
Context Graphs and the Future of AI Autonomy
Fundamentals, architectural extensions, and context as an use case of data operating systems.

For most of the data era, systems existed to observe. They collected, aggregated, and explained the past.
AI changes that contract. AI systems don’t just analyse data, but are required to act on it. They recommend, approve, escalate, and commit changes to the world. And the moment a system acts, analysis is no longer enough.
Action demands judgment. Jaya Gupta and Ashu Garg brilliantly summarise this premise in their groundbreaking piece on context graphs, which has, by itself, started a domino effect of clearer understanding in terms of true AI requirements.
Judgment is not a function of more rows or cleaner schemas. It emerges from context: what was known at the time, which rules applied, where exceptions were allowed, and which precedents mattered in this situation.
Without access to decision-time context, intelligence stalls at insight and never translates into autonomy.
Where existing data systems are breaking bad

The current data stack was never designed to carry judgment. Systems of record preserve state (what the world looks like now), but they overwrite the reasoning that led there.
Warehouses preserve history (how metrics changed over time), but not the intent or tradeoffs behind those changes. Knowledge graphs model relationships (how entities connect), but not how conflicts were resolved or why one path was chosen over another.
The result is a familiar gap: we can see what happened, but not why it was allowed to happen. The reasoning that turned data into action dissolves into chats, calls, and memory.
What is a Context Graph?
The anatomy of a decision
Every meaningful decision, whether made by a human or an agent, follows the same structure.
Something is evaluated: data points, signals, historical snapshots, versions of truth that existed at that moment.
Rules come into play. Policies are checked and constraints surface. Often, those rules collide, leading to conflicts and edge cases.
Exceptions are invoked, explicitly or implicitly, and authority is exercised. Someone approves and something is allowed.
Only then does an action commit, and the world changes state.
Most systems record the last step. A context graph is concerned with everything that came before it.
Defining the context graph
A context graph is not a model of entities. It is a record of decisions. Each node represents a decision made at a specific point in time. Not an object, not a metric, but a moment of judgment.
The edges carry the meaning:
the context that was evaluated
the constraints that were applied
the precedents that influenced the outcome
the authority that sanctioned the decision
the action that was ultimately committed
Over time, these decisions stitch together into a structure that shows not just what changed, but why it was permissible to change.
Relevance of context graphs in an AI-first world
Agents do not operate inside a single system. They move across boundaries, synthesising signals from many sources before acting. As they do, they must be able to explain themselves: to justify why a path was taken, why an exception was granted, why one precedent outweighed another.
They must learn not just from outcomes, but from prior judgments. And they must be governed (audited, constrained, and trusted) as their autonomy increases. None of this is possible if reasoning disappears at commit time.
Ergo, context graphs form the system of record for AI autonomy. Because they make judgment durable.
Reducing architectural ambiguity: Where context graphs?
The decision boundary
Context is not static. It does not exist before execution, and it does not survive after the fact unless it is deliberately captured. It emerges at the moment a decision is made, when inputs are assembled, policies are evaluated, conflicts surface, and an action is about to be committed.
If context is not recorded before state changes, it is lost. Once the write happens, the world moves on, and the decision-time reality can no longer be faithfully reconstructed.
This makes the decision boundary unavoidable. Context graphs must be built at execution time, not inferred later.
Why read-path systems fail
Most data systems sit downstream of action. Warehouses receive data after decisions have already been made. By the time information lands, the reasoning that shaped it has evaporated.
Metadata tools observe outcomes (schemas, lineage, usage) but not the judgment that allowed those outcomes to exist. Governance layers define rules, but they do not see how those rules were interpreted, overridden, or reconciled in real situations.
These systems can explain what happened. They cannot explain why it was allowed to happen.
A system that does not authorise writes cannot be the system of record for decisions. And without a system of record for decisions, autonomy will always be fragile, opaque, and capped.
How Data Operating Systems Architecturally Align
A data operating system is an extension of the open data developer platform (DDP) standard that aims to bring the first principles of internal developer platforms (hosting software engineering pillars) to data systems.
While the DDP standardises architectural themes, best practices, and building blocks, the data operating system implements them to the degree of available technologies of today.
A Data Developer Platform is a Unified Infrastructure Specification to abstract complex and distributed subsystems and offer a consistent outcome-first experience to non-expert end users… A DDP provides a set of tools and services to help data professionals manage and analyze data more effectively. (learn more at source)
In analogy to IDP, a DDP is designed to provide data professionals with a set of building blocks that they can use to build data products, services, and data applications more quickly and efficiently.
Decomposition by planes
Control plane = Decision authority
The control plane is where decisions are authorised, instead of just being executed. It centralises orchestration, determines execution order, evaluates policy, and resolves dependencies before any action is taken.
This is also where metadata is naturally emitted. Not as an afterthought, but as a byproduct of deciding what is allowed to happen next. In other words, the control plane already operates at the moment where context is richest and stakes are highest.

As you can observe, the control plane also hosts the heart of the system: the orchestration unit.
The orchestration unit is the only layer that simultaneously sees:
Inputs as they exist at execution time
Policies as they are evaluated, not declared
Dependencies as they are resolved, not documented
Alternatives as they are rejected
Exceptions as they are invoked
This makes orchestration the point of maximum context density.
A context graph can only be constructed where decisions are made, not where results are observed. The orchestration layer already performs this work implicitly. It chooses paths, enforces rules, and authorises transitions.
By emitting these choices as structured events, orchestration becomes the natural producer of a context graph:
Each orchestration step → decision node
Each dependency resolution → an edge
Each policy check → a constraint record
Each override → a precedent
In effect, the control plane does not integrate with a context graph. It is the context graph in motion. Orchestration turns execution into evidence.
Development plane = Intent formalisation
Intent does not exist at runtime unless it is formalised upstream. The development plane captures intent declaratively: what should happen, under which constraints, and toward which goals.
This intent is versioned, explicit, and reviewable. It encodes purpose before execution ever begins. Without this plane, decisions collapse into scripts. With it, decisions become explainable.
Data activation plane = State mutation
This is where decisions touch reality. Actions are executed, writes occur, and systems of record are mutated. Once this plane is crossed, context must already be locked in. Any reasoning that happens after this point is post-rationalisation.
The data operating system already defines a natural decision boundary.
It separates intent, authority, and impact: exactly the conditions required for a context graph to exist as a first-class system, not a derived artefact.
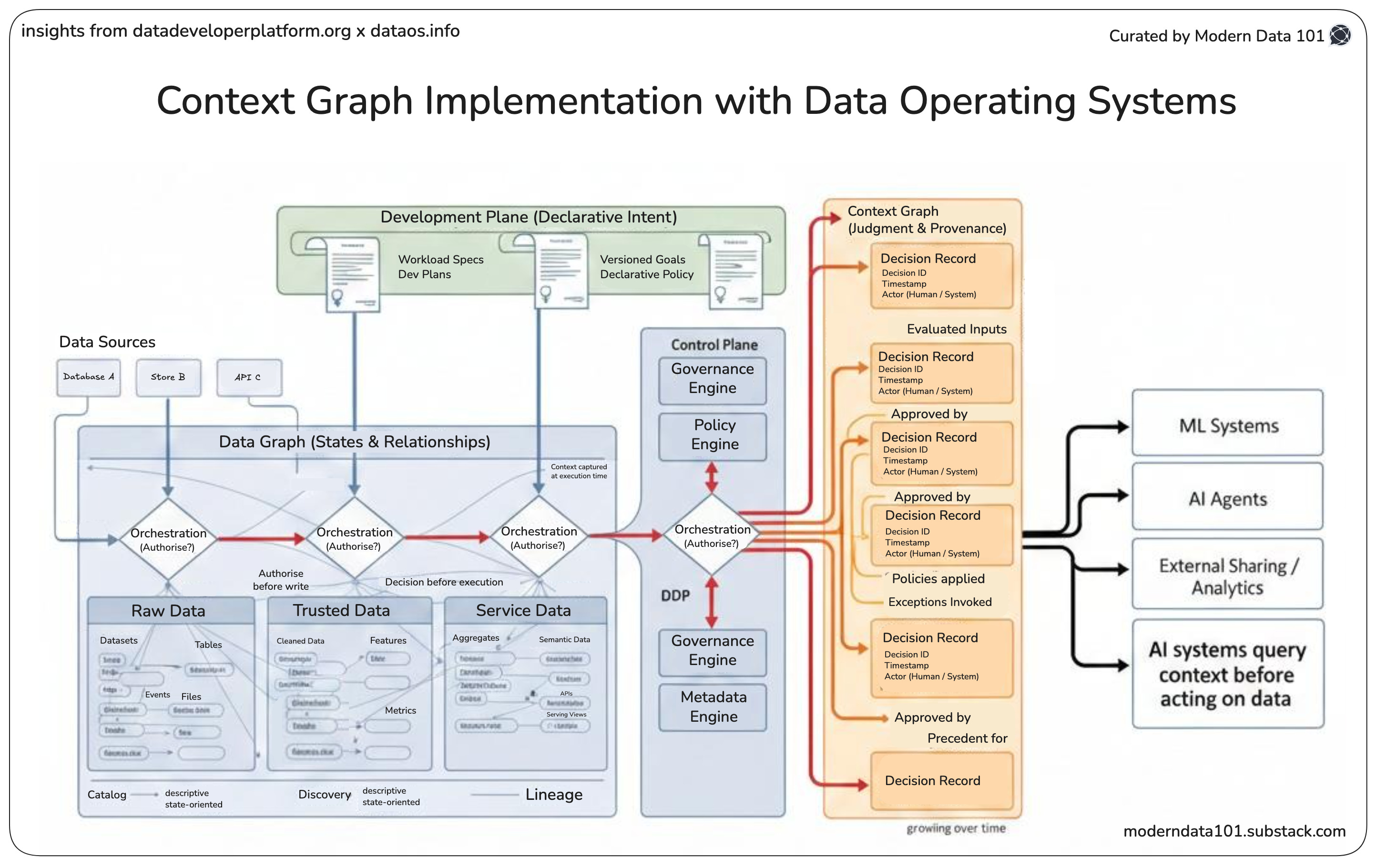
Extending DDP with Decision-trace Awareness
Decision-trace awareness is the ability of a system to capture judgment at the moment it is exercised, not after outcomes are observed.
More thoroughly, decision-trace awareness means the system does not just record what happened, but preserves why a particular path was chosen over all other possible paths.
It is the explicit recording of:
the inputs that were visible at decision time
the rules and policies that were evaluated
the conflicts that were detected
the exceptions or overrides that were invoked
the authority under which the decision was made
the precedent that influenced the choice
Crucially, this trace is captured before state mutation, while context is still intact. Without decision-trace awareness, systems can explain outcomes only retrospectively.
With it, systems can justify actions natively.
What decision-trace awareness adds
Each decision becomes a first-class resource instead of an inferred artefact.
Most critically, decisions are linked to prior decisions, establishing precedent, not just provenance. This is how systems begin to remember why something was allowed to happen.
Resulting evolution
This is not an incremental enhancement. It is a categorical shift.
Metadata graph → Context graph
Orchestration → Judgment capture
Automation → Accountable autonomy
When decision traces are explicit, autonomy stops being opaque. It becomes inspectable, governable, and improvable by design.
The Long-term Landscape, If You Plan to Stick
Today’s systems are built to optimise for recording outcomes. They are exceptionally good at telling us what happened, when it happened, and where it landed. But they are structurally blind to the moment that matters most: the instant a choice is made.
Decisions collapse into execution, and reasoning evaporates as soon as state is mutated. This is the current state: efficient, automated, and fundamentally forgetful.
Because judgment is not captured, it cannot accumulate. Each decision is treated as an isolated event rather than part of a continuum. Automation does not learn from itself, just repeats patterns encoded elsewhere.
Introducing decision-trace awareness changes the unit of value from outcome to judgment. When systems capture the context, constraints, and authority behind each action at decision time, reasoning becomes durable.
A single decision no longer disappears after execution, but becomes a reference point. Over time, these references form precedent. This is the transition point from automation as execution to automation as judgment. As precedents accumulate, future decisions improve. The system begins to recognise familiar conditions, validated exceptions, and historically safe paths.
In the long term, this compounding effect produces a qualitatively different system. Not one that runs workflows faster, but one that encodes how the organisation thinks.
Judgment becomes a first-class asset.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect

Find me on LinkedIn 🤝🏻
From MD101 team 🧡
🧡 The Catalyst: State of Data Products
Introducing The Catalyst, a special edition of The State of Data Products that compiles insights around the ups and downs in the data and AI arena that fast-tracked change, innovation, and impact.
📘 The Catalyst, first release is our annual wrap-up that compiles the most interesting moments of 2025 in terms of developments in AI & data products, with expert insights from across the industry!
Some focal topics
The gap in AI readiness for enterprises
The shift towards context engineering
Addressing governance debt with a focus on lineage gaps
Revisiting fundamentals for better alignment b/w business vision and AI.

Excellent post
I’ve reached a similar conclusion, Travis, particularly for AI-enabled workflows that require a modicum of logic and reasoning. Claude Opus is deceptive in its output; it makes the user think it has reasoned, but it’s just semantic acrobatics.
This is particularly troubling for research, where theory and hypotheses need to be logically connected to source documentation with high fidelity. I’m contemplating setting up an ontology layer to make the reasoning links explicit, and then having Claude Code run queries over the graph (as opposed to having Claude parse text). Curious if you think this approach would work and if you can point me to successful case studies.