


Data Products: A Case Against Medallion Architecture
The Significance of Medallion, Crux of the Differences between the two 3-Tiered DataFlow Models, and a Colourful Visual Journey!



If this is going to be a case against the Medallion architecture, we need to lawyer up on both ends and make a case for Medallion first—its significance, reasons behind its emergence, impact, and why it worked or didn’t work. And don’t worry, we’ll keep the defence short so we have the stage for what’s coming.
What is the Medallion Architecture?
The name itself compactly holds a visual of the entire architecture. The Medallion Architecture was coined as a way to describe a structured approach to organising data lakes into layers of quality. The name is cleverly metaphorical, drawing from the idea of medals (like in sports) to represent increasing levels of data refinement and quality: Bronze, Silver, and Gold.
Each tier, better than the former.

Each layer is synonymised with a specific data quality expectation:
Bronze: “raw data”
Silver: “cleansed and conformed data” the data from the Bronze layer is matched, merged, conformed and cleansed "just-enough"
Gold: “curated business-level tables”
Why did the Medallion Emerge?
The Medallion Architecture emerged to quench the need of the hour. A Google or chatGPT search on why Medallion emerged would be very different from this analysis. A generic view would cite reasons like better governance, dissolving bottlenecks, or standardising processes. But it didn’t really solve those, and we’re still stuck knee-deep in these challenges. So what was the real reason behind its emergence, and what did it solve? What do we see from a 10k ft. view?
The big picture turns out to be very different.
With consistently increasing overwhelm in data teams with business data that kept expanding and growing, there was an urgent need to quench the need for apparent “ease of data management”. A way to feel that the mammoth at hand is somehow manageable.
The Medallion architecture gave data teams the ultimate psychological relief—enhancing productivity and management from a cultural point of view rather than from a tech POV: It broke the big problem into smaller parts.
While this is always the best approach—breaking down a big problem into smaller solvable units, what is also crucial is how the breaking down happens. And for Medallion, we’d like to argue that the approach itself, to split the big piece, was where the architecture went haywire.

While data management seemed more doable, with different tiers having progressively different quality expectations, each benefitting from the former, it was apparent progress without real progress. The misdirected purpose of each layer led each tier to inherently host poor data, which compounded in the next tier.
Data Products: A Case Against Medallion Architecture
Medallion equated to a misdirected bait for many organisations who needed relief from the pressure of heavy data and heavy expectations from data. No doubt, it resolved the real problems to a few degrees but ended up as three layers of bottleneck in the long run.
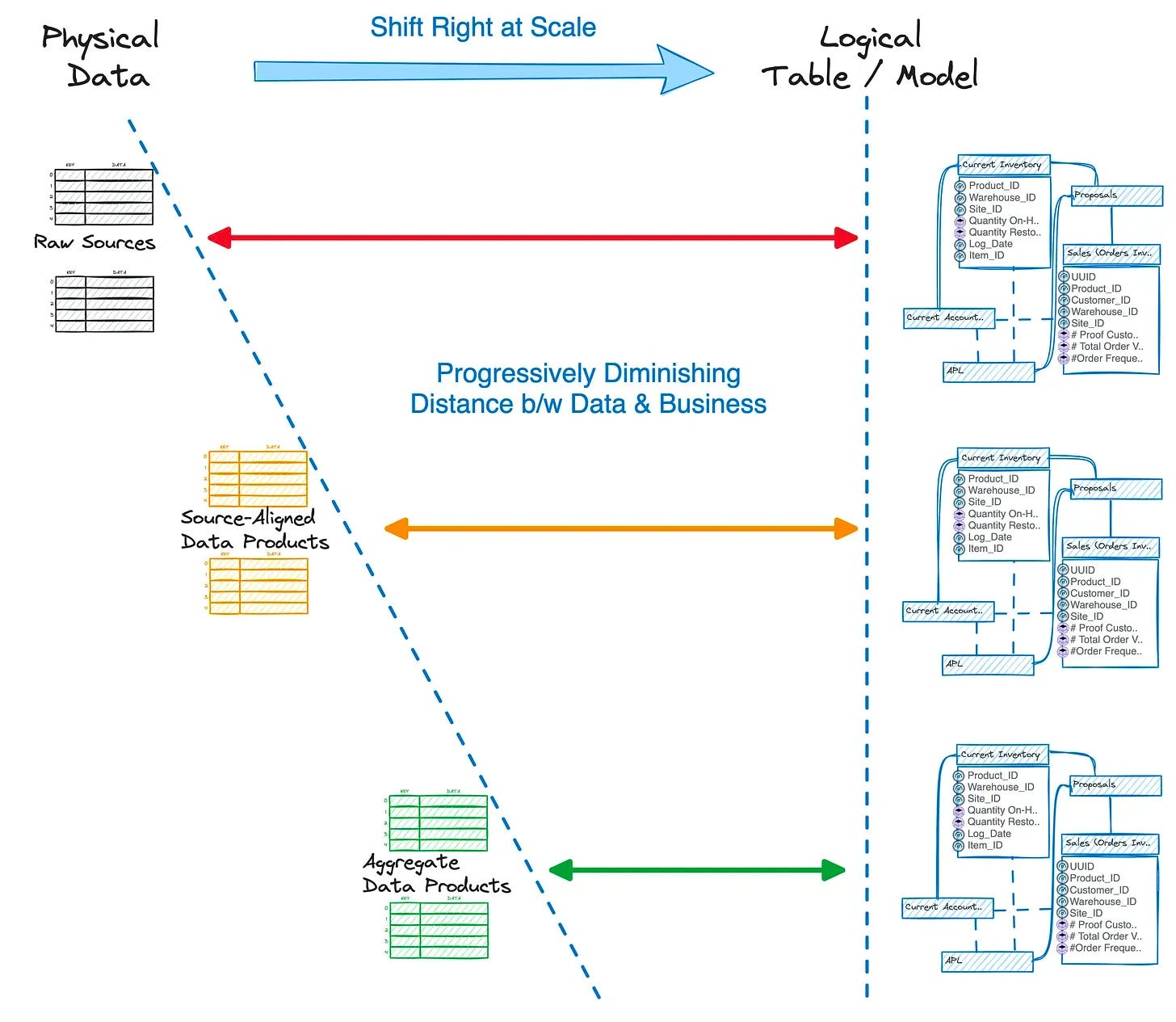
To understand how Medallion falls short of our data management expectations, we’ll use the Data Product architecture as a comparative map to dissect the case in perspective.
The Medallion Architecture: A Pull Mechanism
While the three-tier architecture is aesthetically pleasing and does divide the work across teams, it goes against the natural state of data and, in fact, obstructs the natural consumption patterns of business data.
The Bronze-Silver-Gold model enforces a strict pipeline structure that may not align with actual data needs. Not all data requires three transformation stages, yet the framework encourages unnecessary processing, leading to:
Increased latency: Data must pass through multiple layers before becoming usable.
Complexity without value: Simple transformations are forced into predefined stages rather than being optimised for specific use cases.
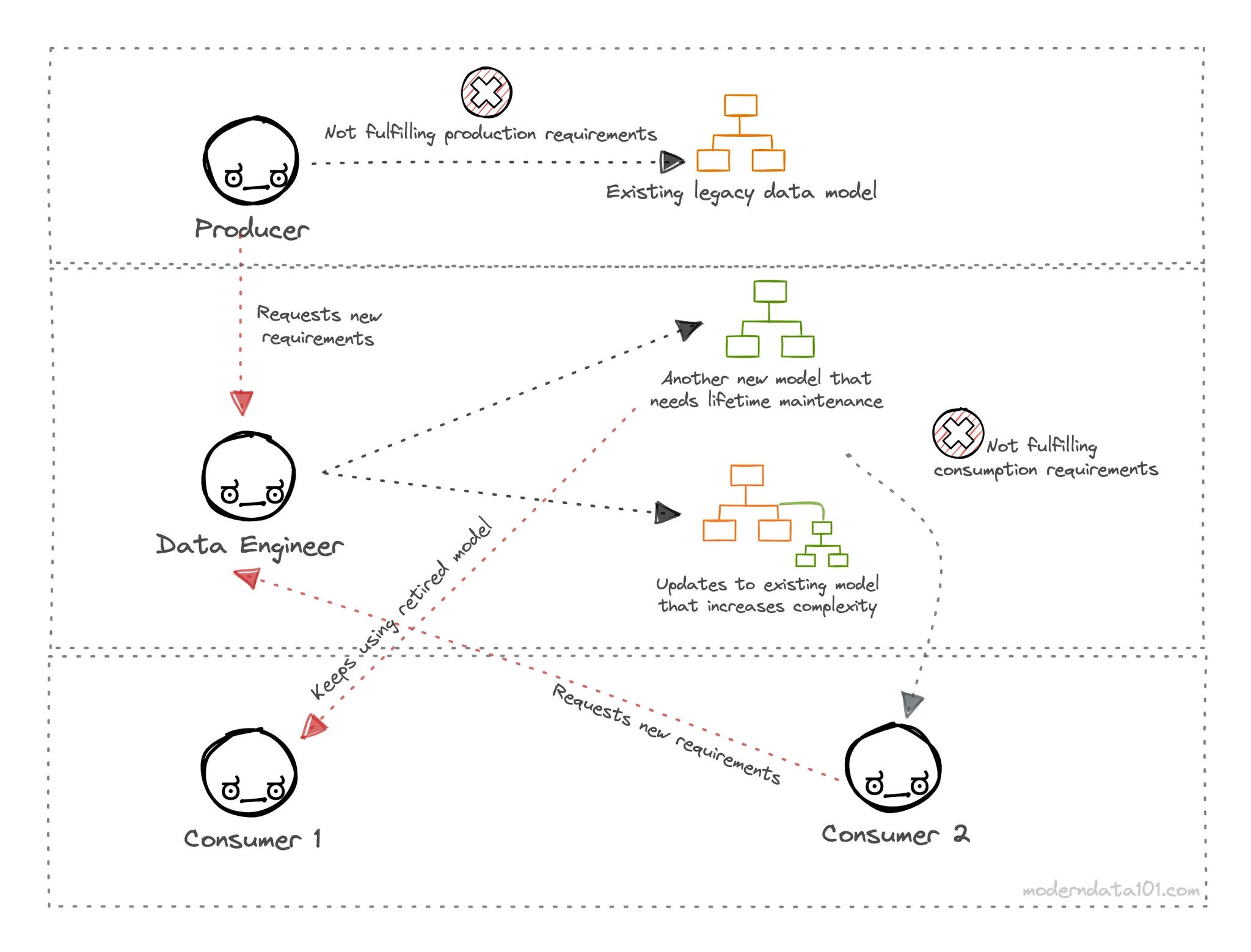
The strict pipeline structure we refer to above enforces a pull action at each border.
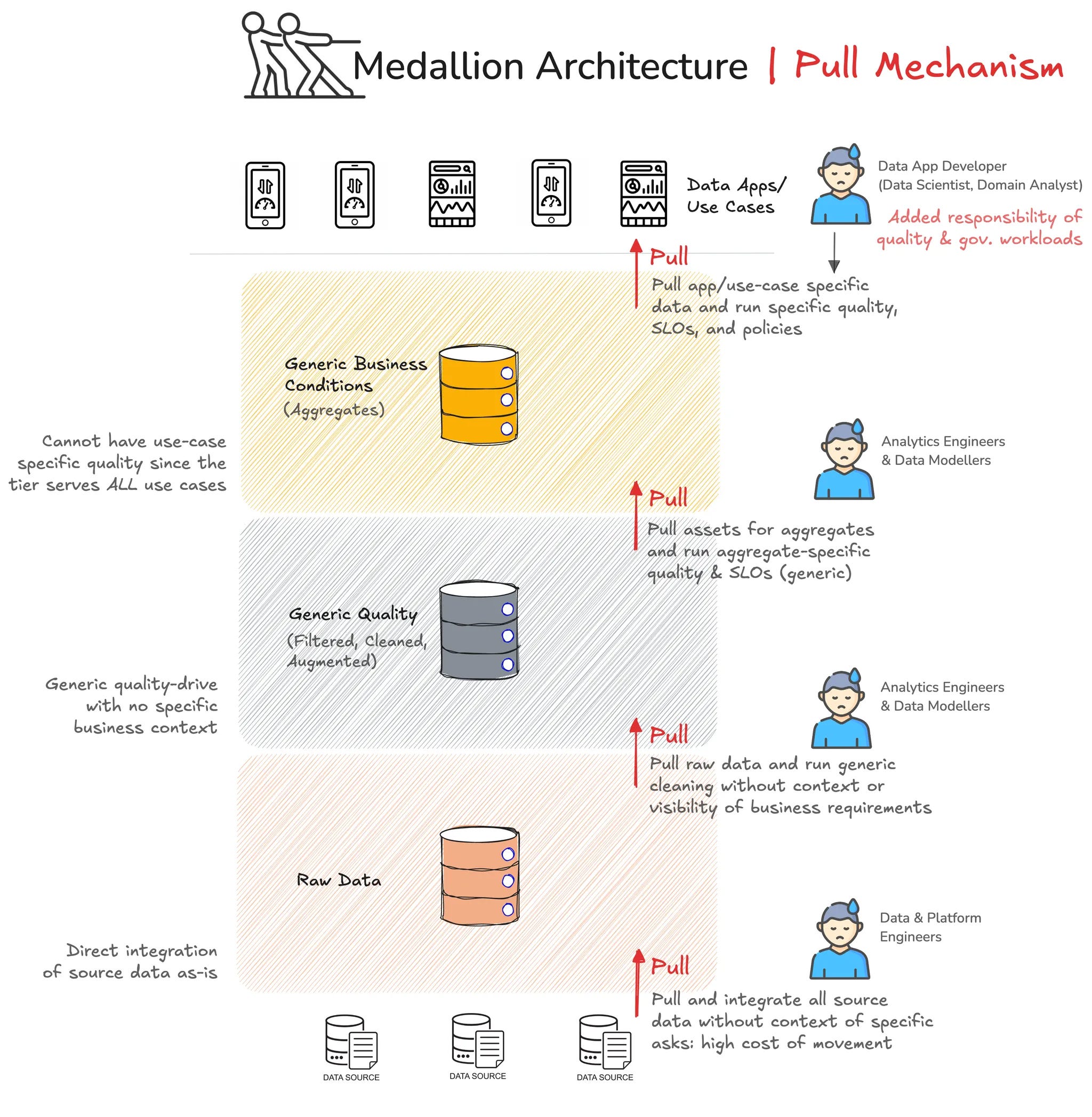
Let’s break down the visual:
The Enforced Bronze
Data Engineers are required to pull and integrate all source data into the bronze layer without the context of specific business asks. This increases the cost of data movement with higher storage and compute costs.
Increases storage costs: Storing multiple copies of data across layers inflates cloud storage expenses.
Requires extensive compute resources: Constant movement of data through layers results in unnecessary processing and query inefficiencies.
This model, in a way, enhances the profits of the developers of this architecture based on its tight coupling with traditional Lakehouse architectures. More storage and more compute end up in high billing costs in any pay-as-you-go model.
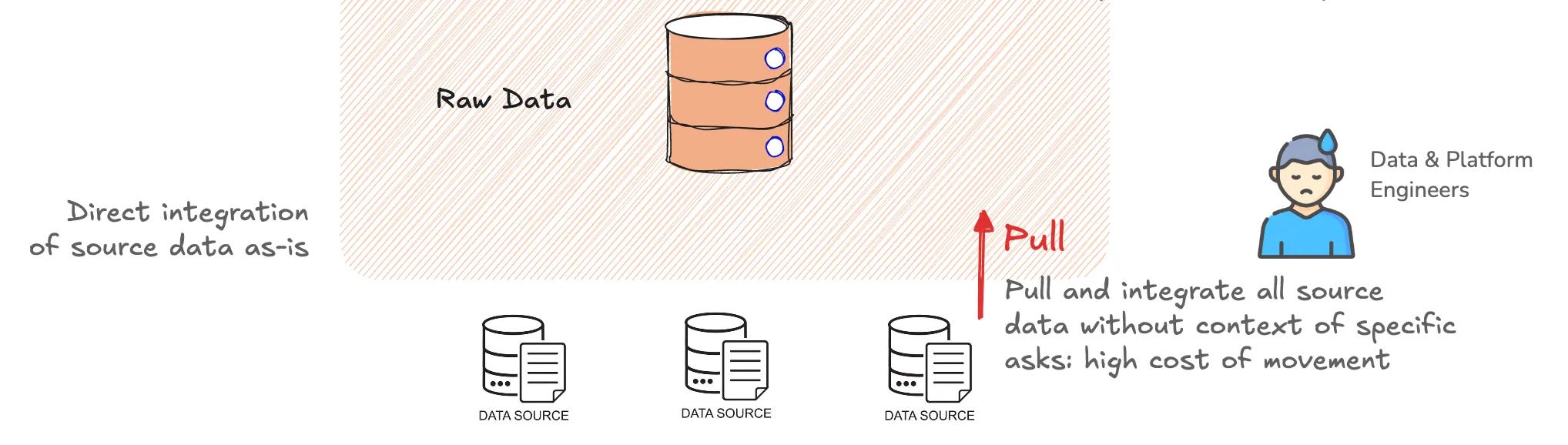
More importantly, note that no quality work is happening at this layer, but you’re essentially bringing in constantly generated data and building a heap within your Lakehouse. A heap that the engineers and business users in the downstream tiers are expected to soft through to do the real work of running quality workloads.
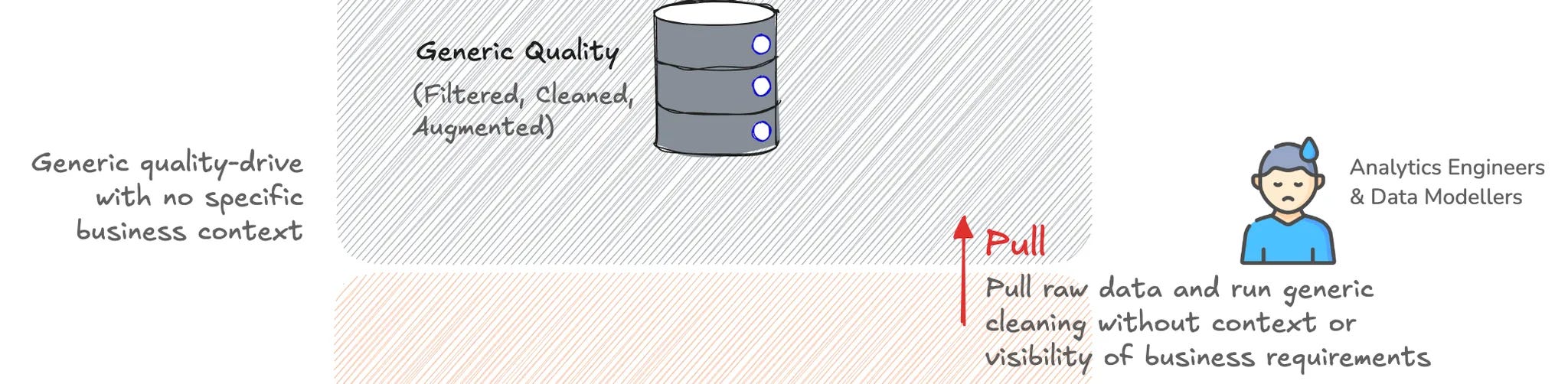
The Enforced Silver
Note how we still do not have context from actual business use cases and business users who are going to use the data. All transformations at the Silver tier are forced to be generic, be it cleaning, augmentation, or filtration.
There is no case-specific quality assessment that can happen at this layer, and consumers in the next tier (gold) are stuck with universal quality SLOs, which they are required to work on again to gain use-case-specific quality assurances.
The Enforced Gold
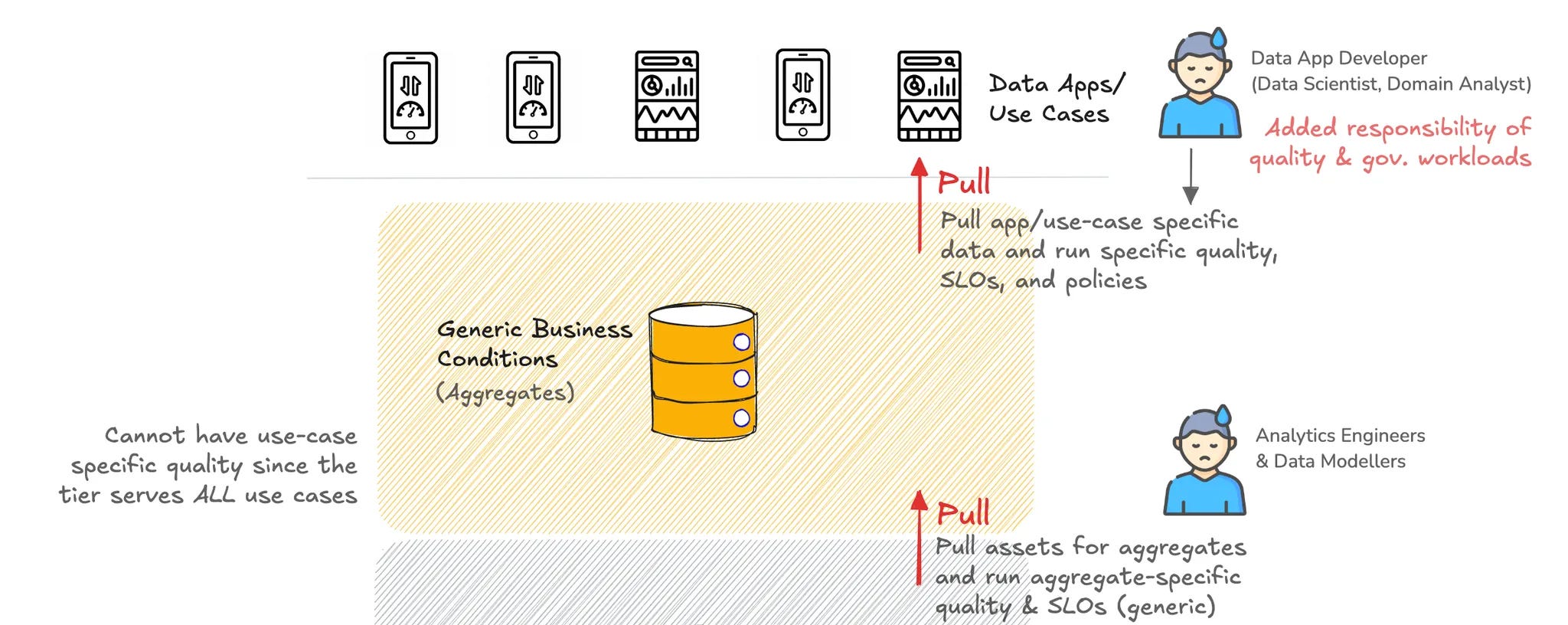
The gold tier hosts assets which are closer to businesses.
At the Gold layer, Analytics Engineers and Data Modellers are often left burning the midnight oil creating generic aggregates that business teams might end up using. It is then the responsibility of the Data Developer (who uses data in their apps) and business users (data scientist, business analyst, etc.) to pull data from the gold aggregates and run quality assessments on the same.
Essentially, the grunt work shifts to the Data Consumers and the Gold Tier is where it happens.
This is also the tier which faces the most backlash from downstream users with continuous quality and modelling requests, creating bleeding bottlenecks—because it’s a pull mechanism. Users are pulling from business aggregates that are made without their knowledge or insight.
Rather than structuring data around business domains or use cases, the Medallion Architecture categorises data purely based on its transformation stage. This forces teams to work within an artificial framework rather than aligning data to real-world processes.
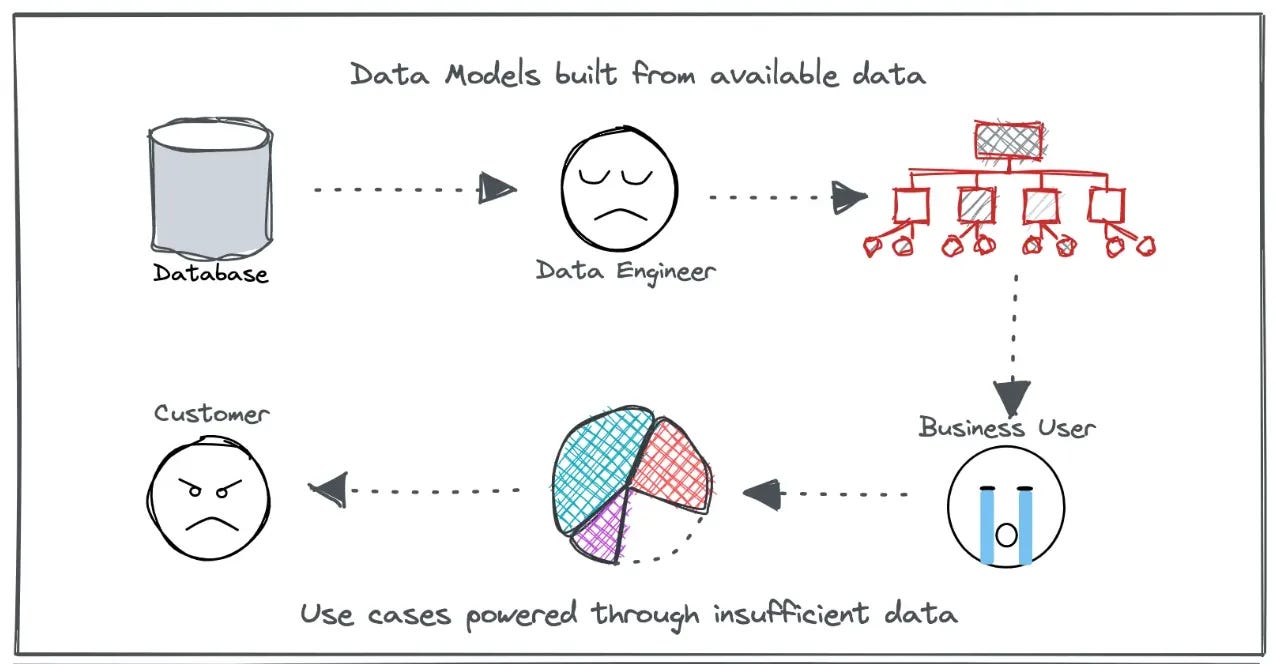
On a side note, it also ends up complicating data governance and discoverability, as lineage is tied to pipeline stages rather than business meaning.
The Product Difference: A Push Mechanism
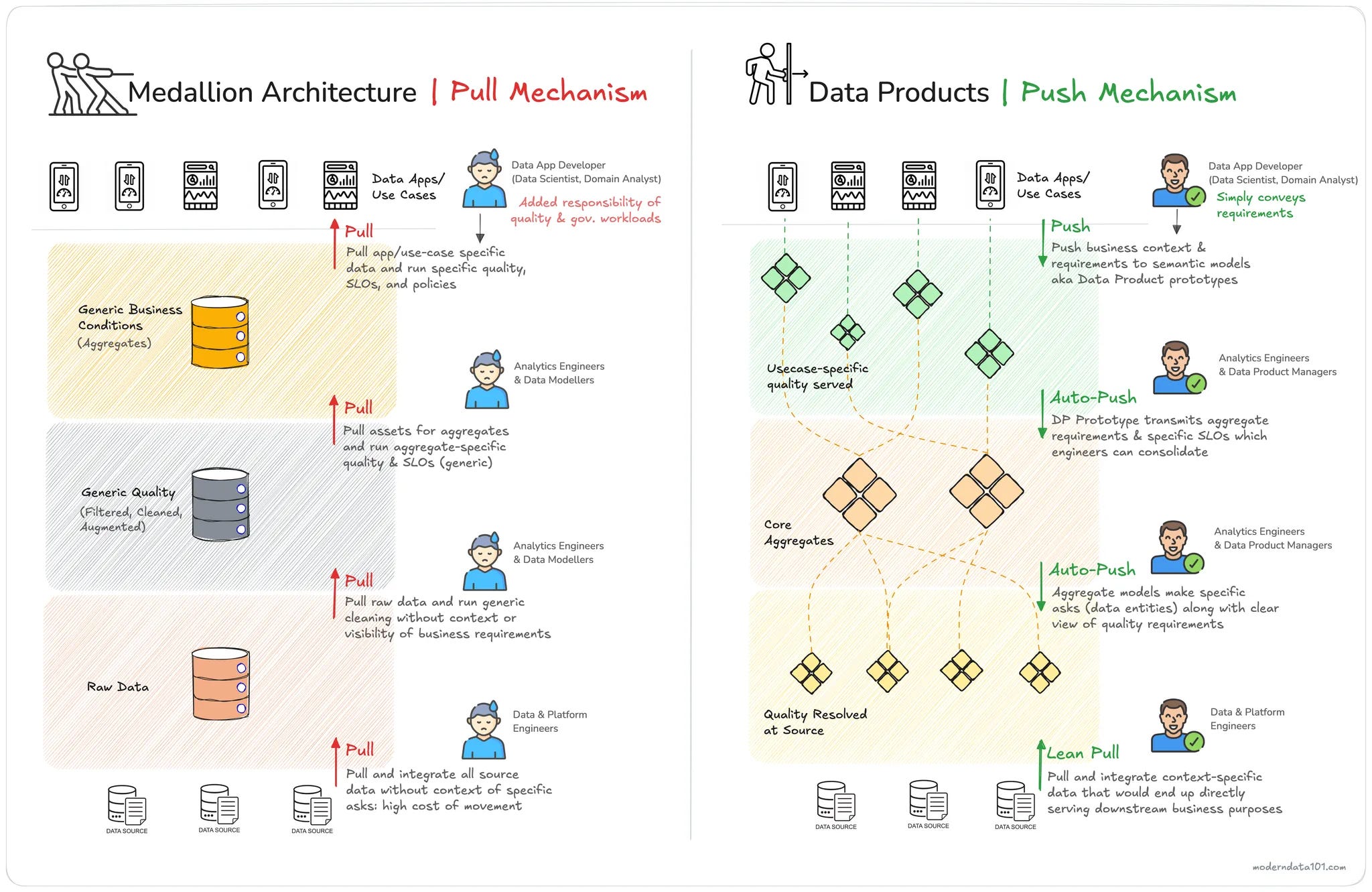
Modern data products emphasize model-first approaches, where data is shaped based on analytical and operational use cases. Medallion Architecture, in contrast, prioritizes a linear transformation flow, which treats data as an assembly line rather than a product.
The Data Product Architecture encourages a “Push Mechanism” where the first and foremost activity is pushing the business context to the far end of the upstream.
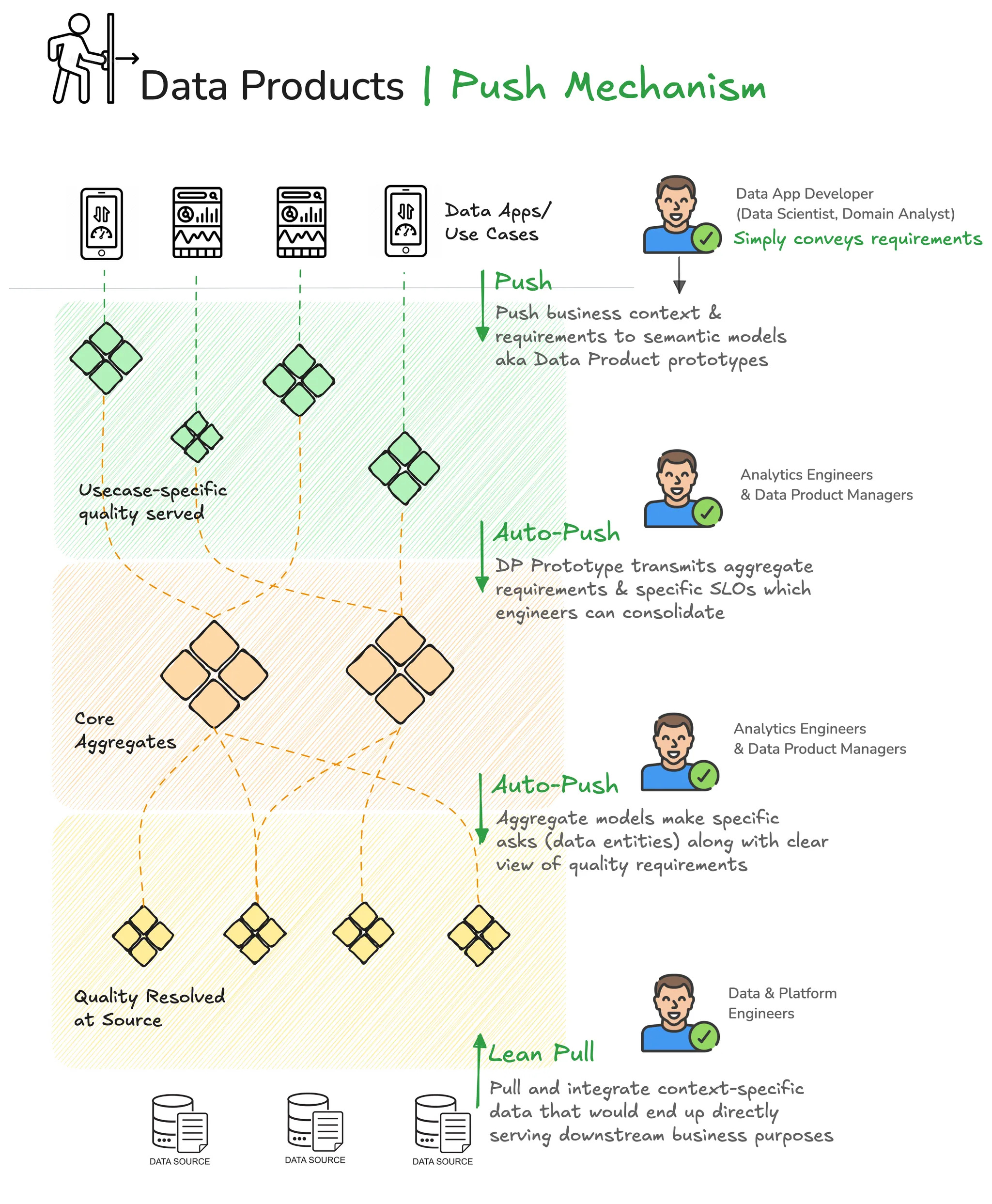
The cascading effect of data products across different layers is starkly different from that of the medallion tiers. The primary approach of splitting the big piece into different solvable units (products dispersed across layers) is where the magic happens.
The First Push: Context
The prime activity in any product-driven framework is “user input”, which translates to business context in the data product ecosystem. The downstream users working on a data use case share their requirements through, say, a business-friendly interface. This context is collated in the form of a semantic model. What are the data entities that this use case needs, how are they connected to each other, and what measures and metrics matter?
Cascading Context Push
This context is captured by the use-case-specific semantic model (this model is part of the consumer-aligned data product; we’ll see how soon). Once this context is captured, it is auto-pushed into upstream layers of products. Analytics Engineers and Data Modellers building aggregate Data Products know exactly what to collate and what quality measures to weave in to serve the downstream semantic model.
This Aggregate Data Product (also with a semantic model component) transmits the business context to the far upstream (closer to the data sources). Note how no data movement or processing has happened up to now.
Once the context reaches the source, the Data & Platform engineers have a very clear picture of what data to move and what quality workloads to run to serve the specific downstream asks. They have full clarity and visibility of what use cases the data is going to serve, what entities are necessary, and what SLOs are required on both local and global levels.
The Actual Work Happens at the Far Left!
Data Engineers are able to create a very lean-pull system where they only move data that the business needs instead of running out on storage and compute in moving all and every data generated by sources. They pull and integrate context-specific data that would end up directly serving downstream business purposes. This, as you can imagine, is an immense cost-saving boon and looks better on the Data Team’s ledger, too.
Now that context is available at the source, which includes quality and governance requirements, the data engineering team is empowered to create internal SLOs that serve source data entities (or source data products). The actual weight of the quality workloads is now borne at the source itself instead of being pushed to the far right, where the data consumer has to do the work to make the data consumable!
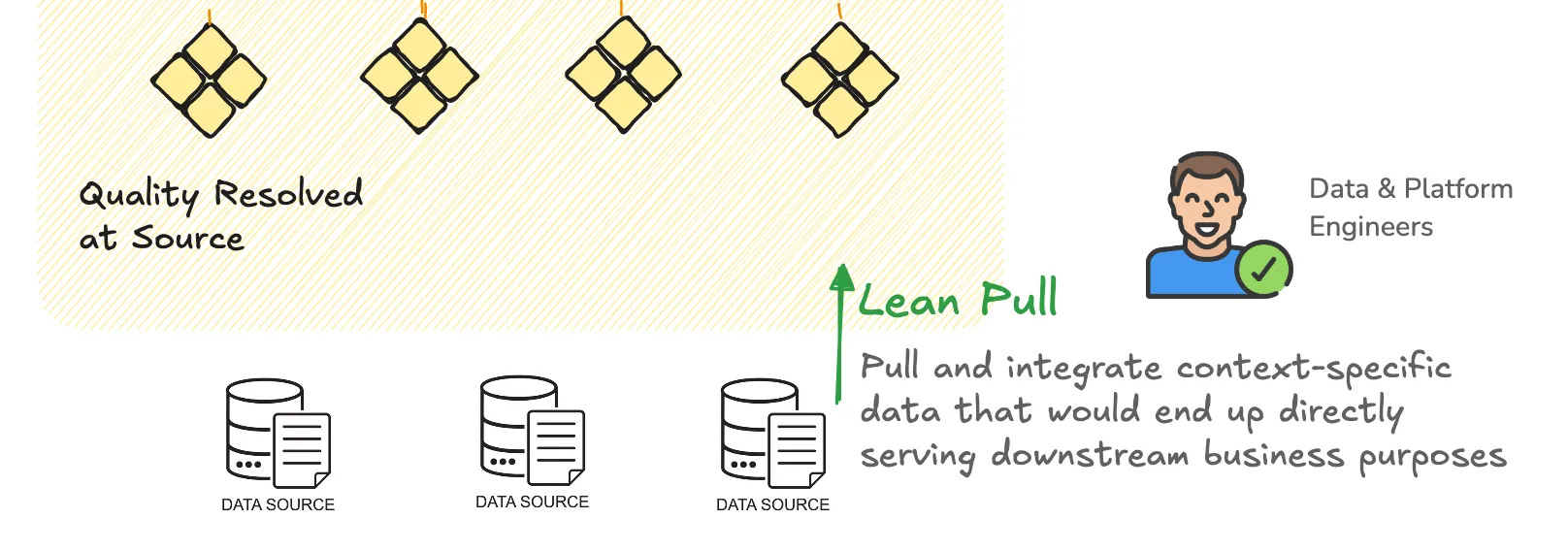
The data is productised right at the source now (purpose-driven, high-quality, and governed at source). This immediately activates the logical models downstream, enabling data consumers to leverage both Aggregate and Consumer-Aligned Data Products with the quality and experience they expected in the first place.
We’ve covered this cascading effect of context in far more detail in the guide on How Data Becomes Product. Learn more about it here ↗️
Handling Business Change
Any change request has the same lifecycle where the user just adds context to the semantic counterpart of the data product, and the same context is transmitted to the far left where the real work kickstarts and the data reaches the consumer.
It’s important to understand that this isn’t a time-heavy process, and in fact, the deployment frequency is far superior in data product ecosystems compared to traditional architectures like the medallion. This is owing to the contextual bridge that a Data Product Ecosystem enables.
A Comparative Look: The Medallion Architecture vs. Data Products. To Push or Pull?
The essence of the case is, the data stack has to be tiered in some ways, given how cultures, teams, and processes have evolved in the space. But the right form of tiering and the approach makes all the difference. One would cage you within strict boundaries, while the other gives enough flexibility to pick and choose data that matters.
Case Highlights: The Critical Arguments
In building the case against the Medallion Architecture, we based the arguments on a comparative look and the Pull vs. Push mechanisms and how each impacts the data stack and citizens across different layers. In doing so, we have lightly touched upon several critical arguments that need a dedicated mention.
A: Shifts the Grunt Work to Data Consumers!
The Medallion Architecture, with its layered approach, imposes a heavy operational burden on data consumers. With its progressive refinement process, it inherently delays access to meaningful insights while requiring downstream teams to handle complex transformations.
This model burdens data consumers (analysts, data scientists, or application developers) stuck, constantly waiting for curated data, or being forced to engineer their own transformations. This implies increased friction, duplicated efforts, and inconsistent business logic scattered across teams. Consumers receive what the upstream pipelines dictate, leaving them with little control over shaping data to their needs.
In contrast, a Data Product Architecture flips the paradigm by emphasizing Shift-Left or Right-to-Left Data Engineering. Instead of pushing partially processed data downstream and offloading transformation work on consumers, Data Products are designed as consumer-driven entities—packaged, discoverable, and reliable from the outset. By shifting the responsibility leftward (closer to where data is created and managed), organizations eliminate bottlenecks, shorten time-to-value, and provide a context-push model where consumers request and retrieve precisely what they need.
B: Compounding Quality Issues
The Medallion Architecture often compounds data quality issues rather than resolving them. Each tier introduces incremental transformations, but errors and inconsistencies that creep in early propagate unchecked across layers 🐞. Since transformations are often applied at different stages by different teams, accountability for data quality becomes fragmented. Schema drift, data mismatches, and stale or incorrect data frequently surface, requiring costly debugging and reconciliation efforts. Bugs get transmitted downstream, where data consumers must either detect and report issues (after impact) or build their own fixes (more work for the consumer).
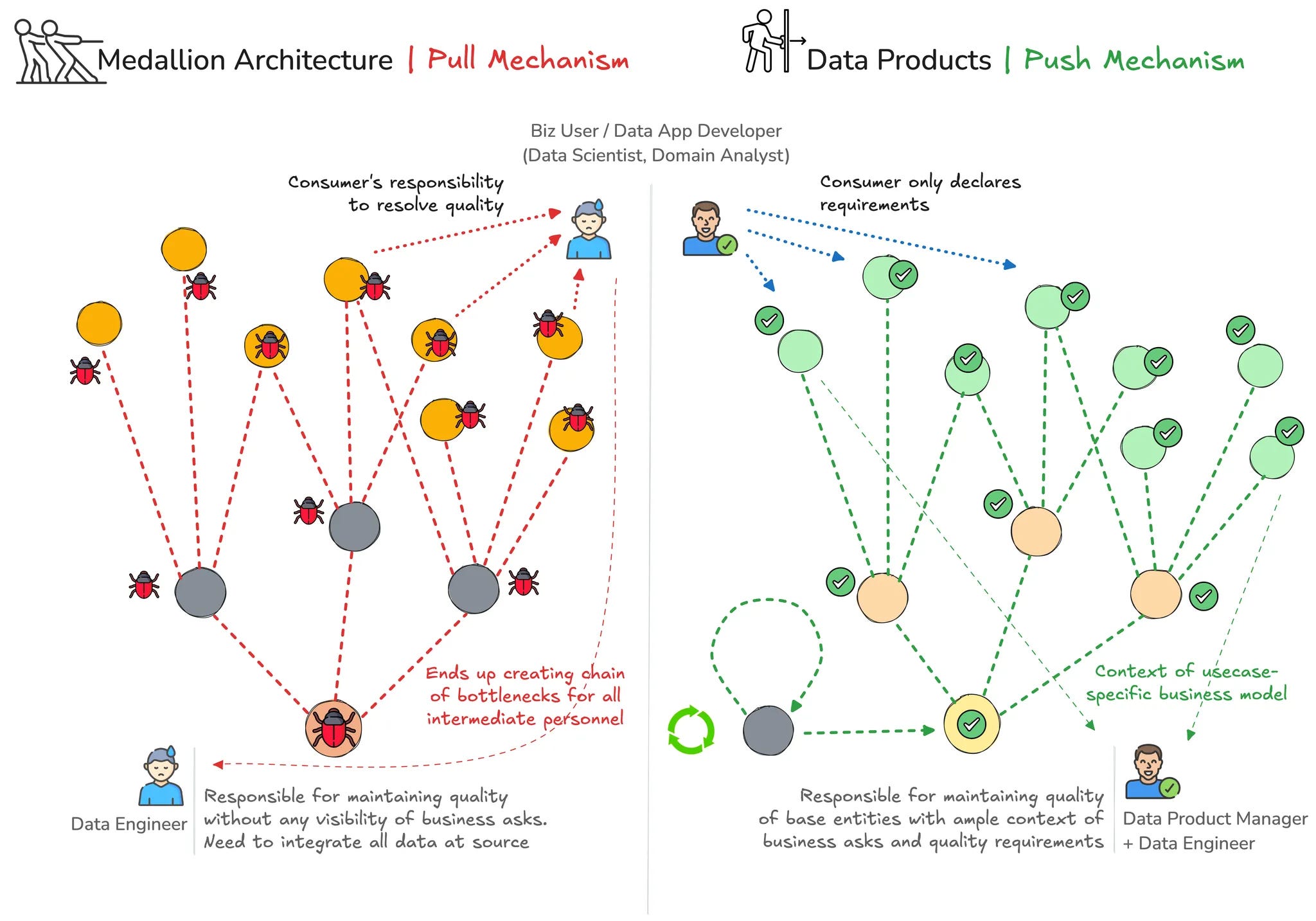
A Data Product ecosystem, on the other hand, bakes in quality from the outset, enforcing a Shift-Left approach where quality controls, validation, and governance mechanisms are embedded as early in the data lineage map as possible. By treating data as a product with well-defined SLAs, contracts, and ownership, quality is proactively maintained at the source rather than being an afterthought during consumption. Consumers only interact with high-quality, reliable data, reducing operational overhead while improving trust and usability.
C: Unnecessary Data Movement: Adding to Cost and Backlog
The excessive movement of data between different tiers adds up to high operational costs and delays. As data progresses through the Medallion tiers, it is repeatedly extracted, transformed, and loaded (ETL), resulting in redundant copies or unnecessary transformations.
This movement adds to the complexity and maintenance burden, especially when dealing with large volumes of data. The constant back-and-forth increases the risk of data becoming stale or inconsistent, amplifying technical debt. As data is moved and transformed at each stage, it builds up processing times and adds to infrastructure costs.
In contrast, a Data Product Architecture minimises unnecessary data movement by enabling decentralized, purpose-driven data movement and processing. The outcome is a minimalistic data ecosystem with data that is directly used by downstream applications or use cases. Big picture, huge savings in compute and storage at each layer where transformations are lean and aligned to specific business needs.
D: Lack of Context/Business Understanding at Upstream Tiers of Medallion
One of the fundamental shortcomings of the Medallion Architecture is the lack of business context in its upstream tiers. Since the architecture emphasizes staged refinement, data quality remains generic until the final stages. The result is a system where upstream data is often stripped of the necessary context that makes it meaningful for decision-making. Because quality assessments are conducted without a strong connection to business intent, the framework risks optimising for technical completeness rather than business relevance.
Downstream teams have to reintroduce the lost context, and by the time data reaches its intended consumers, any transformation errors or misalignments with business logic are deeply embedded. It also leads to delays in decision-making, as valuable insights are only fully realised at the Gold tier, by which time potential opportunities may have passed.
Data product thinking takes a fundamentally different approach by embedding business context as early as possible. Rather than treating raw data as an isolated asset that gradually gains meaning, data products are designed with clear intent and usability from the outset (context-push to the far upstream).
E: Limited consumption options and high-waiting queues
The rigid structure of Medallion limits consumption modes. Data consumers are forced into predefined pathways, typically batch-based tables or APIs designed for specific end-users. If a team needs data in a different format, granularity, or delivery mechanism (e.g., streaming events), they often have to wait for additional transformations or build custom workarounds. The staged refinement also introduces high waiting times for downstream consumers. Long processing queues, waiting for transformations to complete.
Data products, in contrast, are designed with native accessibility and diverse consumption patterns in mind (to fit a data consumer’s preferred consumption choices). “Output ports” ring a bell? Same data, multiple options to consume. This massively boosts data adoption into niche business processes that have native tooling and preferred modes of data consumption.
Batch, Streaming, and API-Driven Access: Data products expose multiple consumption options, allowing business users, applications, and ML models to tap into data through APIs, real-time streams, or scheduled batch exports.
Self-Service Model: Instead of waiting for upstream transformations, data consumers can interact with data products at different levels of granularity or request preferred modes of consumption based on their use case or native tool stacks.
Optimized for Event-Driven Architectures: With native streaming capabilities, data products integrate into modern event-driven systems, enabling real-time decision-making without waiting for scheduled transformations.
F: Medallion Breeds Fragile Foundations
The Medallion Architecture may seem structured, but it creates a brittle data foundation—each layer depends heavily on the previous one, meaning failures or inefficiencies cascade downstream.
In contrast, a Data Product approach prioritises strong, self-contained foundations. Instead of relying on a hierarchical transformation model, data products are designed to be reusable and self-sufficient from the start.
Final Note
Instead of Medallion Architecture:
Model-Driven Data Products: Define data structures and stacks around business models and analytical needs rather than arbitrary and fixed transformation stages.
Host a Semantic Powerhouse: Invest in understanding semantic layers, metric trees, and Data Products and how they help build a context-led data foundation.
Lakehouse with Usable Data instead of ALL Data: Reduce unnecessary layering with purpose-driven storage and processing.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 🖋️

Connect with me on LinkedIn 🙌🏻

Find me on LinkedIn 🤜🏻🤛🏻

Find me on LinkedIn 🫶🏻
From The MD101 Team 🧡
Bonus for Sticking With Us to the End!
The quarterly edition of The State of Data Products captures the evolving state of data products in the industry. The last release received a great response from the community and sparked some thoughtful conversations.
Now, with the Special Edition: 2024 Roundup, we’re taking it further, diving deep into what shaped the data product landscape in the milestone year of 2024. This edition delivers the inside scoop on Data Products and covers the entire evolution journey across the four quarters! A true yearly roundup. Fresh insights from industry leaders who are redefining what’s possible with data.

🤫 Insider Info from a Sr. Analytics Engineer
Rho is a seasoned expert in the field of analytics and data engineering, known for his deep understanding of the complexities of data modelling and architecture. With extensive experience in conceptual, logical, and physical dimensional modelling, Rho has been at the forefront of transforming data into actionable insights that drive business success.
We highly appreciate him joining the MD101 initiative and sharing his much-valued insights with us over an amazing conversation!
Championing the Customer’s Voice and More 💬 with Rho Lall | S1:E7

We added a summarised version below for those who prefer the written word, made easy for you to skim and record top insights! 📝
 |
|
I don't see medallion architecture as the culprit in this. This is all about governance, and with tools that track lineage, you can become very efficient with what you do or do not need. Data mesh is a framework built for people and processes; it is not a tool. I see the medallion as the foundation on which you apply data mesh. There are no set rules on where your users have to pull their data. ML/DS pull from silver and even bronze. Data Marts can and do pull from silver. You can also sub-divide your layers, there are no major rules. This is all predicated on how mature an organization is, and anything is better than siloed Excel sheets unless we want to try to start the "edge data architecture.".....
Great read. Although we (@ http://helloinsurance.substack.com) can see where you are coming from, in our view point we see Medallion and Data products as complementary, not competing, parts of a modern data landscape.
This diagram (https://imgur.com/a/sgnJ8HP) shows how they both coexist in an insurance context. Medallion ensures consistency and governance, while domain teams build data products with the flexibility and latency they need.
Would love to hear your take: where do you see this hybrid model working well, and where might it run into trouble?