems, and implements production-grade AI observability. His work spans dbt modeling, orchestration with Airflow, Slack-to-Tableau automation, and secure backend design for agentic systems.
Alejandro is deeply engaged in the open data community. He has collaborated with OpenMetadata on agentic data modeling and metadata-first architectures, co-authoring end-to-end implementations that connect lineage, governance, and AI tooling through MCP. His writing is frequently featured by Modern Data 101 and other leading data publications. We’re thrilled to feature his unique insights on Modern Data 101!
We actively collaborate with data experts to bring the best resources to a 20,000+ strong community of data leaders and practitioners. If you have something to share, reach out!
🫴🏻 Share your ideas and work: community@moderndata101.com
*Note: Opinions expressed in contributions are not our own and are only curated by us for broader access and discussion. All submissions are vetted for quality & relevance. We keep it information-first and do not support any promotions, paid or otherwise.
Let’s Dive In
TL;DR
An AI agent in production meets every formal definition of a data product. It has users, serves analytical data, needs quality monitoring, evolves through versioned schemas, and breaks silently when you ignore it.
Observability is not logging. It’s product analytics. Every conversation is a user session. Every tool call is a feature interaction. Every retry is a frustration you can measure.
Undetected errors are invisible churn. Your agent can score perfectly on generic metrics while hallucinating links, suggesting impossible actions, and losing users you’ll never hear from.
The feedback loop IS the roadmap. Manual annotation sessions, clustered by patterns, connected to tickets. Not dashboards. Decisions.
Security is a product contract, not a checklist. 4 defense layers, human-in-the-loop, and scoped permissions. A data product nobody trusts is a data product nobody uses.
Your agent can be its own onboarding tool. Enable it to explain its own features through conversation. Documentation becomes discoverability. Every “how do I...” question is a product signal.
The teams winning aren’t the ones with the best prompts. They’re the ones treating agent behavior as a continuous product input.
Disclaimer: All statements here are from a year of managing an AI companion in production at Workpath. 50+ tools, RAG, workflow memory, frontend context awareness. Not theory.
The Subtle Shift that Went Unnoticed
You shipped your agent. Observability is green. Traces are flowing. Users are chatting. But can you answer these?
What are users actually trying to do with it?
Which tools should you optimize or kill?
What feature requests are hiding in conversations you never read?
Not being able to answer any of this means you have an experiment running in production. Most teams assigned agents to ML engineers or product managers. In my opinion, they are partially right and partially wrong.
The infrastructure underneath: RAG pipelines, semantic layers, observability traces, that’s data engineering territory. And the vision on top screams product thinking.
When you realise, the work for the Data shifted into building processes that turn agent behavior into product decisions.
Your Agent Already Is a Data Product
As we can read in this post, we usually describe data products as assets that stakeholders should be able to discover, access, trust, and interact with in a secure fashion.
You can’t carry that vision without observability, clean architectures, and proactive quality monitoring. Let’s see how your AI Agent can fit conceptually in this definition:
A data product has users, quality contracts, a lifecycle, and evolves based on feedback. Your agent has all of that. The question is whether you’re treating it that way.
AI Observability Is Product Analytics
Most teams connect to Opik or Langfuse and call it done. But that’s just logging. Product analytics is a different ballgame. It answers: What should I build next? Where should I put my focus?
Every conversation is a user session.
When I started reading conversations manually at Workpath, I found users hacking the agent for use cases we never designed. 50% wanted bulk operations we didn’t support, and others were asking for exports that didn’t exist.
None of this showed up in any dashboard. The tools were not raising errors because everything was failing successfully.
Every tool call is a feature interaction.
We had 50 tools. Users called 5 regularly. Some tools were ghosts because the agent decided to never use them. Others had high usage but huge failure rates.
That’s a product prioritization alert: fix the broken popular ones, kill the unused ones, and merge the ones that always get called together.
Every retry is a measurable frustration.
When a user rephrases the same question three times, that’s friction instead of a “conversation.”
When they abandon after “I can’t help with that,” that’s churn.
When they ask for something five times and give up, that’s a feature request screaming right at your face.
Stop evaluating agents on correctness scores. Start evaluating them on what users are trying to do and whether the agent helps them get there.
Undetected Errors Are Invisible Churn
My agent had perfect hallucination scores. Then I started reading conversations manually and found:
Agent hallucinating documentation links after fake-searching the docs
Agent inferring wrong user information and making incorrect tool calls
Agent suggesting follow-up actions that literally didn’t exist
Generic metrics (e.g., Hallucination, AnswerRelevance, ContextPrecision) are too abstract to catch this. They tell you something is “good” or “bad” without telling you what to fix.
What works
Binary evaluation criteria specific to your use case. “Did the agent call search_knowledge before citing a URL? Does the URL in the response match the tool output?”
Run it with LLM-as-Judge ten times, and you get the same answer. And if you want a bulletproof validation, ask different colleagues in your company. That’s testable.
Those undetected bugs are signals about what your agent promises and can’t deliver. Each one is either a ticket to fix something or a scope clarification for what the agent should and shouldn’t do.
A data product that fails silently is worse than one that fails loudly. At least loud failures get tickets.
Security as a Product Contract
Security isn’t a checklist you bolt on before launch. For a data product, trustworthiness is a foundational property. If users don’t trust the product, they stop using it.
Your agent accepts natural language from anyone. That’s the largest attack surface in your product. I wrote an entire series on building jailbreak-proof AI agents, and the core idea is defense in depth across 4 layers:
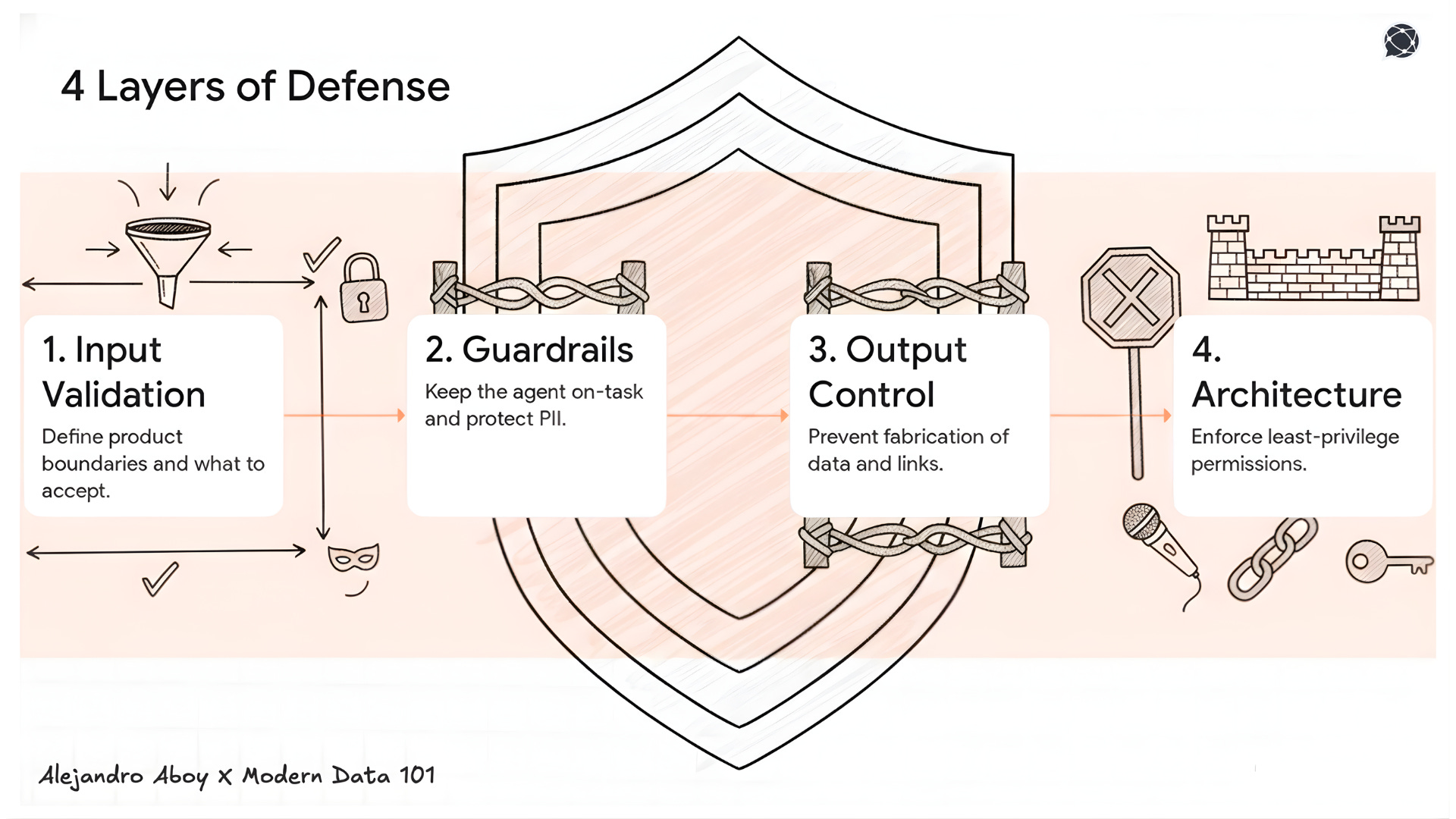
Input validation is a product boundary definition. You’re deciding what your agent will and won’t accept.
Guardrails are a scope definition. Topical guardrails keep the agent on-task. PII masking isn’t compliance is built-in trust. Users need to know their data isn’t leaking into responses.
Output control prevents the agent from fabricating data that looks real. Structured outputs are the difference between an agent that invents a documentation link and one that only cites what it actually found.
Architecture is where engineering meets product. Least privilege, scoped tools, observability. An agent can’t drop your production table if it doesn’t have permissions.
Then there’s human-in-the-loop. I’ve been evaluating Safety Operations to see if my agents comply with asking users before destructive operations. The agent asking, “Are you sure you want to delete this?” is good UX. It also happens to be good security.
A data product nobody trusts is a data product nobody uses. Security failures don’t show up in your dashboards. They show up as undetected churn.
Teaching Your Agent What It Can Do
Discoverability is the first data product property we listed. Traditional data products have catalogs. AI agents have something better: they can explain themselves through conversation.
Users don’t read documentation. Savvy ones ask the agent, “What can you do?” and if the answer is vague, you lose them before they even try the feature they came for.
At Workpath, we enabled Zendesk knowledge base articles as a RAG source. When users ask “how do I create a goal?” or “what can you help me with?”, the agent searches those articles and explains features, workflows, and guidance in conversation. The agent seeks to teach users on demand.
The agent becomes its own onboarding tool, and its knowledge base becomes a living source.
Instead of static docs nobody reads, you have a conversational interface that meets users where they are and explains exactly what they need.
Track those patterns and find discoverability signals you can leverage. If the agent can’t explain a feature clearly, either the knowledge base article is bad, or the feature itself is poorly designed.
Every “how do I...” question is a product signal about what’s confusing, what’s undocumented, and what users actually want to use.
The Feedback Loop Becomes the Roadmap
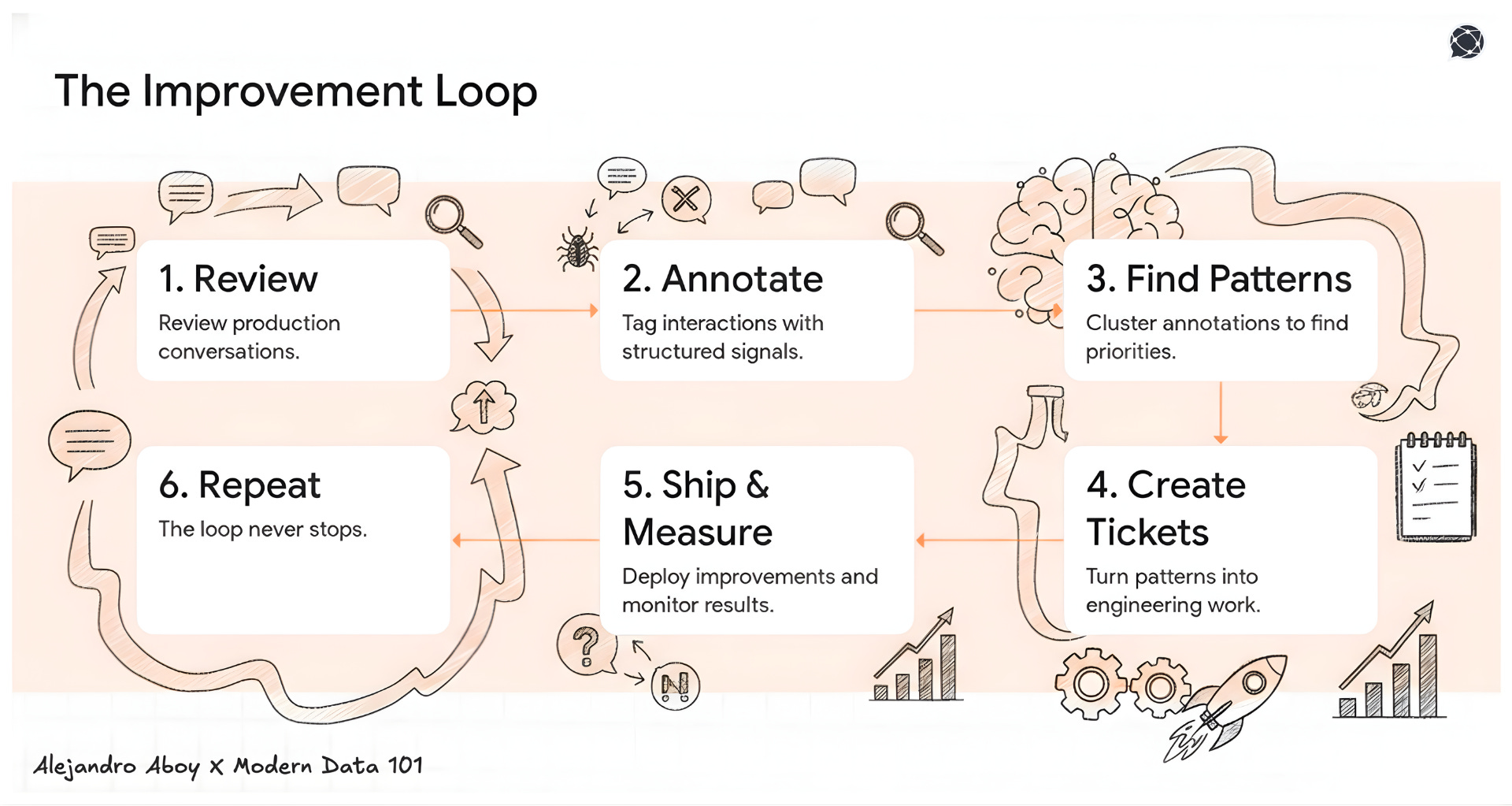
The process I developed after 1000+ manual (yes, 1 by 1) conversation reviews:
Before each annotation session, prepare. Look for anomalies to pick up outliers, such as latency, too many tool calls, long-lasting conversations, and high token consumptions. Don’t read “some chats” and call it a day.
During annotation, collect structured signals. Is this a bug? A missing feature? A scope violation? A prompt gap? Each annotation should map to an action type, not just a thumbs-up or thumbs-down.
After annotation, materialize the roadmap. Connect patterns to JIRA tickets. Update documentation. Cross-reference against the backlog to validate if the most concerning patterns are already being considered.
I started generating a bunch of GitHub PRs just by reading conversations, taking notes, and applying those annotations as Claude Code plans.
None of these came from user interviews. None came from JIRA. They came from reading what users actually did with the product.
The loop: Conversations → Structured Annotation → Clustered Patterns → Tickets → Ship → Measure → Repeat
This is Product management powered by production data (and AI). And it never stops because users never stop talking to your agent.
Final Words
A robust data product encodes business meaning, enforces quality, traces change, and supports continuous evolution. It earns trust through security. And it teaches users what it can do instead of waiting for them to figure it out.
I haven’t seen a moment like this in my career, where users are telling you what to build next through every single conversation.
The teams winning at AI agents are the ones with the best feedback loops, the strongest trust contracts, and agents that know how to explain themselves.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect

Connect with Alejandro Aboy on LinkedIn 💬 | Or find more of his work on Substack:

 | A guest post by
|
Love this analogy. Thanks for the TL;DR summary. Breaks silently…and a user just leaves. Yep. Same as data. Except: in the worst possible moment they bring it up in a public forum 🫠
The boundary question is interesting - at what point does 'an agent that processes data' become a data product vs. just an automation? I'd argue the threshold is SLA: when you start treating the agent's outputs as something other teams depend on, with expectations around freshness, accuracy, and uptime, it's a data product.
The RAG + PGVector setup you mentioned from Alejandro is a good test case - if other teams are querying that output, it's a product whether or not you call it one. The ownership model that comes with that label is probably what matters most organizationally.