
AI-Ready Data vs. Analytics-Ready Data
Identifiers of "ready," data consumption patterns, maturity paths, and possibilities of "upgrading" from Analytics-ready states to AI-ready states.

Before we dive in, we want to take a moment to thank you for being here with us as we step into 2026! The Modern Data 101 community exists because of your curiosity, your ideas, and your willingness to think more deeply about data. We’ll continue to share the best resources, emerging ideas, and important pivots shaping the modern data world, and we hope you’ll stay with us not just through 2026 but for many years to come.
A Very Happy New Year! 🥂

Now, Let’s Dive In!
Before we talk about modern data, or AI-ready data, we have to step back and ask a much older question: what is data fundamentally for? Strip away the platforms, the pipelines, the dashboards, and the acronyms, and data resolves into something far simpler. Data exists to
reduce uncertainty,
support decisions,
and ultimately enable action.
Everything else we build on top of it is secondary.
If the goal changes, the properties of the data must change as well.
Data is not inherently “good” or “bad” in isolation. It is only good relative to the problem it is meant to solve. Reusing the same shape of data for fundamentally different goals is not efficiency but category error.
Which brings us to the only question that actually matters: what kind of uncertainty are we trying to reduce?
The moment that answer changes, the meaning of readiness changes with it. And that is where the divergence between analytics-ready data and AI-ready data begins.
What does ‘ready’ mean
The word “ready” sounds deceptively simple. But ready for whom? Ready for what? Data readiness is often spoken about as if it were a universal state: something data either is or isn’t.
In reality, “ready” has no meaning unless we first define the context in which the data is meant to operate.
To understand readiness, we have to decompose it.
Who is consuming the data?
How is it being consumed?
What kinds of decisions does it exist to support?
And perhaps most importantly, what does failure look like when it gets things wrong?
These questions are rarely asked together, yet they determine the entire shape of the data underneath.
Once you break the problem down this way, the illusion dissolves.
Analytics-ready data and AI-ready data are not two maturity levels of the same thing. They are optimised for entirely different consumers and punished by entirely different failure modes.
And that is why treating them as interchangeable is not just imprecise, but fundamentally wrong.
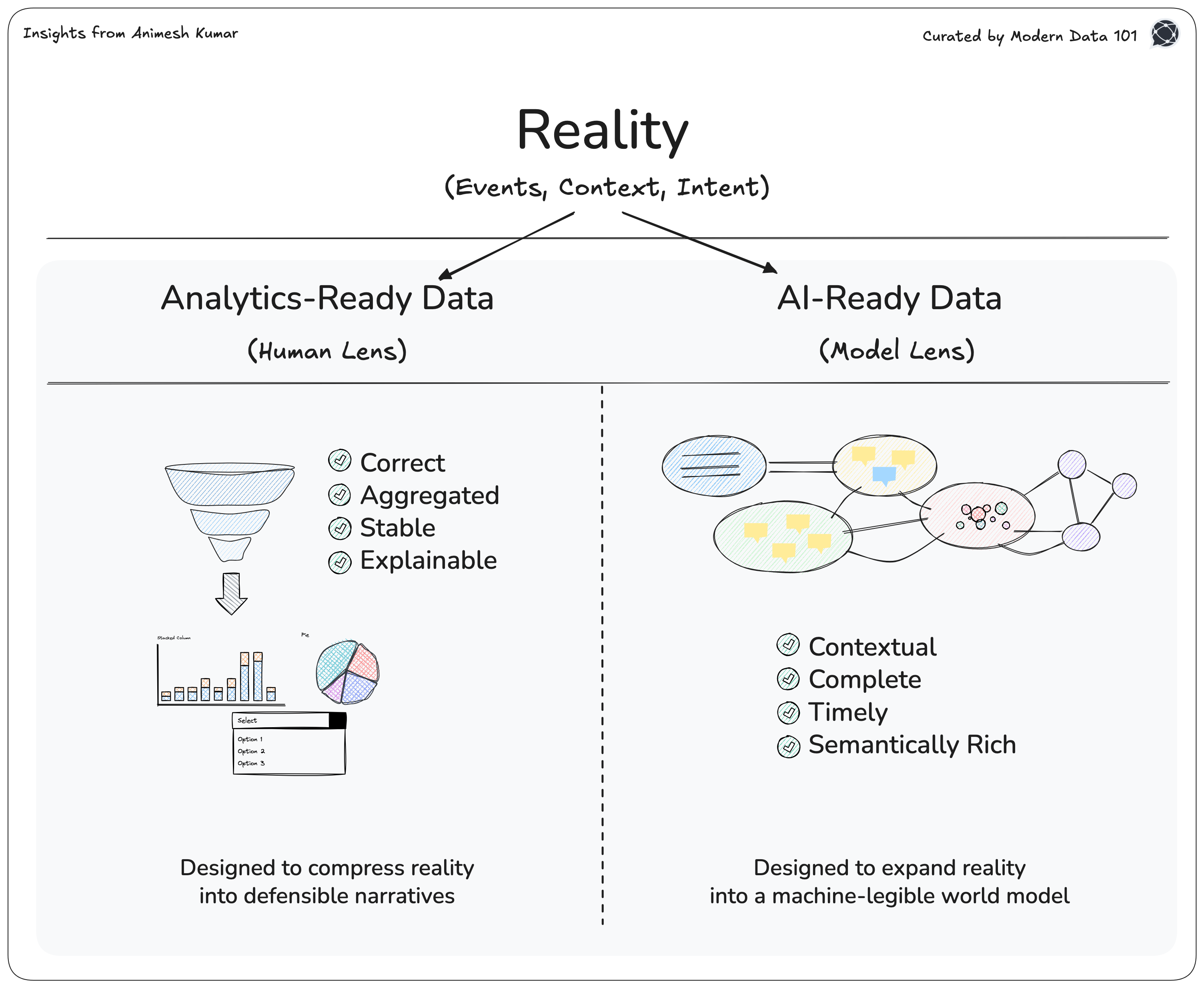
Decomposing Analytics-Ready Data
Who consumes Analytics-Ready Data
Analytics-ready data is shaped around a very specific kind of consumer: humans.
How is Analytics-Ready Data Consumed
Analysts, leaders, and operators interact with data through dashboards, reports, and queries to orient themselves. The data is there to explain, summarise, and stabilise reality so decisions can be made with confidence.
What does “good” look like for Analytics-Ready Data?
Because humans consume analytics data, “good” takes on a particular meaning. The data must be correct, aggregated, and stable. It must be explainable, not just in numbers but in narrative: something a human can interrogate, defend, and trust.
Correctness: Humans use analytics data to justify decisions to themselves, to their teams, and to the organisation. If the data is wrong, even occasionally, trust collapses faster than insight is gained. A human can forgive missing data, but they rarely forgive incorrect data.
Aggregation: Humans reason through patterns, summaries, and abstractions. Aggregation reduces cognitive load by compressing millions of data points into something the human brain can hold, compare, and discuss. Without aggregation, data overwhelms instead of informing.
Stability: Because humans seek continuity. Decisions are rarely made once. They are revisited, defended, and re-examined over time. If the same metric tells a different story every week without a clear reason, confidence disappears. Stable data creates a shared reference point and a fixed map of reality that allows organisations to align.
Explainable: Humans need reasoning to believe and trust. They need to trace a number back to its logic, source, and assumptions. Explainability is what allows data to be debated, trusted, and ultimately acted upon.
Together, these properties reflect a simple truth: analytics-ready data is designed not just to inform humans, but to work with how humans think, argue, and decide.
Analytics-ready data is not trying to imagine the future or explore the unknown. Its job is far more straightforward and far more disciplined.
At its core, analytics-ready data answers one question, and it answers it well: what happened?
Decomposing AI-Ready Data
Who consumes AI-Ready Data
AI-ready data is built for a very different kind of consumer. The consumer here is not a human analyst, but a model: LLMs, machine learning systems, and increasingly, autonomous agents.
How is AI-Ready Data Consumed
These systems do not read dashboards or interpret charts. They consume data as tokens, embeddings, features, and context windows, and they reason statistically rather than intuitively.
What does “good” look like for AI-Ready Data?
Because models consume data differently, “good” means something fundamentally different.
Context: There is no way for models to experience the world, they must always infer it. Without sufficient surrounding context, like historical state, user intent, environmental conditions, and system constraints, models are forced to guess (popularly known as “hallucinate”). And when models guess, they do so confidently.
Completeness: Unlike humans, models cannot pause and ask for clarification or fill in gaps with judgment. Missing data is not interpreted as uncertainty but treated as absence. This leads to brittle outputs that appear coherent but are logically incomplete. Complete data gives models the full boundary of the problem space they are expected to operate within.
Timeliness: An AI system trained or prompted on stale data is reasoning about a world that no longer exists. In dynamic systems, yesterday’s truth becomes today’s liability. Fresh data anchors model behaviour to current reality, reducing drift between what the model believes and what is actually happening.
Semantically rich: Models do not understand meaning unless meaning is explicitly encoded. Relationships, hierarchies, intent, and constraints must be expressed in the data itself. Semantic richness is what allows models to distinguish between similar-looking signals and reason correctly across domains, rather than hallucinating connections that were never there.
Together, these properties reflect how AI systems are NOT intuitive. They are literal, probabilistic, and unforgiving. AI-ready data is not about making data elegant but about making reality legible to a machine in machine language.
As a result, AI data systems are optimised for very different properties.
At its core, AI-ready data is not trying to explain the past. It exists to answer a different question entirely: what should happen next?
Necessity to Solve Each Problem Independently
The mistake most teams make is trying to force a single solution onto two fundamentally different needs.
If the data works for dashboards, the assumption is that it should work for AI as well. While this feels efficient, it is the complete opposite and traps teams with long and unsuccessful sprints, and ultimately failed AI projects.
Analytics systems and AI systems are doing opposite things.
Analytics exists to compress reality. To summarise, aggregate, and smooth the world into something humans can understand.
AI systems, by contrast, need to expand context. They require more detail, more nuance, and more surrounding information to reason.
This is where pipelines inevitably diverge.
Analytics pipelines are designed to remove variance, treating it as noise that obscures signal. AI pipelines need variance because edge cases, anomalies, and rare events are often where the most valuable signal lives. Trying to optimise for both in the same system produces failure in both.
Analytics-Ready vs. AI-Ready: Atomic Breakdown
Is it possible to “Upgrade” to AI-Ready Data?
Once the two goals are separated, ordering becomes critical.
You don’t “upgrade” Analytics-ready data into AI-ready data.
That framing assumes they sit on the same path, with one simply being a more advanced version of the other. They don’t.
Analytics-ready data is a by-product of human decision systems. It is shaped after the fact, optimised to explain outcomes, justify choices, and create alignment. AI-ready data, on the other hand, is raw material for reasoning systems. It exists before conclusions are drawn, not after they are summarised.
This is why order matters. First, you capture reality as it is (events, context, intent, and constraints). Then you preserve meaning, resisting the urge to prematurely aggregate or simplify. Only after that do you derive analytics views for human consumption.
Most teams reverse this sequence. They start with dashboards and reports, and then attempt to reverse-engineer intelligence from them. By the time AI enters the picture, the meaning it needs has already been compressed away.
Distinction and Independent Maturity Paths
The real mistake teams make is not just confusing analytics data with AI data. It is assuming they share the same maturity path. Once you accept the distinction, that one explains the past and the other simulates the future, you are forced to accept something more uncomfortable: these are two distinct systems with independent paths to maturity.
Analytics maturity is about interpretability. It evolves toward clearer definitions, stronger governance, better alignment, and organisational trust. AI maturity is about world modelling. It evolves toward richer context, higher signal density, better grounding, and more adaptive behaviour. Converging both, in all honesty, is a highly expensive pursuit: e.g., adding compute-heavy features for analytics data and aggregating AI data.
Progress in one does not imply progress in the other. In fact, over-optimising for one often slows the other down. This is why the language of “data maturity” is misleading. There is no single ladder. There are two orthogonal axes, each with its own constraints, tradeoffs, and failure modes.
Analytics-Ready Data Maturity Path
(Human Decision Systems)
Operational Data: Raw data exists but is fragmented, inconsistent, and difficult to trust. Reporting is reactive and manual.
Standardised Metrics: Core metrics are defined and agreed upon. Dashboards emerge as shared reference points.
Governed Analytics: Definitions are stable, lineage is known, and data can be audited and explained. Trust is institutionalised.
Decision Enablement: Analytics is embedded into workflows. Data supports planning, performance management, and accountability.
Strategic Narrative: Data tells a coherent story of the business over time. The organisation aligns around a shared understanding of “what happened.”
AI-Ready Data Maturity Path
(Machine Reasoning Systems)
Feature Extraction: Data is selectively transformed for models, often stripped of broader context. Results are brittle.
Contextual Enrichment: Events are augmented with surrounding state, metadata, and intent. Models improve but remain fragile.
Semantic Structuring: Meaning is encoded explicitly: relationships, hierarchies, constraints, and definitions are machine-readable.
Grounded Reasoning: Models can trace outputs back to source data. Hallucinations are reduced through grounding and retrieval.
Adaptive World Models: Systems continuously update their understanding of reality, reasoning over change, edge cases, and uncertainty.
Where the Two Paths Intersect and Where They Must Never
There is an intersection between analytics maturity and AI maturity, but it is not convergence. It is coordination. Believing that, at some point, the two paths merge into a single “advanced data platform” is a misstep because they don’t. They remain distinct, even at their most mature.
The intersection exists at the level of shared reality. Both systems depend on accurate events, trustworthy sources, and preserved meaning. But what they do with that reality diverges immediately. Analytics translates reality into explanation. AI translates reality into possibility. When these roles are respected, the systems reinforce each other. When they are collapsed into one, both degrade.
Organisations with strong analytics maturity often assume they are “AI-ready” because their dashboards are trusted and their metrics are governed. Organisations with aggressive AI experimentation often assume analytics will catch up later. Both are wrong in symmetrical ways.
To see this clearly, you have to stop thinking in terms of stages and start thinking in terms of independent axes.
The Analytics × AI Data Maturity Matrix

Important to note:
You don’t move from analytics to AI.
You mature both independently while keeping them aligned.
1. Low Analytics Maturity × Low AI Maturity
The Fog
Data exists, but meaning doesn’t. Reports are inconsistent, models are brittle, and decisions rely more on intuition than evidence. AI experiments feel magical when they work and inexplicable when they don’t. Analytics is reactive while AI is performative. This is where most organisations start and where many end up staying.
2. High Analytics Maturity × Low AI Maturity
The Dashboard Trap
This is the most common and most dangerous quadrant. Dashboards are trusted. Metrics are governed. Executives feel confident. And yet, AI systems underperform or hallucinate.
The organisation has optimised for explaining the past so well that it has compressed away the very context AI needs. Variance is gone. Edge cases are smoothed out. Meaning has been summarised into metrics. AI is then asked to reason over the residue. This is where teams say, “Our data is great, but why doesn’t AI work?”
3. Low Analytics Maturity × High AI Maturity
The Black Box Lab
Here, AI systems appear impressive. Demos work. Prototypes reason well in isolation. But humans don’t trust them. Decisions can’t be defended. Outputs can’t be explained. When something goes wrong, no one knows which number to believe.
AI may simulate the future well, but the organisation can’t explain the present. This creates political resistance greater than technical failures.
4. High Analytics Maturity × High AI Maturity
The Coordinated System
This is the rarely achieved state. Analytics provides stable, trusted narratives about what happened. AI operates on rich, contextual, semantically grounded data to reason about what should happen next. The two systems do not share pipelines, but they share truth.
Humans trust the past while machines reason about the future. And the organisation knows which system to ask which question.
Author Connect 🤝🏻
Discuss shared technologies and ideas by connecting with our Authors or directly dropping us queries on community@moderndata101.com

Find me on LinkedIn 🙌🏻
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Love the breakdown
Love it. Are there any courses you would recommend that explains how to build AI ready data?